
By Boaz Barak and Ben Edelman
[Cross-posted on Lesswrong ; See also Boaz’s posts on longtermism and AGI via scaling , as well as other “philosophizing” posts. This post also puts us in Aaronson’s “Reform AI Alignment” religion]
[Disclaimer: Predictions are very hard, especially about the future. In fact, this is one of the points of this essay. Hence, while for concreteness, we phrase our claims as if we are confident about them, these are not mathematically proven facts. However we do believe that the claims below are more likely to be true than false, and, even more confidently, believe some of the ideas herein are underrated in current discussions around risks from future AI systems.]
In the past, the word “computer” was used to denote a person that performs calculations. Such people were highly skilled and were crucial to scientific enterprises. As described in the book “Hidden Figures”, until the 1960s, NASA still used human computers for the space mission. However, these days a $10 calculator can instantly perform calculations beyond the capabilities of every human on earth.
On a high level, the situation in Chess and other games is similar. Humans used to be the reigning champions in Chess and Go, but have now been surpassed by computers. Yet, while the success of computers in performing calculations has not engendered fears of them “taking over the world,” the growing powers of AI systems have more people increasingly worried about their long-term implications. Some reasons why the success of AI systems such as AlphaZero in Go and Chess is more concerning than the success of calculation programs include
- Unlike when working with numerical computation programs, it seems that in Chess and Go humans are entirely “unnecessary.” There is no need to have a “human in the loop”. Computer systems are so powerful that no meaningful competition is possible between even the best human players and software running on commodity laptops.[1]
- Unlike the numerical algorithms used for calculations, we do not understand the inner workings of AI chess systems, especially ones trained without any hand-designed knowledge. These systems are to a large extent “black boxes,” which even their creators do not fully understand and hence cannot fully predict or control.
- Moreover, AlphaZero was trained using a paradigm known as reinforcement learning or RL (see also this book). At a high level, RL can be described as training an agent to learn a strategy (i.e., a rule to decide on a move or action based on the history of all prior ones) in order to maximize a long-term reward (e.g., “win the game”). The result is a system that is capable of executing actions that may seem wrong in the short term (e.g., sacrificing a queen) but will help achieve the long-term goal.
While RL so far has had very limited success outside specific realms such as games or low-complexity settings, the success of (non-RL) deep learning systems such as GPT-3 or Dall-E in open-ended text or image generation has raised fears of future AI systems that could both act in the real world, interacting with humans, physical, and digital systems, and do so in the pursuit of long term goals that may not be “aligned” with the interests of humanity. The fear is that such systems could become so powerful that they could end up destroying much or all of humanity. We refer to the above scenario as the loss of control scenario. It is distinct from other potential risks of Artificial Intelligence, including the risks of AI being used by humans to develop more lethal weapons, better ways for repressive regimes to surveil their population or more effective ways of spreading misinformation.
In this essay, we claim that the “loss of control” scenario rests on a few key assumptions that are not justified by our current understanding of artificial intelligence research. (This doesn’t mean the assumptions are necessarily wrong—just that we don’t believe the preponderance of the evidence supports them.) To be clear, we are not “AI skeptics” by any means. We fully believe that over the next few decades, AI will continue to make breakthrough advances, and AI systems will surpass current human performance in many creative and technical fields, including, but not limited to, software engineering, hacking, marketing, visual design, (at least some components of) scientific discovery, and more. We are also not “techno-optimists.” The world already faces risks, and even existential ones, from the actions of humans. People who have had control over nuclear weapons over the course of history include Joseph Stalin, Kim Jong-un, Vladimir Putin, and many others whose moral judgment is suspect, to say the least. Nuclear weapons are not the only way humans can and have caused suffering on a mass scale; whether it is biological, chemical, or even so-called “conventional” weapons, climate change, exploitation of resources and people, or others, humans have a long history of pain and destruction. Like any new technology, AI will be (and in fact already has been) used by humans for warfare, manipulations, and other illicit goals. These risks are real and should be studied, but are not the focus of this essay.
Our argument: an executive summary.
The loss of control scenario is typically described as a “battle” between AIs and humans, in which AIs would eventually win due to their superior abilities. However, unlike in Chess games, humans can and will use all the tools at their disposal, including many tools (e.g., code-completion engines, optimizers for protein folding, etc..) that are currently classified as “Artificial Intelligence”. So to understand the balance of power, we need to distinguish between systems or agents that have only short-term goals, versus systems that plan their own long-term strategies.
The distinction above applies not just to artificial systems but also to human occupations as well. As an example, software developers, architects, engineers, or artists have short-term goals, in the sense that they provide some particular product (piece of software, design for a bridge, artwork, scientific paper) that can stand and be evaluated on its own merits. In contrast, leaders of companies and countries set long-term goals in the sense that they need to come up with a strategy that will yield benefits in the long run and cannot be assessed with confidence until it is implemented.[2]
We already have at least partial “short-term AI”, even if not at the level of replacing e.g., human software engineers. The existence of successful “long-term AI” that can come up with strategies which are enacted over a scale of, say, years is still an open question, but for the sake of this essay we accept that assumption.
We believe that when evaluating the loss-of-control scenario, the relevant competition is not between humans and AI systems, but rather between humans aided with short-term AI systems and long-term AI systems (themselves possibly aided with short-term components). One thought experiment we have in mind is a competition between two firms: one with a human CEO, but with AI engineers and advisors, and the other a fully AI firm.
While it might seem “obvious” that eventually AI would be far superior to humans in all endeavors, including being a CEO, we argue that this is not so obviously the case. We agree that future AIs could possess superior information processing and cognitive skills – a.k.a. “intelligence” – compared to humans. But the evidence so far suggests the advantages of these skills would be much more significant in some fields than in others. We believe that this is uncontroversial – for example, it’s not far-fetched to claim that AI would make much better chess players than kindergarten teachers. Specifically, there are “diminishing returns” for superior information-processing capabilities in the context of setting longer-term goals or strategies. The long time horizon and the relevance of interactions among high numbers of agents (who are themselves often difficult to predict) make real-life large-scale systems “chaotic” in the sense that even with superior analytic abilities, they are still unpredictable (see Figure 1).
As a consequence, we believe the main fields where AI systems will yield advantages will be in short-term domains. An AI engineer will be much more useful than an AI CEO (see also Table 2). We do not claim that it would be impossible to build an AI system that can conceive and execute long-term plans; only that this would not be where AI would have a “competitive advantage”. Short-term goals that can be evaluated and graded also mesh much better with the current paradigm of training AI systems on vast amounts of data.
We believe it will be possible to construct very useful AIs with only short-term goals, and in fact that the vast majority of AI’s power will come from such short-term systems. Even if a long-term AI system is built, it will likely not have a significant advantage over humans assisted with short-term AIs. There can be many risks even from short-term AI systems, but such machines cannot by design have any long-term goals, including the goal of taking over the world and killing all humans.[3]
Perspective. Our analysis also has a lesson for AI safety research. Traditionally, approaches to mitigate the behavior of bad actors include
- Prevention: We prevent break-ins by putting locks on our doors, we prevent hacks by securing our systems, etc…
- Deterrence: Another way we prevent bad actions is by ensuring that the negative consequences for these actions will outweigh benefits. This is one basis for the penal system, as well as the “mutually assured destruction” paradigm that has kept Russia and US from a nuclear war.
- Alignment: We try to educate children and adults and socialize them to our values, so they are not motivated to pursue the actions we consider as bad.
Much of AI safety research (wrt to the “loss of control” scenario) has been focused on the third approach, with the expectation that these systems may be so powerful that prevention and deterrence will be impossible. However, it is unclear to us that this will be the case. For example, it may well be that humans, aided by short-term AI systems, could vastly expand the scope of formally verified secure systems, and so prevent hacking attacks against sensitive resources. A huge advantage of research on prevention is that it is highly relevant not just to protect against hypothetical future bad AI actors, but also against current malicious humans. Such research might greatly benefit from advances in AI code-completion engines and other tools, hence belying the notion that there is a “zero-sum game” between “AI safety” and “AI capabilities” research.
Furthermore, one advantage of studying AI systems, as opposed to other organisms, is that we can try to extract useful modules and representations for them. (Indeed, this is already done in “transfer learning.”) Hence, it may be possible to extract useful and beneficial “short-term AI” even from long-term systems. Such restricted systems would still give most of the utility, but with less risk. Once again, increasing the capabilities of short-term AI systems will empower humans that are assisted by such systems.
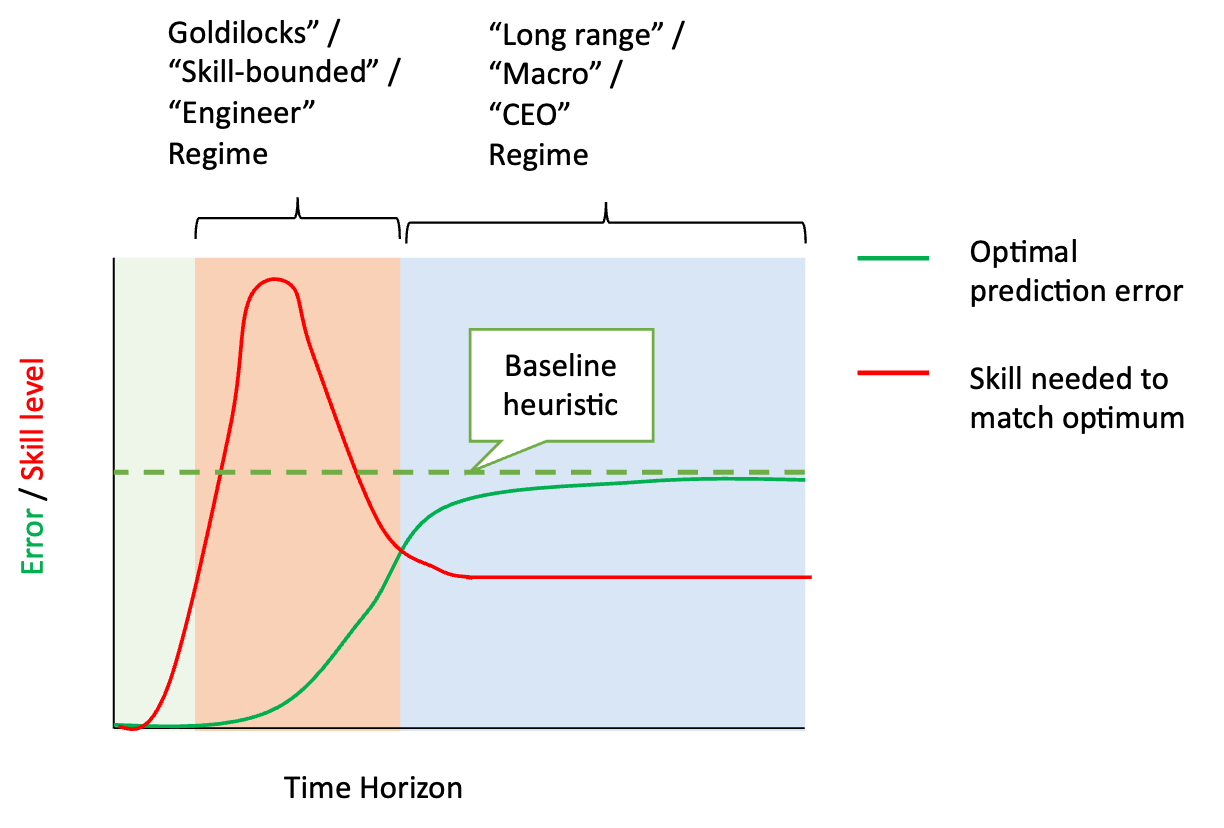
Figure 1: Cartoon of the feasibility of predicting future events and the level of ability (i.e., cognitive skill / compute / data) required to do so (approximately) optimally. As the horizon grows, events have more inherent uncertainty and also require more skills/data to predict. However, many realistic systems are chaotic and become unpredictable at some finite horizon.[4] At that point, even sophisticated agents cannot predict better than baseline heuristics, which require only a bounded level of skill.
| Profession | Cognitive Score (standard deviations) | Annual Earnings |
| Mayors | 6.2 ( ≈ +0.6σ ) | 679K SEK |
| Parliamentarians | 6.4 ( ≈ +0.7σ ) | 802K SEK |
| CEOs (10-24 employees) | 5.8 ( ≈ +0.4σ ) | 675K SEK |
| CEOs (25-249 employees) | 6.2 ( ≈ +0.6σ ) | 1,046K SEK |
| CEOs (≥ 250 employees) | 6.7 ( ≈ +0.85σ ) | 1,926K SEK |
| Medical Doctors | 7.4 ( ≈ +1.2σ ) | 640K SEK |
| Lawyers and Judges | 6.8 ( ≈ +0.9σ ) | 568K SEK |
| Economists | 7 ( ≈ +1σ ) | 530K SEK |
| Political Scientists | 6.8 ( ≈ +0.9σ ) | 513 SEK |
Table 2: Cognitive scores for Swedish men in various “elite” occupations, based on Swedish army entrance examinations, taken from Dal Bó et al (Table II). Emphases ours: bold text corresponds to jobs that (in our view) require longer horizon decision-making across time or number of people. Note that despite being apparently less cognitively demanding, the “bold” professions are higher paying.
A digression: what is intelligence
Merriam-Webster defines intelligence as “the skilled use of reason”, “the ability to learn or understand or to deal with new or trying situations”, or “to apply knowledge to manipulate one’s environment or to think abstractly.” Intelligence is similar to computation, in the sense that its main components are the ability to take in observations (aka “inputs”) and use reasoning (aka “algorithms”) to decide on actions (aka “outputs”). In fact, in the currently dominant paradigm of AI, performance is primarily determined by the amount of computation performed during learning, and AI systems consist of enormous homogeneous circuits executing a series of simple operations on (a large quantity of) inputs and learned knowledge. Bostrom (Chapter 3) defines three forms of “superintelligence”: “speed superintelligence”, “collective superintelligence” and “quality superintelligence”. In the language of computing, speed super-intelligence corresponds to clock speed of processors, while collective super-intelligence corresponds to massive parallelism. “Quality superintelligence” is not well defined, but is presumably some type of emergent phenomenon from passing some thresholds of speed and parallelism.
A fundamental phenomenon in computing is universality: there are many restricted computational models (finite state automata, context-free grammars, simply-typed lambda calculus), but once a computational model passes a certain threshold or phase transition, it becomes universal (a.k.a. “Turing complete”), and all universal models are equivalent to one another in computational power. For example, in a cellular automata, even though each cell is very restricted (can only store a constant amount of memory and process a finite rule based only on the state of its immediate neighbors), given enough cells we can simulate any arbitrarily complex machine.[5] Once a system passes the universality transition, it is not bottlenecked any more by the complexity of an individual unit, but rather by the resources in the system as a whole.
In the animal kingdom, we seem to have undergone a similar phase transition, whereby humans are qualitatively more intelligent than any other animal or creature. It also seems to be the case that with the invention of language, the printing press, and the Internet, we (like cellular automata) are able to combine large numbers of humans to achieve feats of collective intelligence that are beyond any one individual. In particular, the fruits of the scientific revolution of the 1500-1600s increased the scale of GDP by 10,000-fold (to the extent such comparisons are meaningful) and the distance we can measure in space a trillion-fold, all with the same brains used by our hunter-gatherer ancestors (or maybe somewhat smaller ones).
Arguably, the fact humans are far better than chimpanzees at culturally transmitting knowledge is more significant than the gap in intelligence between individuals of the two species. Ever since the development of language, the intelligence of an individual human has not been a bottleneck for the achievements of humanity. The brilliance of individuals like Newton may have been crucial for speeding up the Scientific Revolution, but there have been brilliant individuals for millennia. The crucial difference between Newton and Archimedes is not that Newton was smarter, but rather that he lived at a later time and thus was able to stand on the shoulders of more giants. As another example, a collection of humans, aided by Internet-connected computers, can do much better at pretty much any intelligence feat (including but not limited to IQ exams) than any single human.
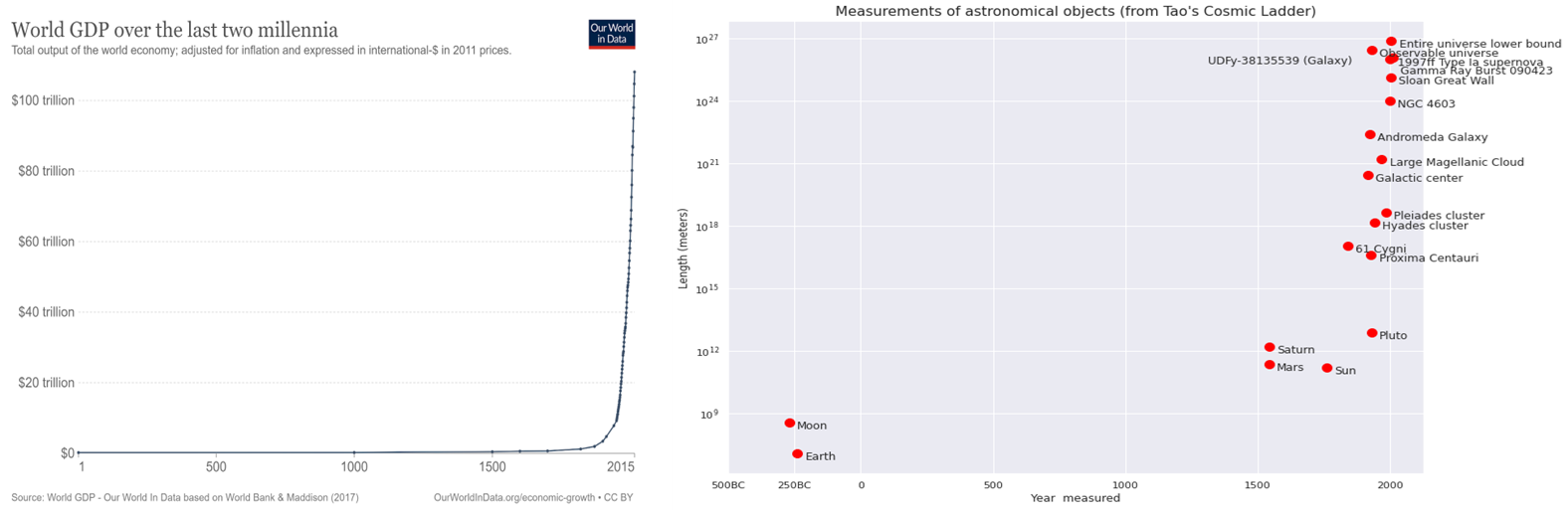
Figure 3: Measures of human progress both in terms of GDP and the scale of objects we can measure. Taken from this blog post, with the first figure from Our World in Data, and data for second figure from Terence Tao’s cosmic ladder presentation.
The “loss of control” scenario posits a second phase transition, whereby once AI systems become more powerful, they would not merely enable humans to achieve more objectives quicker but would themselves become as qualitatively superior to humans as humans are to other animals. We are suggesting an alternative future scenario, in which while AI would provide powerful new capabilities to human society that can (and unfortunately likely will) be used for ill as well as good, the AI systems themselves would not be the inevitable leaders of this society.
Indeed, our societies and firms do not currently select our leaders to be the top individuals in intellectual capacity. The evidence is very limited that “natural talent for leadership” (to the extent it exists) is as measurable and transferable as talent for chess, math, or athletics. There are many examples of leaders who have been extremely successful in one setting but failed in another which seems rather similar.[6]
Whether or not an AI system should be considered an “individual” is a matter for debate, but regardless, it is not at all clear that such individuals would be the leaders of the society, rather than being employed in domains such as software development and scientific discovery, where their superior information-processing capabilities would provide the most competitive advantage. Bostrom (Table 8 in Chapter 6) lists several potential “cognitive superpowers” that an AI system might develop. One category is “hacking”, “technology research”, and “economic productivity”. These are skills that correspond to jobs that are not in the domain of CEOs or leaders, but rather engineers, middle managers, scientists, etc. AI systems may well be able to assist or even replace such individuals, but this does not mean such systems will be the leaders of companies or countries.
Another task Bostrom considers is “intelligence amplification” which is the ability to improve AI systems. Again, it is quite possible that AI systems would help in improving other or the same AI systems, but this on its own does not imply that they would become infinitely powerful. Specifically, if indeed stronger AI would arrive through “scaling” of massive computational resources, then there would be some hard limits on the ability to improve AI’s power solely through software updates. It is not at all clear that in terms of energy efficiency, AI systems would be much better (if at all) than humans. If the gains from scaling are far more important than gains from improved algorithms/architectures, then intelligence amplification might be primarily a function of resource acquisition rather than algorithmic research.
A third task listed is “social manipulation.” Here we must admit we are skeptical. Anyone who has ever tried to convince a dog to part with a bone or a child with a toy could attest to the diminishing returns that an intelligence advantage has in such a situation.
Finally, Boston lists the cognitive superpower of “strategizing”, which is the ability to make long-term plans to achieve distant goals. This is the point we focus on in this essay. In short, our belief is that the chaotic nature of the real world implies diminishing returns to “three-dimensional chess” strategies that are beyond the comprehension of mere humans. Hence we do not believe that this would be a domain where AI systems have a strong competitive advantage.
A thought experiment: “The AI CEO vs. the AI advisor”
Before we delve into the technical(-ish) analysis, let us consider a thought experiment. At its heart, our argument is that the power of AI systems, present and future, will not come from the ability to make long-term strategic plans (“three-dimensional chess”) but rather from the ability to produce pieces of work that can be evaluated on their own terms. In short, we believe that even if a long-term malicious AI system is constructed, it will not have an insurmountable advantage over humans that are assisted with short-term AIs. To examine this, let us imagine two possible scenarios for how future AI could assist humans in making strategic decisions, such as running a company:
- In the “AI Advisor” model, leaders could use AI to come up with simulations of the impact of decisions and possibly make some suggestions. However, humans would ultimately make the decision and evaluate their results. Key for this is that an AI would be able not just to produce a recommendation for a decision but explain how this decision would lead to improvement in some interpretable metric (e.g., revenue, market share, etc..). For example, a decision might be “let’s sell this product at a loss so we can increase our market share.”
- In the “AI CEO” model, AIs could use their superior powers to choose an optimal long-term strategy as opposed to an individual decision. The strategy would not be “greedy”, in the sense of a sequence of steps each making progress on measurable goals, and it would not have any compact analysis of why it is good. Also, the only way to accrue the benefits of the strategy would be to continue pursuing it in the long term. Hence users would have to trust the AI and follow its recommendations blindly. For example, think of the case in Chess where an AI figures out that the best move is to sacrifice the queen because for any one of the possible opponent’s moves, there is a countermove, and so on and so forth. The only explanation for why this strategy is a good one may consist of an exponentially big game tree up to a certain depth.
Our sense is that there is strong evidence that AI would be incredibly useful for making low-level decisions (i.e., optimizing objectives under constraints) once the high-level strategy was set. Indeed, by far the most exciting advances for deep learning have not been through reinforcement learning, but rather through techniques such as supervised and unsupervised learning. (With the major exception being games like Chess and Go, though even there, given the success of non-RL engines such as Stockfish versions 12 and later, it is not clear RL is needed.) There is less evidence that “AI advisors” would be useful for setting high-level strategies, but it is certainly plausible. In particular, the power of prompt-based generative models suggests that AI could be useful for generating realistic simulations that can help better convey the impact of various decisions and events. So, while “AI engineers” might be more useful than “AI advisors”, the latter might well have their role as well.
In contrast, we believe that there is little to no evidence for the benefits of “three-dimensional chess” strategies of the type required for the “AI CEO” scenario. The real world (unlike the game of chess or even poker), involves a significant amount of unpredictability and chaos, which makes highly elaborate strategies depending on complex branching trees of moves and counter-moves far less useful. We also find it unlikely that savvy corporate boards would place blind trust in an AI CEO given that (as mentioned above) evaluation of even human CEOs tends to be controversial.
There is an alternative viewpoint, which is that an AI CEO would basically be equivalent to a human CEO but with superhuman “intuition” or “gut feeling” that they cannot explain but somehow leads to decisions that yield enormous benefits in the long term. While this viewpoint cannot be ruled out, there is no evidence in current deep learning successes to support it. Moreover, often great CEO’s “gut feelings” are less about particular decisions, but more about the relative importance of particular metrics (e.g., prioritizing market share or user experience over short-term profits).
In any case, even if one does not agree with our judgment of the relative likelihoods of the above scenarios, we hope that this essay will help sharpen the questions that need to be studied, as well as what lessons can we draw about them from the progress so far of AI systems.
Technical Analysis
1. Key hypotheses behind the “Loss of Control” Scenario
For the sake of the discussion below, let’s assume that at some future time there exists an artificial intelligence system that in a unified way achieves performance far superior to that achieved by all humans today across many fields. This is a necessary assumption for the “loss of control” scenario and an assumption we accept in this essay. For the sake of simplicity, below we refer to such AI systems as “powerful”.
We will also assume that powerful AI will be constructed following the general paradigm that has been so successful in the last decade of machine learning. Specifically, the system will be obtained by going through a large amount of data and computational steps to find some instantiation (a.k.a. “parameters” or “weights”) of it that optimizes some chosen objective. Depending on the choice of the objective, this paradigm includes supervised learning (“classify this image”), unsupervised learning (“predict the next token”), reinforcement learning (“win the game”), and more.
For the loss of control scenario to occur, the following two hypotheses must be true:
Loss-of-Control Hypothesis 1: There will exist a powerful AI that has long-term goals.
For an AI to have misaligned long-term goals, it needs to have some long-term goals in the first place. There is a question of how to define the “goals” of an AI system or even a human for that matter. In this essay, we say that an agent has a goal X if, looking retrospectively at the history of the agent’s actions, the most parsimonious explanation for its actions was that it was attempting to achieve X, subject to other constraints or objectives. For example, while chess experts often find it hard to understand why an engine such as AlphaZero makes a specific move, by the end of the game, they often understand the reasoning retrospectively and the sub-goals it was pursuing.
In our parlance, a goal is “long-term” if it has a similar horizon to goals such as “take over the world and kill all the humans” —requiring planning over large scales of time, complexity, and number of agents involved.[7]
In contrast, we consider goals such as “win a chess game”, “come up with a plan for a bridge that minimizes cost and can carry X traffic”, or “write a piece of software that meets the requirements Y”, as short-term goals. As another example, “come up with a mix of stocks to invest today that will maximize return next week” is a short-term goal, while “come up with a strategy for our company that will maximize our market cap over the next decade” or “come up with a strategy for our country that will maximize our GDP for the next generation” would be long-term goals. The distinction between “short-term goals AI” and “long-term goals AI” is somewhat similar to the distinction between “Tool AI” and “Agent AI” (see here). However, what we call “short-term AI” encompasses much more than “Tool AI”, and absolutely includes systems that can take actions such as driving cars, executing trading actions, and so on and so forth.
We claim that for the “loss of control” scenario to materialize, we need not only Hypothesis 1 but also the following stronger hypothesis:
Loss-of-Control Hypothesis 2: In several key domains, only AIs with long-term goals will be powerful.
By this, we mean that AIs with long-term goals would completely dominate other AIs, in that they would be much more useful for any user (or for furthering their own goals). In particular, a country, company or organization that restricts itself to only using AIs with short term goals would be at a severe competitive disadvantage compared to one that uses AIs with long-term goals.
Why is Hypothesis 2 necessary for the “loss of control” scenario? The reason is that this scenario requires the “misaligned long-term powerful AI” to be not merely more powerful than humanity as it exists today, but more powerful than humanity in the future. Future humans will have at their disposal the assistance of short-term AIs.
2. Understanding the validity of the hypotheses
We now make the following claims, which we believe cast significant doubt on Hypothesis 2.
Claim 1: There are diminishing returns to information-processing skills with longer horizons.
Consider the task of predicting the consequences of a particular action in the future. In any sufficiently complex real-life scenario, the further away we attempt to predict, the more there is inherent uncertainty. For example, we can use advanced methods to predict the weather over a short time frame, but the further away the prediction, the more the system “regresses to the mean”, and the less advantage that highly complex models have over simpler ones (see Figure 4). As in meteorology, this story seems to play out similarly in macroeconomic forecasting. In general, we expect prediction success to behave like Figure 1 below—the error increases with the horizon until it plateaus to a baseline level of some simple heuristic(s). Hence while initially highly sophisticated models can beat simpler ones by a wide margin, this advantage eventually diminishes with the time horizon.
Tetlock’s first commandment to potential superforecasters is to triage: “Don’t waste time either on “clocklike” questions (where simple rules of thumb can get you close to the right answer) or on impenetrable “cloud-like” questions (where even fancy statistical models can’t beat the dart-throwing chimp). Concentrate on questions in the Goldilocks zone of difficulty, where effort pays off the most.” Another way to say it is that outside of the Goldilocks zone, more effort or cognitive power does not give much returns.
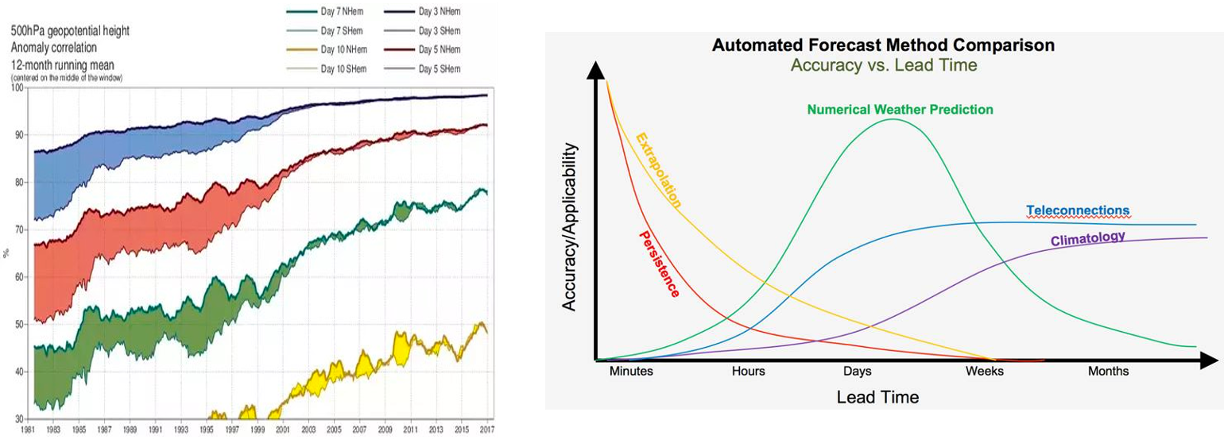
Figure 4: Left: Historical weather prediction accuracy data taken from a Quora answer of Mikko Strahlendorff. With technological advances, accuracy has improved significantly, but prediction accuracy sharply decays with time. Right: Figure on relative applicability of different methods from Brent Shaw. Computationally intensive numerical prediction applies in a “goldilocks zone” of days to weeks.
In a variety of human endeavors, it seems that the cognitive skills needed to make decisions display a similar phenomenon. Occupations involving making decisions on the mid-range horizon, such as engineering, law, and medicine, require higher cognitive skills than those requiring long-term decisions such as CEOs or Politicians (see Table 3).
One argument people make is that intelligence is not just about IQ or “booksmarts”. We do not dispute this. However, we do believe that the key potential advantage of AI systems over their human counterparts would be the ability to quickly process large amounts of information, which in humans is approximated by scores such as IQ. If that skill were key to successful leadership of companies or countries, then we would expect CEOs and leaders to come from the top 0.1% (≈ +3σ) of the distribution of such scores. The data does not bear this out.[8]
Claim 2: It may be possible to extract powerful short-term modules from long-term systems.
For Hypothesis 2 to be true, it should not be possible to take a powerful AI system with long-term goals, and extract from it modules that would be just as powerful in the key domains, but would have short-term goals. However, a nascent body of work identifies and extracts useful representations and sub-modules in deep neural networks. See, for example, this recent investigation of AlphaZero. We remark that some components of AlphaZero also inspired advances to the Stockfish Chess Engine (which is not trained using RL and involves a lot of hand-coded features), and whose latest version does in fact beat RL trained methods a-la AlphaZero.
A related issue is that a consistent theme of theoretical computer science is that verification is easier than solving or proving. Hence even a complex system could explain its reasoning to a simple verifier, even if that reasoning required a significant effort to discover. There are similar examples in human affairs: e.g., even though the discovery of quantum mechanics took thousands of years and multiple scientific revolutions, we can still teach it to undergraduates today whose brains are no better than those of the ancient Greeks.
2.1 The impact of the deep learning paradigm on Hypothesis 2
The following claims have to do with the way we believe advanced AI systems will be constructed. We believe it is fair to assume that the paradigm of using massive data and computation to create such systems, by optimizing with respect to a certain objective, will continue to be used. Indeed, it is the success of this paradigm that has caused the rise in concerns about AI in the first place. In particular, we want to make a clear distinction between the training objective, which the system is designed to optimize, versus the goals that the system appears to follow during its deployment.
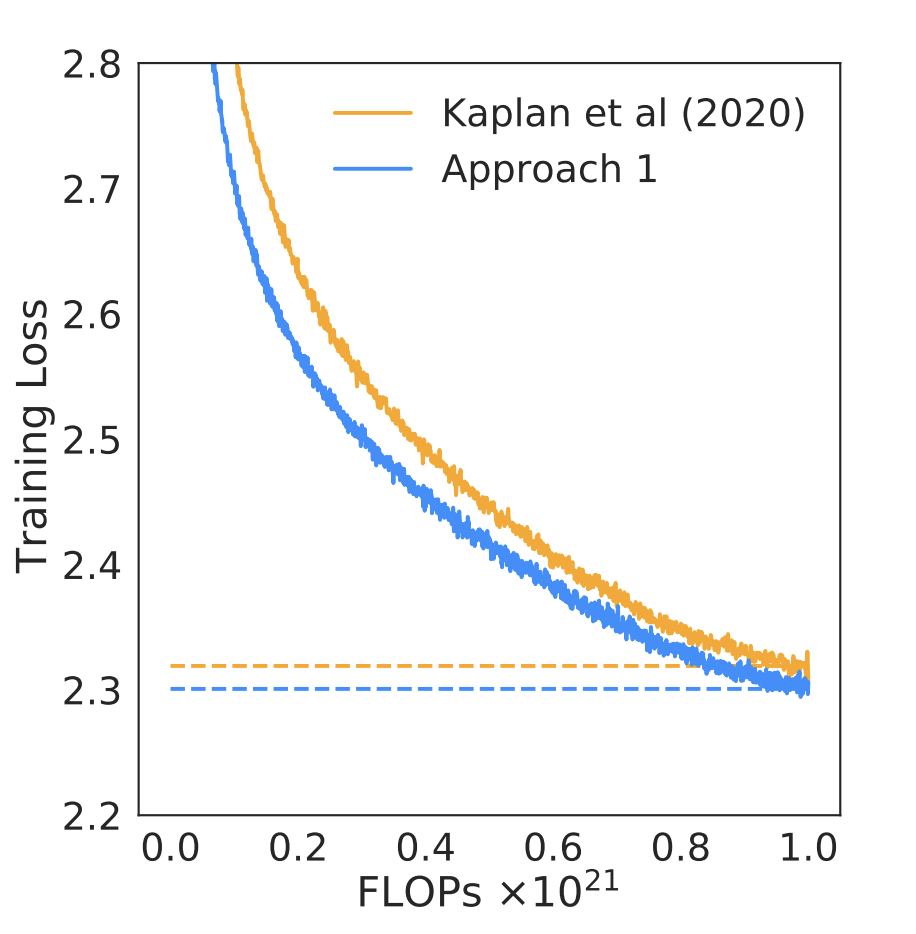
Claim 3: There may be fundamental “scaling laws” governing the amount of performance AI systems can achieve as a function of the data and computational resources.
One of the original worries in the AI risk literature is the “singularity” scenario, by which an AI system continuously improves its own performance without limit. However, this assumes that a system can improve itself by rewriting its code, without requiring additional hardware resources. If there are hard limits to what can be achieved with a certain level of resources, then such self-improvements will also hit diminishing returns. There has been significant evidence for the “scaling laws” hypothesis in recent years.
Figure 5: Scaling laws as computed by Hoffman et al (“Chinchilla”), see Figure A4 there. While the scaling laws are shaped differently from those of Kaplan et al, the qualitative point we make remains the same.
Claim 4: When training with reinforcement learning, the gradient signal may decrease exponentially with the length of the horizon.
Consider training a system that chooses a sequence of actions, and only gets a reward after H steps (where H is known as the “horizon”). If at any step there is some probability of an action leading to a “dead end” then the chances of getting a meaningful signal decrease exponentially with H. This is a fundamental obstacle to reinforcement learning and its applicability in open-ended situations with a very large space of actions, and a non-trivial cost for any interaction. In particular, one reason AlphaZero was successful was that in games such as chess, the space of legal moves is very constrained, and in the artificial context of a game it is possible to “reset” to a particular position: that is, one can try out different actions and see what their consequences are, and then go back to the same position. This is not possible when interacting in the real world.
As a corollary of Claim 4, we claim the following:
Claim 5: There will be powerful AI systems that are trained with short-term objective functions.
By this, we mean models that are trained on a reward/loss function that only depends on a relatively short span of actions/outputs. A canonical example of this is next-token prediction. That is, even if the eventual deployment of the model will involve it making actions and decisions over a long time horizon, its training will involve optimizing short-term rewards.
One might think that the model’s training does not matter as much, since once it is deployed in the real world, much of what it will learn will be “on the job”. However, this is not at all clear. Suppose the average worker reads/hears about 10 pages per day, which is roughly 5K tokens, leading to roughly 2M tokens per year. In contrast, future AIs will likely be trained on a trillion tokens or so, corresponding to the amount a worker will see in 5 million years! This means that while “fine-tuning” or “in context” learning can and will occur, many of the fundamental capabilities of the systems will be fixed at the time of training (as appears to be the case for pre-trained language models that are fine-tuned with human feedback).
Claim 6: For a long-term goal to necessarily emerge from a system trained with a short-term objective, it must be correlated or causally related to that objective.
If we assume that powerful AIs will be trained with short-term objectives, then Hypothesis 2 requires that (in several key domains) every such system will develop long-term goals. In fact, for the loss-of-control scenario to hold, every such system should develop more-or-less the same sort of goal (e.g., “take over the world”).
While it is certainly possible for systems that evolve from simple rules to develop complex behavior (e.g., cellular automata), for a long-term goal to consistently emerge from mere short-term training, there should be some causal relation (or at least persistent correlation) between the long-term goal and the short-term training objective. This is because an AI system can be modeled as a maximizer of the objective on which it was trained. Thus for such a system to always pursue a particular long-term goal, that goal should be correlated with maximizing the training objective.
We illustrate this with an example. Consider an AI software developer which is trained to receive a specification of a software task (say, given by some unit tests) and then come up with a module implementing it, obtaining a reward if the module passes the tests. Now suppose that in actual deployment, the system is also writing the tests that would be used to check its future outputs. We might worry that the system would develop a “long-term” goal to maximize total reward by writing one faulty test, taking the “hit” on it, and receiving a low reward, but then getting high rewards on future tasks. However, that worry would be unfounded, since the AI software developer system is trained to maximize the reward for each task separately, as opposed to maximizing the sum of rewards over time over adaptively chosen inputs of its own making.
Indeed, this situation can already happen today. Next-token prediction models such as GPT-3 are trained on the reward of the perplexity over a single token, but when they are deployed, we typically generate a long sequence of tokens. Now consider a model that simply outputs an endless repetition of the word “blah”. The first few repetitions would get very low rewards, since they are completely unexpected, but once n is large enough (e.g. 10 or so), if you’ve already seen n “blah”s then the probability that the n+1 st word is also “blah” is very high. So if the model were to be maximizing total reward, it may well be worth “taking the hit” by outputting a few blahs. The key point is that GPT-3 does not do that. Since it is trained on predicting the next token for human-generated (as opposed to the text generated by itself), it will optimize for this short-term objective rather than the long-term one.
We believe the example above generalizes to many other cases. An AI system trained in the current paradigm is, by default, a maximizer of the objective it was trained on, rather than an autonomous agent that pursues goals of its own design. The shorter the horizon and more well-defined the objective is, the less likely that optimizing it will lead to systems that appear to take elaborate plans to pursue far-reaching (good or bad) long-term goals.
Summary
Given the above, we believe that while AI will continue to yield breakthroughs in many areas of human endeavor, we will not see a unitary nigh-omnipotent AI system that acts autonomously to pursue long-term goals. Concretely, even if a successful long-term AI system could be constructed, we believe that this is not a domain where AI will have a significant “competitive advantage” over humans.
Rather, based on what we know, it is likely that AI systems will have a “sweet spot” of a not-too-long horizon in which they can provide significant benefits. For strategic and long-term decisions that are far beyond this sweet spot, the superior information processing skills of AIs will give diminishing returns. (Although AIs will likely supply valuable input and analysis to the decision makers.). An AI engineer may well dominate a human engineer (or at least one that is not aided by AI tools), but an AI CEO’s advantage will be much more muted, if any, over its human counterpart. Like our world, such a world will still involve much conflict and competition, with all sides aided by advanced technology, but without one system that dominates all others.
If our analysis holds, then it also suggests different approaches to mitigating AI risk than have been considered in the “AI safety” community. Currently, the prevailing wisdom in that community is that AI systems with long-term goals are a given, and hence the approach to mitigate their risk is to “align” these goals with human values. However, perhaps more evidence should be placed on building just-as-powerful AI systems that are restricted to short time horizons. Such systems could also be used to monitor and control other AIs, whether autonomous or directed by humans. This includes monitoring and hardening systems against hacking, detecting misinformation, and more. Regardless, we believe that more research needs to be done on understanding the internal representations of deep learning systems, and what features and strategies emerge from the training process (so we are happy that the AI safety community is putting increasing resources into “interpretability” research). There is some evidence that the same internal representations emerge regardless of the choices made in training.
There are also some technical research directions that would affect whether our argument is correct. For instance, we are interested in seeing work on the impacts of noise and unpredictability on the performance of reinforcement learning algorithms; in particular, on the relative performance of models of varying complexity (i.e. scaling laws for RL).
Acknowledgments: Thanks to Yafah Edelman for comments on an earlier version of this essay.
Footnotes
- During the 90s-2000s, human-engine teams were able to consistently beat engines in “advanced chess” tournaments, but no major advanced chess tournament seems to have taken place since the release of AlphaZero and the resulting jump in engine strength, presumably because the human half of each team would be superfluous.
- The success of a bridge does hinge on its long-term stability, but stability can be tested before the bridge is built, and coming up with measures for load-bearing and other desiderata is standard practice in the engineering profession. An AI trained using such a short-term evaluation suite as its reward function may still “overoptimize” against the metric, a la Goodhart’s Law, but this can likely be addressed with regularization techniques.
- It may be the case that, for subtle reasons, if we try to train an AI with only short-term goals—e.g. by training in a series of short episodes—we could accidentally end up with an AI that has long-term goals. See Claim 6 below. But avoiding this pitfall seems like an easier problem than “aligning” the goals of an AI that is explicitly meant to care about the long-term.
- We don’t mean that they satisfy all the formal requirements to be defined as a chaotic system; though sensitivity to initial conditions is crucial.
- For a nice illustration, see Sam Trajtenberg’s construction of Minecraft in Minecraft, or this construction of Life in Life.
- Steve Jobs at Apple vs NeXT is one such example; success and failure can themselves be difficult to distinguish even with the benefit of hindsight, as in the case of Jack Welch.
- For example, such planning might require setting up many companies to earn large amounts of funds, conducting successful political campaigns in several countries, constructing laboratories without being detected, etc. Some such “take-over scenarios” are listed by Bostrom, as well as Yudkowski and Urban.
- It is hypothetically possible that companies would be better off en masse if they hired smarter CEOs than they currently do, but given the high compensation CEOs receive this doesn’t seem like a particularly plausible equilibrium.

The title is a little misleading. An AI system has only to find ONE instance of “3d chess” with significant advantage over humans. The burden, therefore, is on the writers to argue why EVERY possible “3d chess” instance would not yield any significant advantage for AIs. The given arguments, however, are more heuristic and out of sync with the conclusiveness projected by the title…..appreciate your efforts nevertheless, a good read, thanks!
I am very surprised that you, a scientist, would say that engineers and scientists pursue short term goals, such as a design or a paper, while CEOs and government pursue a higher level of long term goal. Long term programs are incredibly important in science; as an example, Hamilton had a vision, or an outline, of how one might prove the 3 dimensional Poincare conjecture, but it was not at all obvious it would be useful until Perelman made it into a proof. One could go on and on. Or, consider a software engineer: early on in the design process, it is helpful if they have long term plan so that they can correctly architect the program and this can distinguish a good engineer from a great one. I’d say right now that a lot of companies are more focused on the short term goal of “do well next quarter” and a lot of politicians focused on the goal of “get re-elected”.