By Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever
This is a lightly edited and expanded version of the following post on the OpenAI blog about the following paper. While I usually don’t advertise my own papers on this blog, I thought this might be of interest to theorists, and a good follow up to my prior post. I promise not to make a habit out of it. –Boaz
TL;DR: Our paper shows that double descent occurs in conventional modern deep learning settings: visual classification in the presence of label noise (CIFAR 10, CIFAR 100) and machine translation (IWSLT’14 and WMT’14). As we increase the number of parameters in a neural network, initially the test error decreases, then increases, and then, just as the model is able to fit the train set, it undergoes a second descent, again decreasing as the number of parameters increases. This behavior also extends over train epochs, where a single model undergoes double-descent in test error over the course of training. Surprisingly (at least to us!), we show these phenomenon can lead to a regime where “more data hurts”—training a deep network on a larger train set actually performs worse.
Introduction
Open a statistics textbook and you are likely to see warnings against the danger of “overfitting”: If you are trying to find a good classifier or regressor for a given set of labeled examples, you would be well-advised to steer clear of having so many parameters in your model that you are able to completely fit the training data, because you risk not generalizing to new data.
The canonical example for this is polynomial regression. Suppose that we get n samples of the form (x, p(x)+noise) where x is a real number and p(x) is a cubic (i.e. degree 3) polynomial. If we try to fit the samples with a degree 1 polynomial—-a linear function, then we would get many points wrong. If we try to fit it with just the right degree, we would get a very good predictor. However, as the degree grows, we get worse till the degree is large enough to fit all the noisy training points, at which point the regressor is terrible, as shown in this figure:
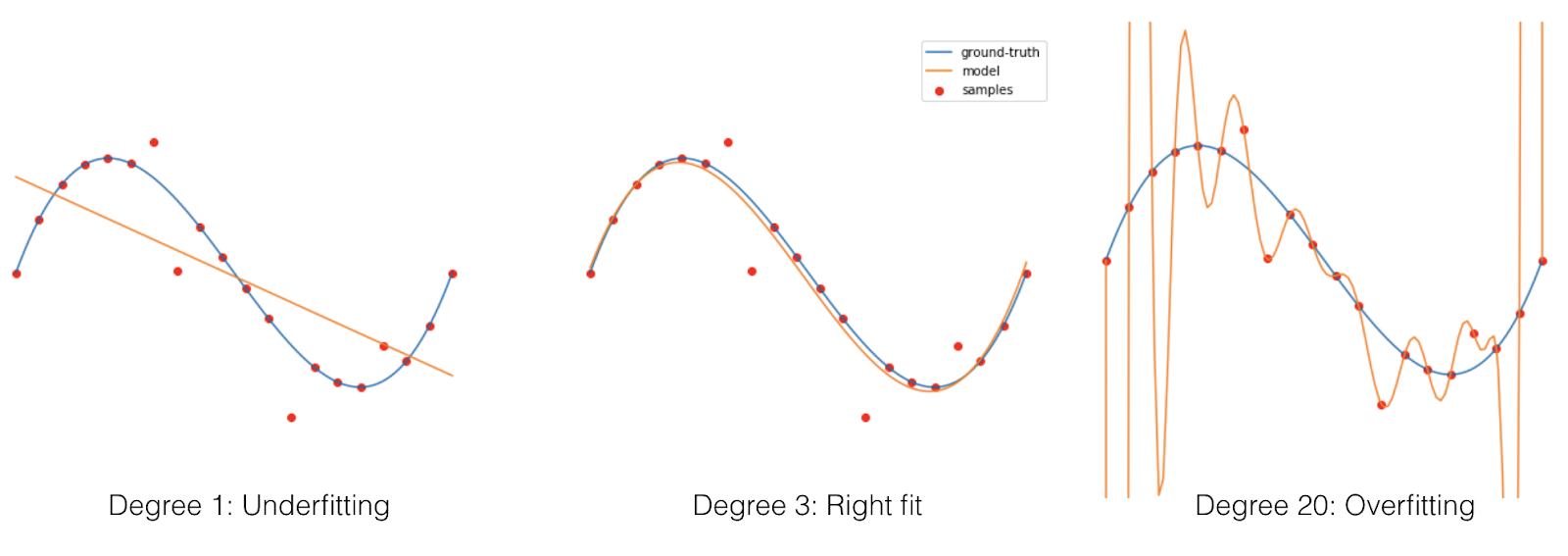
It seems that the higher the degree, the worse things are, but what happens if we go even higher? It seems like a crazy idea—-why would we increase the degree beyond the number of samples? But it corresponds to the practice of having many more parameters than training samples in modern deep learning. Just like in deep learning, when the degree is larger than the number of samples, there is more than one polynomial that fits the data– but we choose a specific one: the one found running gradient descent.
Here is what happens if we do this for degree 1000, fitting a polynomial using gradient descent (see this notebook):
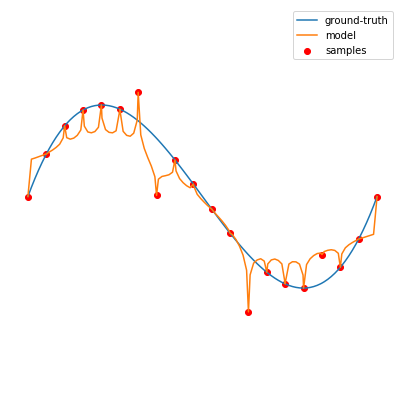
We still fit all the training points, but now we do so in a more controlled way which actually tracks quite closely the ground truth. We see that despite what we learn in statistics textbooks, sometimes overfitting is not that bad, as long as you go “all in” rather than “barely overfitting” the data. That is, overfitting doesn’t hurt us if we take the number of parameters to be much larger than what is needed to just fit the training set — and in fact, as we see in deep learning, larger models are often better.
The above is not a novel observation. Belkin et al called this phenomenon “double descent” and this goes back to even earlier works . In this new paper we (Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever) extend the prior works and report on a variety of experiments showing that “double descent” is widely prevalent across several modern deep neural networks and for several natural tasks such as image recognition (for the CIFAR 10 and CIFAR 100 datasets) and language translation (for IWSLT’14 and WMT’14 datasets). As we increase the number of parameters in a neural network, initially the test error decreases, then increases, and then, just as the model is able to fit the train set, it undergoes a second descent, again decreasing as the number of parameters increases. Moreover, double descent also extends beyond number of parameters to other measures of “complexity” such as the number of training epochs of the algorithm.
The take-away from our work (and the prior works it builds on) is that neither the classical statisticians’ conventional wisdom that “too large models are worse” nor the modern ML paradigm that “bigger models are always better” always hold. Rather it all depends on whether you are on the first or second descent. Further more, these insights also allow us to generate natural settings in which even the age-old adage of “more data is always better” is violated!
In the rest of this blog post we present a few sample results from this recent paper.
Model-wise Double Descent
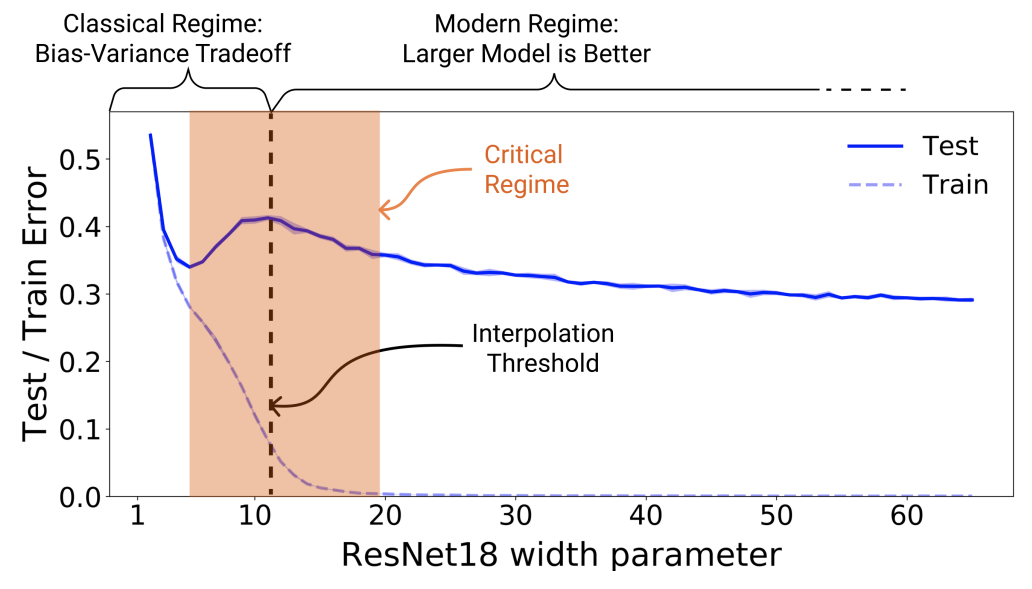
We observed many cases in which, just like in the polynomial interpolation example above, the test error undergoes a “double descent” as we increase the complexity of the model. The figure below demonstrates one such example: we plot the test error as a function of the complexity of the model for ResNet18 networks. The complexity of the model is the width of the layers, and the dataset is CIFAR10 with 15% label noise. Notice that the peak in test error occurs around the “interpolation threshold”: when the models are just barely large enough to fit the train set. In all cases we’ve observed, changes which affect the interpolation threshold (such as changing the optimization algorithm, changing the number of train samples, or varying the amount of label noise) also affect the location of the test error peak correspondingly.
We found the double descent phenomena is most prominent in settings with added label noise— without it, the peak is much smaller and easy to miss. But adding label noise amplifies this general behavior and allows us to investigate it easily.
Sample-Wise Nonmonotonicity
Using the model-wise double descent phenomenon we can obtain examples where training on more data actually hurts. To see this, let’s look at the effect of increasing the number of train samples on the test error vs. model size graph. The below plot shows Transformers trained on a language-translation task (with no added label noise):
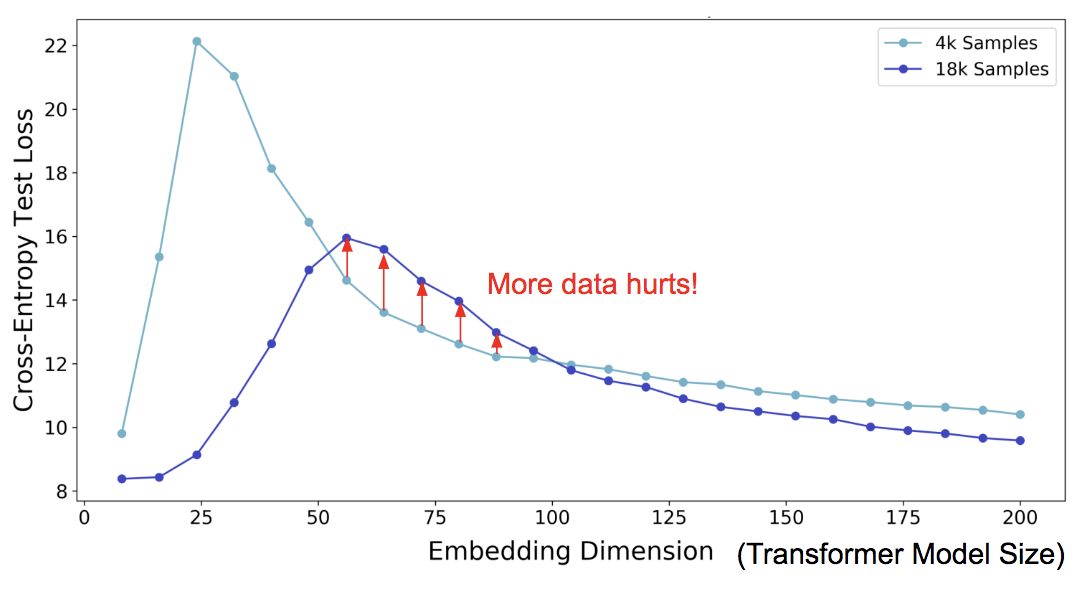
On the one hand, (as expected) increasing the number of samples generally shifts the curve downwards towards lower test error. On the other hand, it also shifts the curve to the right: since more samples require larger models to fit, the interpolation threshold (and hence, the peak in test error) shifts to the right. For intermediate model sizes, these two effects combine, and we see that training on 4.5x more samples actually hurts test performance.
Epoch-Wise Double Descent
There is a regime where training longer reverses overfitting. Let’s look closer at the experiment from the “Model-wise Double Descent” section, and plot Test Error as a function of both model-size and number of optimization steps. In the plot below to the right, each column tracks the Test Error of a given model over the course of training. The top horizontal dotted-line corresponds to the double-descent of the first figure. But we can also see that for a fixed large model, as training proceeds test error goes down, then up and down again—we call this phenomenon “epoch-wise double-descent.”

Moreover, if we plot the Train error of the same models and the corresponding interpolation contour (dotted line) we see that it exactly matches the ridge of high test error (on the right).
In general, the peak of test error appears systematically when models are just barely able to fit the train set.
Our intuition is that for models at the interpolation threshold, there is effectively only one model that fits the train data, and forcing it to fit even slightly-noisy or mis-specified labels will destroy its global structure. That is, there are no “good models”, which both interpolate the train set, and perform well on the test set. However in the over-parameterized regime, there are many models that fit the train set, and there exist “good models” which both interpolate the train set and perform well on the distribution. Moreover, the implicit bias of SGD leads it to such “good” models, for reasons we don’t yet understand.
The above intuition is theoretically justified for linear models, via a series of recent works including [Hastie et al.] and [Mei-Montanari]. We leave fully understanding the mechanisms behind double descent in deep neural networks as an important open question.
Commentary: Experiments for Theory
The experiments above are especially interesting (in our opinion) because of how they can inform ML theory: any theory of ML must be consistent with “double descent.” In particular, one ambitious hope for what it means to “theoretically explain ML” is to prove a theorem of the form:
“If the distribution satisfies property X and architecture/initialization satisfies property Y, then SGD trained on ‘n’ samples, for T steps, will have small test error with high probability”
For values of X, Y, n, T, “small” and “high” that are used in practice.
However, these experiments show that these properties are likely more subtle than we may have hoped for, and must be non-monotonic in certain natural parameters.
This rules out even certain natural “conditional conjectures” that we may have hoped for, for example the conjecture that
“If SGD on a width W network works for learning from ‘n’ samples from distribution D, then SGD on a width W+1 network will work at least as well”
Or the conjecture
“If SGD on a certain network and distribution works for learning with ‘n’ samples, then it will work at least as well with n+1 samples”
It also appears to conflict with a “2-phase” view of the trajectory of SGD, as an initial “learning phase” and then an “overfitting phase” — in particular, because the overfitting is sometimes reversed (at least, as measured by test error) by further training.
Finally, the fact that these phenomena are not specific to neural networks, but appear to hold fairly universally for natural learning methods (linear/kernel regression, decision trees, random features) gives us hope that there is a deeper phenomenon at work, and we are yet to find the right abstraction.
We especially thank Mikhail Belkin and Christopher Olah for helpful discussions throughout this work. The polynomial example is inspired in part by experiments in [Muthukumar et al.].

Interesting, I wonder if this is related to Naftali Tishby & team’s work (e.g. https://www.youtube.com/watch?v=XL07WEc2TRI&t=)
Thanks for the interesting post! The polynomial example is a very nice one but, if I’m not mistaken, it seems to hinge on an important point that’s not explicitly called out:
– Specifying the model not only involves choosing the degree of the polynomial to fit the data (3 vs. 1000), but also involves choosing a basis of polynomials, and the choice of basis appears very important.
– In particular, the fitted curve is sensitive to how the basis vectors are normalized. While Legendre polynomials are orthogonal, they are not orthonormal: the n-th polynomial has l2 norm sqrt(2/(2*n+1)) (see https://en.wikipedia.org/wiki/Legendre_polynomials). This means that the gradient-descent (or minimum-l2-norm) solution using the standard Legendre polynomial basis has a natural preference for lower degree basis vectors (which have a larger norm), and this inherent “regularization” looks to be very important for avoiding overfitting in the high-dimensional case (i.e., once you’re completely interpolating the in-sample data).
– Indeed, if I replace your definition of “G” (the Legendre basis) with an orthonormal version — a seemingly natural alternative:
def G(x, d):
B = np.polynomial.legendre.legvander(x, d)
B = B*np.sqrt(2*np.arange(0, B.shape[1], 1)+1)
return B
then the result for large degree grossly overfits the in-sample data (although in a very different way from the degree-20 case).
Presumably something similar is happening in other models that exhibit “double descent”, but in a way that’s probably much messier to analyze than polynomial interpolation!
Thank you for pointing this out. This is indeed quite interesting!
You are absolutely right! The choice of basis is quite important and can effect the ‘implicit bias’ (in this case, the minimum norm solution). Muthukumar et. al. have some interesting discussion about this for the minimum norm solutions in https://arxiv.org/pdf/1903.09139.pdf (Figure 5)
We implemented the normalization you suggested in this notebook https://colab.research.google.com/drive/1g8-oFZspHfKubT-8kNY6UfzLEBzVdtks to see what it looks like. As you pointed out, the function at d=10K does look quite different from the unnormalized basis.
This begs the question— “do operations such as rescaling of features break double descent? ” We don’t know for sure, but analysis of the linear regression problem suggests that it does not. Advani & Saxe 2017 https://arxiv.org/pdf/1710.03667.pdf, Mei & Montenari 2019 https://arxiv.org/pdf/1908.05355.pdf (and others) show that the test error diverges to infinity at d=N (in the limit of both d, N approaching infinity and some other assumptions). This is also visible in this particular example with normalization. As you said, both d=20 and d=10K overfit, but they overfit differently— d=10K is still a (relatively) smooth function + localized spikes, whereas d=20 behaves poorly more globally, resulting in much higher test error.
Regarding the case, where training on more data decreases performance: This also occurs in something as simple as linear regression. For example, with L2-regularized least squares, when the regularization is not strong enough, the generalization error will have a peak around where the number of observations equals the number of parameters.
just as an addendum: i understand that when the noise is small then the smooth-as-possible fitting of the noisy train data can give a not too bad function approximation that may, indeed, generalize better than the best models with complexity significantly less than the VC dimension (after all, we do get double descent in the limit of unknown but deterministic y(x)).. But when the noise is large than I don’t believe that will be the case…