
One of the lessons we have seen in language modeling is the power of scale. The original GPT paper of Radford et al. noted that at some point during training, the model “acquired” the ability to do sentiment analysis of a sentence X by predicting whether it is more likely to be followed by “very negative” or “very positive.” As they trained the model, at some point, the zero-shot performance “jumped” significantly. Of course, as Radford et al. noted, their approach required “an expensive pre-training step—1 month on 8 GPUs.” 😊
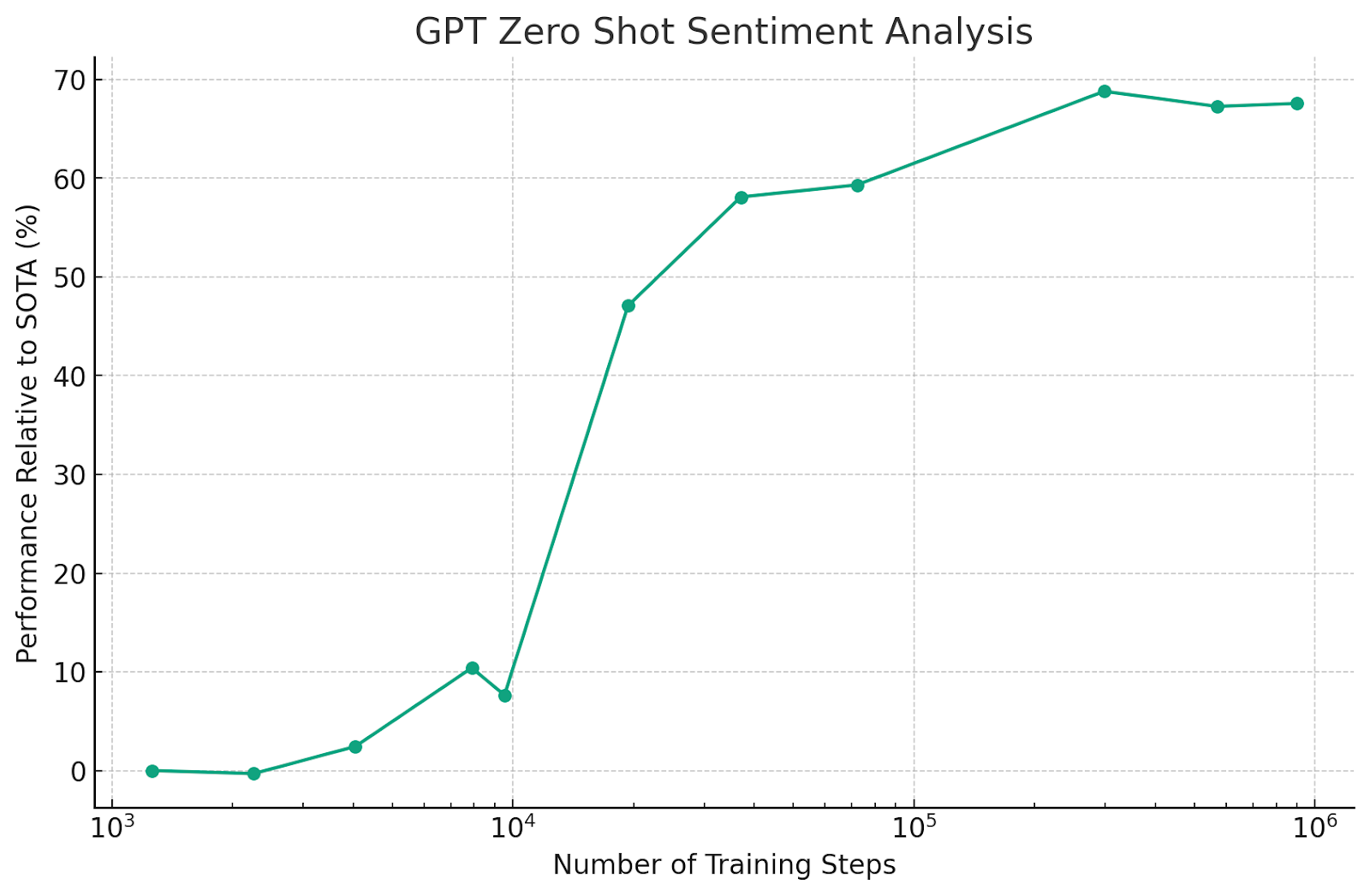
The GPT-2 paper showed the benefits of scale. As they say, GPT-2 was a scaled-up version of GPT with about ten times the parameters and ten times the data. This scaling up led to qualitatively new capabilities. In particular, not just better “zero-shot” performance but also the ability to generate long coherent texts (see below). And, of course, GPT-3 and GPT-4 showed even more the benefits of scale.

Wei et al. showed that such “emergent capabilities at scale” are common. The form of such “emergent capabilities” is that:
- If we plot performance as a function of training compute (on log scale), then there is a regime where performance is no better than trivial, and then at some point, it sharply increases.
- We don’t know how to predict in advance where that point will take place.
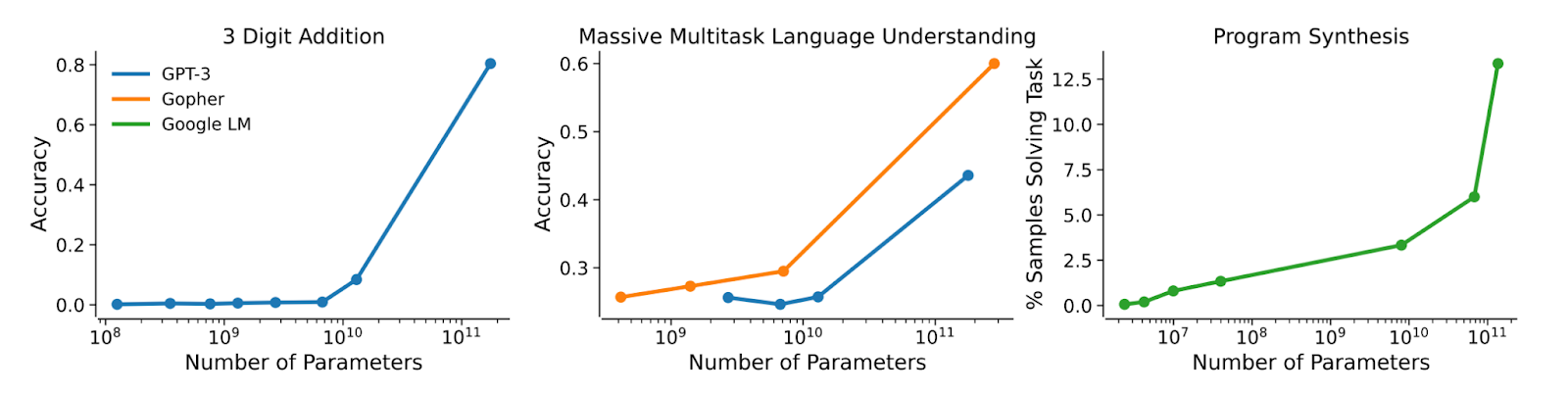
The “Grokking paper” of Power et al, also showed a dramatic improvement from chance to perfect on a synthetic setting of an algebraic task.
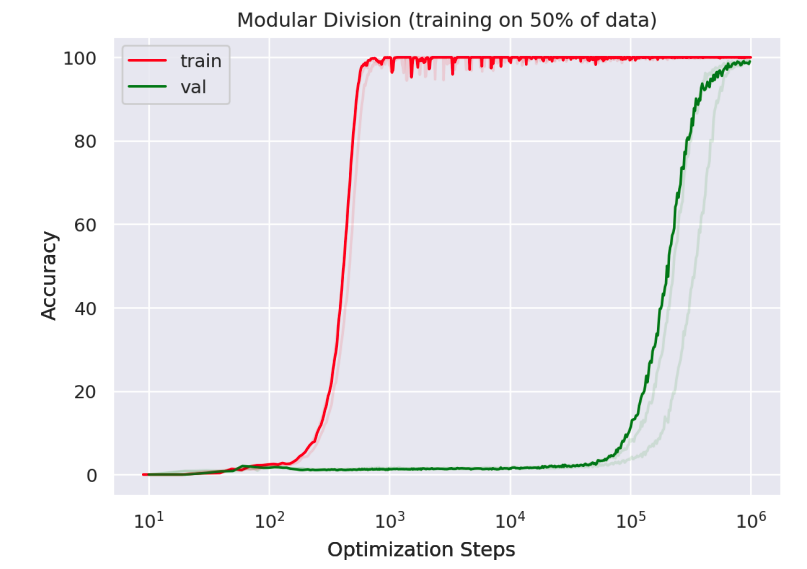
Are emergent abilities a mirage?
In a recent paper, Schaffer, Miranda, and Koyejo gave evidence that there may be a sense in which emergent abilities are “just a mirage” in the following sense. If we use a different metric for the task performance, then instead of an abrupt and unpredictable “jump,” we could get a smooth and predictable improvement.
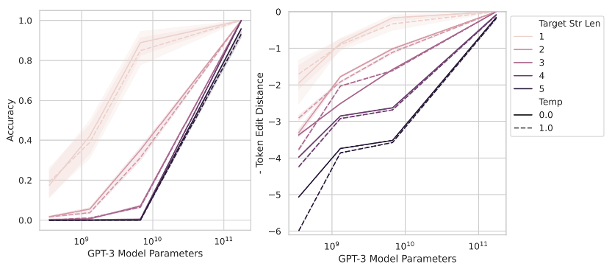
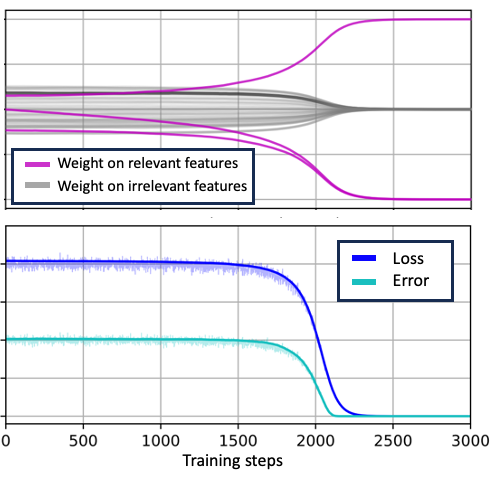
Our own paper (with Edelman, Goel, Kakade, Malach, and Zhang) showed something similar too for the task of learning parities, while Nanda et al used mechanistic interpretability to give a “progress measures” for the grokking example.
One way to think about this is with the following analogy. Consider someone trying to learn how to jump over a 1-meter hurdle.

As the aspiring athlete trains, their jump height will likely increase continuously. However, if we measure their performance by their probability of passing the hurdle, we will see the “sharp transition” / “emerging ability” type of curve.
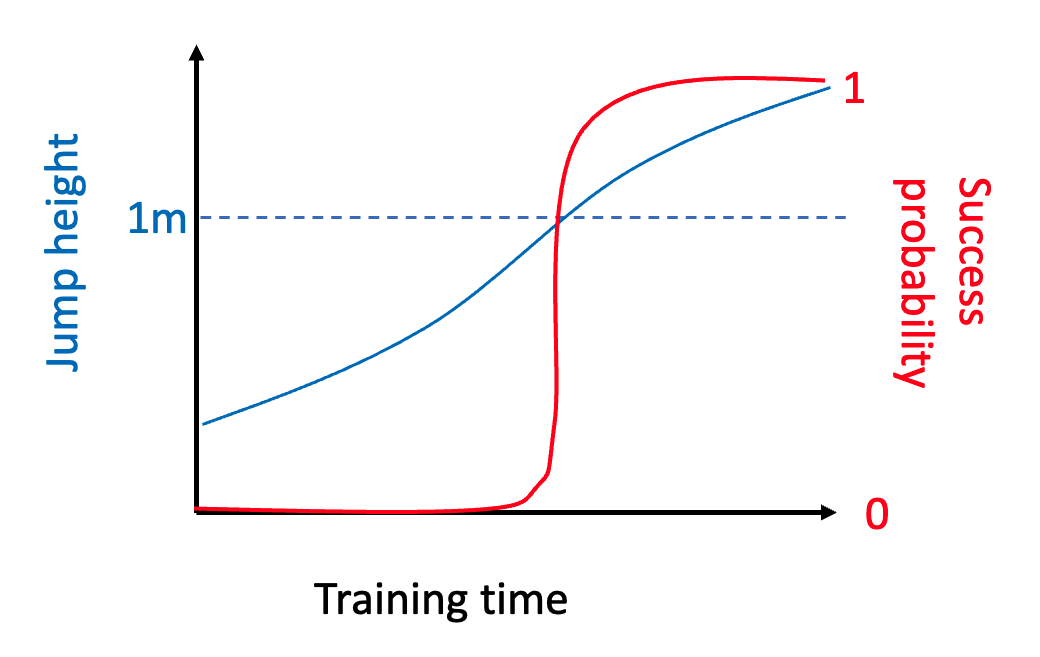
Indeed, in their beautiful paper, Schaffer, Miranda, and Koyejo show that many such “abrupt curves” disappear when changing the notion of metrics. Does this indicate that all emerging abilities are a mirage? I think the answer is no.
The reason is that for many real-world tasks, and in particular ones that involve reasoning, we need to solve multiple tasks successfully. Indeed, when generating a long “chain of thought,” we need to solve such tasks sequentially, and getting one of them wrong could get us completely off track. Schaffer et al. (Section 2) observe that the probability of success curve becomes much sharper when it corresponds to the AND of multiple events.
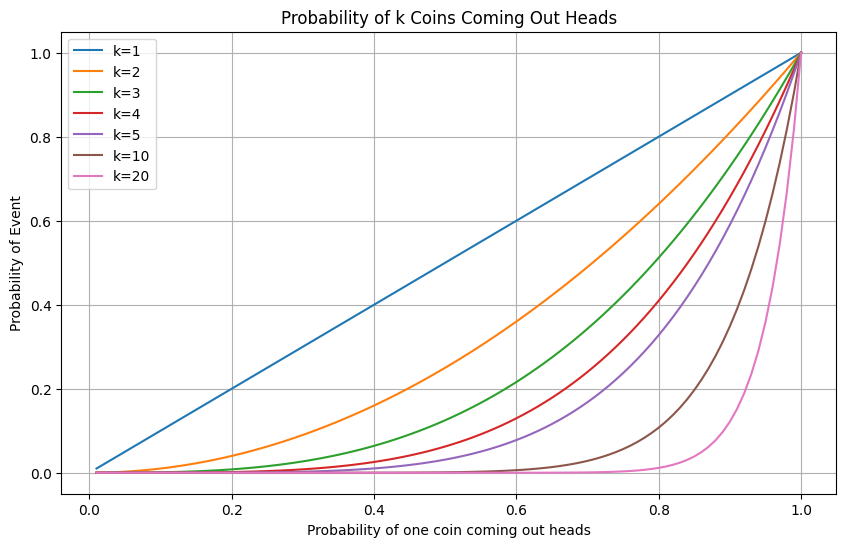
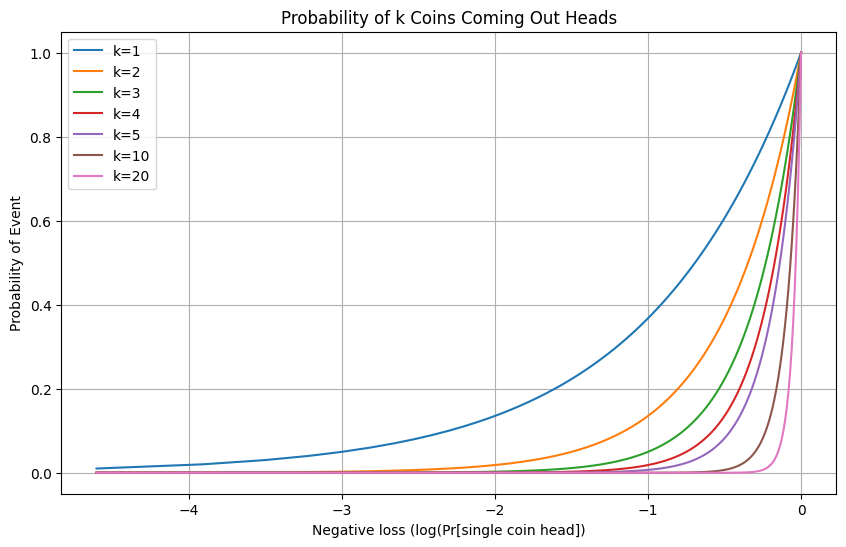
In many real-world tasks, we may not know how to “decompose” the complex task into a combination of simpler predictable components, especially not before we solve the task. So, even if we can precisely predict the loss of a model trained using N flops, we may not be able to predict which tasks it would solve beyond those solvable by an N/10 flop model.
