
Last week, I gave a lecture on AI safety as part of my deep learning foundations course. In this post, I’ll try to write down a few of my thoughts on this topic. (The lecture was three hours, and this blog post will not cover all of what we discussed or all the points that appeared in the pre-readings and the papers linked below.)
The general goal of safety in artificial intelligence is to protect individual humans or society at large from harm. The field of AI safety is broad and considers risks including:
- Harm to users of an AI system or harm to third parties due to the system not functioning as intended. One example includes drivers or pedestrians harmed by the failures of self-driving cars. For instance, there were several fatal accidents involving Tesla’s autopilot. Interestingly, just last week, Elon Musk tweeted the following:
- Another example is harm from automated decisions that may be unfair. The paper of Wang et al. discusses the risks of “predictive optimization.” One well-known example is the COMPAS risk-assessment system for bail decisions (see Pro-Publica’s investigation, as well as the broader discussion by Hardt, Price, and Srebro)
- Algorithmic decisions could cause “feedback loops”, where several algorithms interact with each other in unexpected and ever-escalating ways. Algorithmic trading was blamed for the 2010 “Flash Crash”; another example is how a single not-very-rare book came to be priced at $24M on Amazon.
- There are many societal risks in AI. These include job loss, amplifying biases, concentrating power, appropriating content, and exploiting data workers.
- Yet another issue was pointed out to me by Yejin Choi – “AI literacy.” As AI’s capabilities are rapidly advancing, it will take some time for people to get used to them, and during this time, we may misinterpret them. This is manifested in people seeing such systems as sentient (something that already happened with the 1966 chatbot ELIZA). Another example is “deepfakes”: inauthentic images or videos that could mislead people that are not yet aware of AI’s capabilities (again, an issue with a long history).
- AI could be misused by bad actors for hacking, spreading dis-information, help in designing weapons, and more.
- Finally, several people are concerned about artificial intelligence systems acting themselves as “malicious agents”, which could behave in adversarial ways, harming humanity and in extreme cases leading to an existential risk of “loss of control” of humanity over its future or extinction.


Different subfields of “AI safety” deal with different aspects of these risks. AI “assurance,” or quality control, is about ensuring that systems have clear specifications and satisfy these specifications. An example of work along these lines is Shalev-Shwartz et al, who gave a framework for formally specifying safety assurances for self-driving cars.. AI ethics deals with the individual and social implications of deploying AI systems, asking the question of how AI systems could be deployed responsibly and even whether such a system should be deployed at all. Security deals with malicious actors, that could both be the users of AI, suppliers of data (e.g., data poisoning and prompt injection attacks), or control other aspects of the environment. Finally, researchers in “alignment” or “existential risk” are concerned with the case in which the AI itself is the adversary. These subfields are not disjoint and share overlapping concerns.
Another way to classify risks is to consider the extent to which they are reduced or magnified by the normal processes of the free market and improved technology.
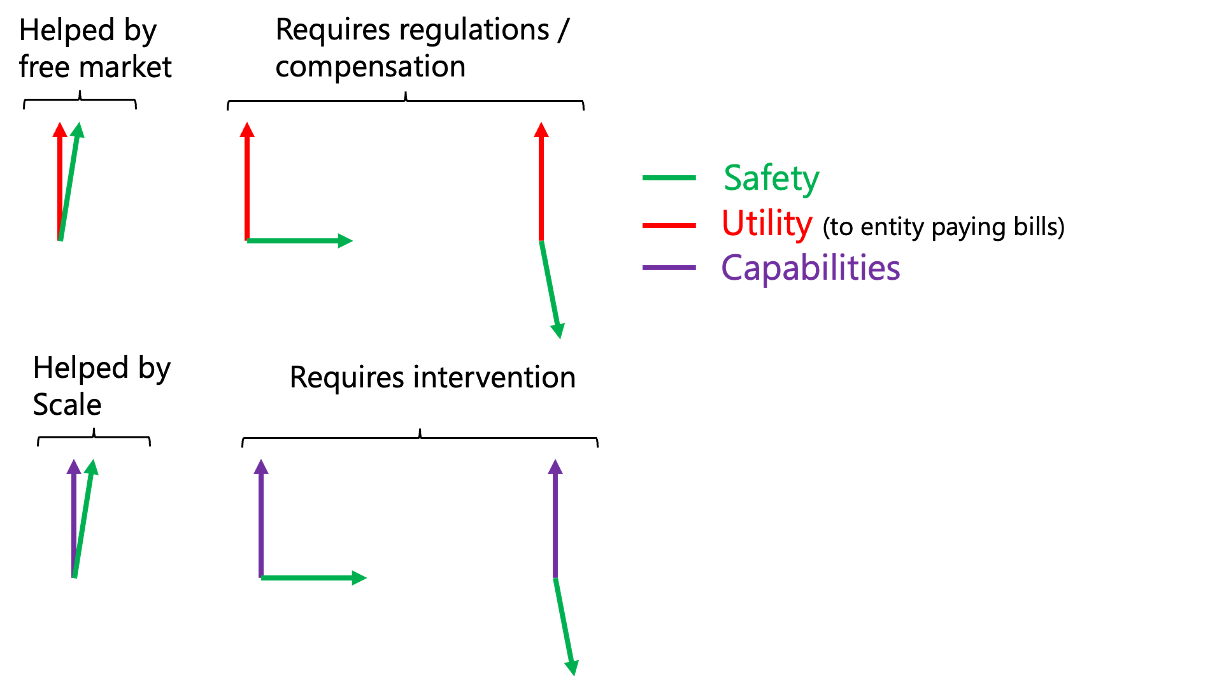
In some cases, the interests of safety go hand in hand with the economic incentives for the entity controlling the model, while in others they could be unrelated or even directly opposed to these incentives. Similarly, in some cases, improving capabilities (e.g., by increasing the size of models and data) would reduce risks, while in others, this might not help or even harm.
Impact of AI on humanity – the baseline expectation
Artificial intelligence is a very general technology, and as such, we might expect its impact on humanity to be qualitatively similar to that of past technological revolutions. If we look at the past, we can draw two lessons:
- Technological revolutions have both positive and negative impacts, but in the long run and summing over populations, the positives outweigh the negatives. For example, measures such as life expectancy and GDP per capita have gone up over history.
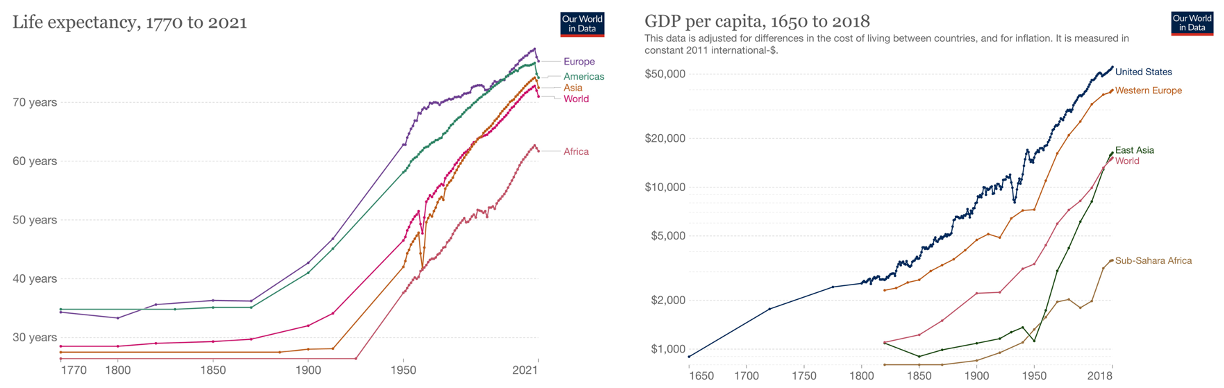
- There is no reason to assume that the benefits of technology will be distributed equally. Inequality can go either up or down, dependent on government policies rather than technological improvements.
In my lecture, I discussed the issue of fairness. I discussed both the COMPAS system as well as the paper of Hardt et al, visualized in the following page, demonstrating how different notions of fairness can be at odds with maximizing profits and even at odds with one another. In this blog post, I focus on the settings where capabilities and safety may be at odds.
Capabilities
As is well known, the capabilities of artificial intelligence systems have been growing in recent years, see, for example this paper of Wei et al.
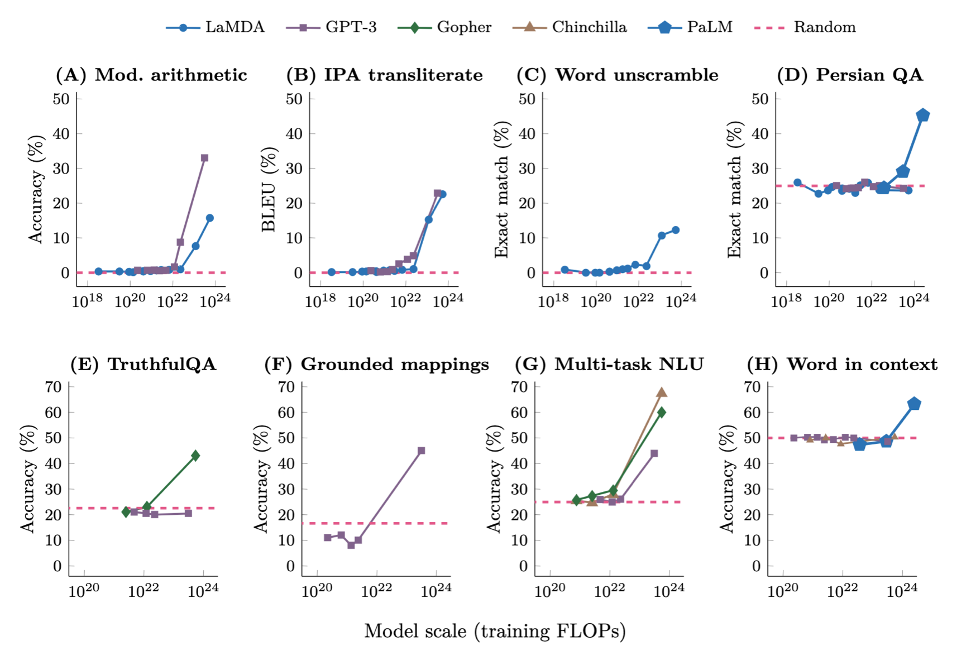
Graphs like these show capabilities emerging suddenly with model scale. However, we should note that these graphs are plotted with the X axis on the log scale. If we plot it on linear scale, it would be much less abrupt.
Another way to plot increasing capabilities is to look at improvements in ELO scores of Chess engines.
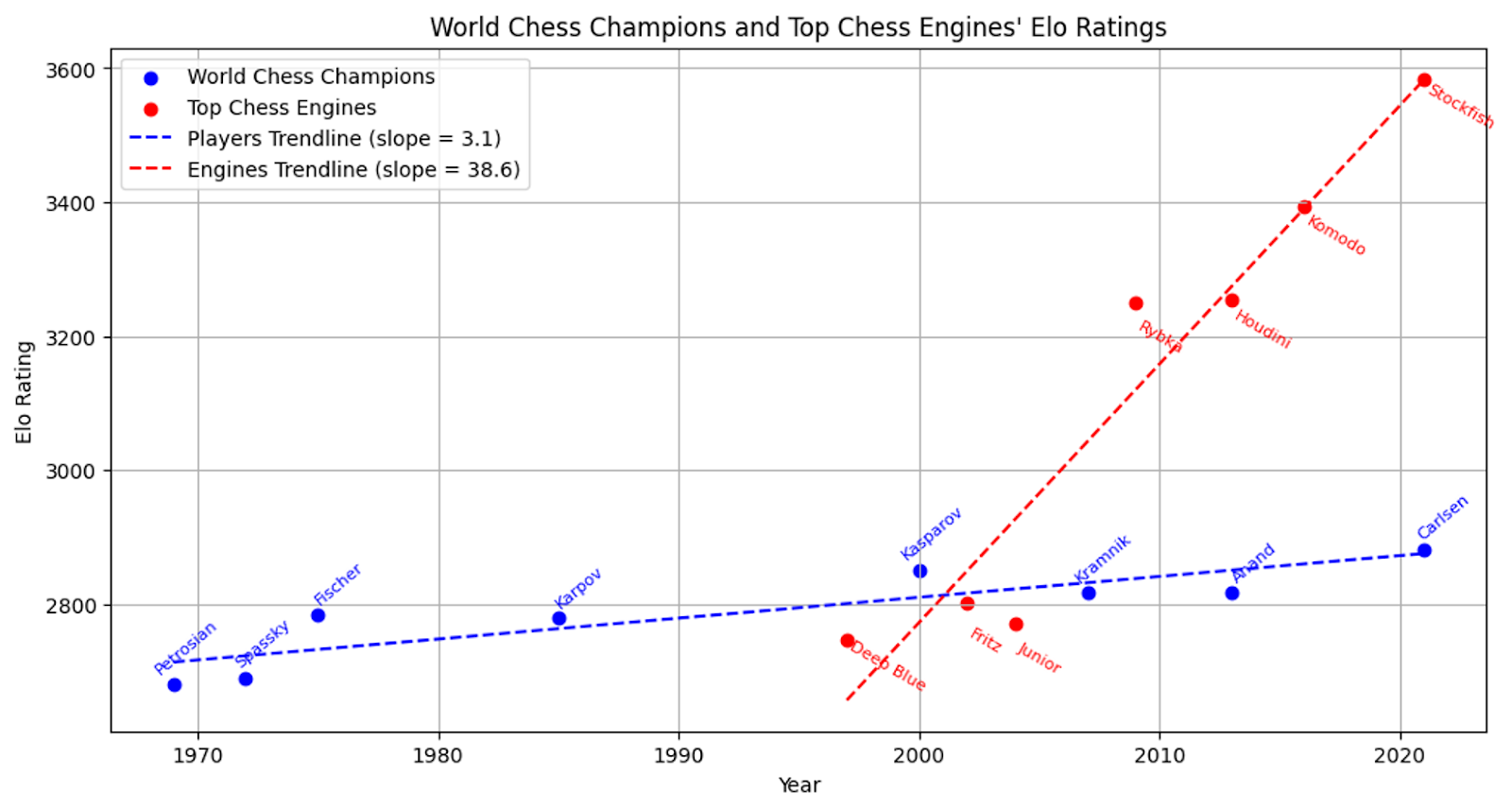
Once again, we see improvement with time. (Due to Moore’s law, we can also treat the X axis as a log scale here. BTW credit for this figure is due to GPT4; I didn’t verify the numbers though I probably should have.)
Given the above, we might expect future capabilities to increase roughly as follows: (this is a cartoon, so the slope or the labels on either axis should not be taken too seriously)

However, Moore’s law (assuming it keeps holding) can reduce costs as a function of time. Also, the graph may well behave differently for different skills. Finally, if we manage to use AI to reduce the costs of building future AI (i.e. “self improvement” or “singularity”), then the costs could be radically reduced.
Capabilities vs. Safety Round 1: Risk of misuse
One aspect in which increased capabilities seem to be at odds with safety is the potential for misuse of AI. The more powerful an AI system is, the more harm one can do with it. However, this logic assumes that only the attacker can access the system. In many cases, increased capabilities of AI benefits both the “attacker” and “defender”, and it is unclear which one would be helped more.
For example, AI systems could find software vulnerabilities and help hackers, but software companies could also use them to secure their systems. AI could be used to spread disinformation on social media and by social media companies to detect such disinformation. A related setting is the use of AI for persuasion. However, it is still an open question whether the current “limiting factor” in persuasion, whether it’s advertising or scams, is a lack of know-how or workforce on the part of the persuaders. Rather, it may be that different people have varying susceptibility to persuasion; thus, even very skilled persuaders will be limited in the number of people they can persuade and the things they can persuade them to do. Also, AI could be used to combat illicit persuasion by detecting scams, just as it is currently used in spam detection.
An example closest to my expertise is student cheating. AI may help professors detect cheating more than it helps potential cheaters. In past semesters, if I wanted to detect whether two students copied from one another, I needed to “run” an N² time algorithm (manually comparing all pairs of submissions). Now I could ask ChatGPT to compare all pairs and summarize any suspicious similarities. If I am worried about students using ChatGPT itself to cheat, I can ask it to throw its own solution into the pool of comparands (and maybe some solutions from past semesters or Course Hero as well).
There are other misuse scenarios in which the balance does favor the attacker. For example, an attacker might be able to use a system to learn how to make a bomb or get detailed information about a physical target for an attack. However, society has been through inflection points such as this in the past, when the amount of information available to ordinary citizens radically increased. It is unclear to me that the increase in access to harmful information due to AI would be larger than the increase between the pre- and post-Internet eras.
Capabilities vs. Safety Round 2: Unaligned powerful AI systems
The other setting in which increased capabilities could lead to higher risk is when we are concerned with the AI systems themselves behaving in “agentic” or malicious ways. We do not have to get into the question of whether such systems could be “sentient” or “concious” but rather ask whether it might be possible that the systems’ actions would be so complex and unpredictable that they could be modeled as adversarial.
There is a long history of worrying about such risks. Alan Turing famously said in 1951 that “it seems probable that once the machine thinking method had started, it would not take long to outstrip our feeble powers. They would be able to converse with each other to sharpen their wits. At some stage therefore, we should have to expect the machines to take control.”
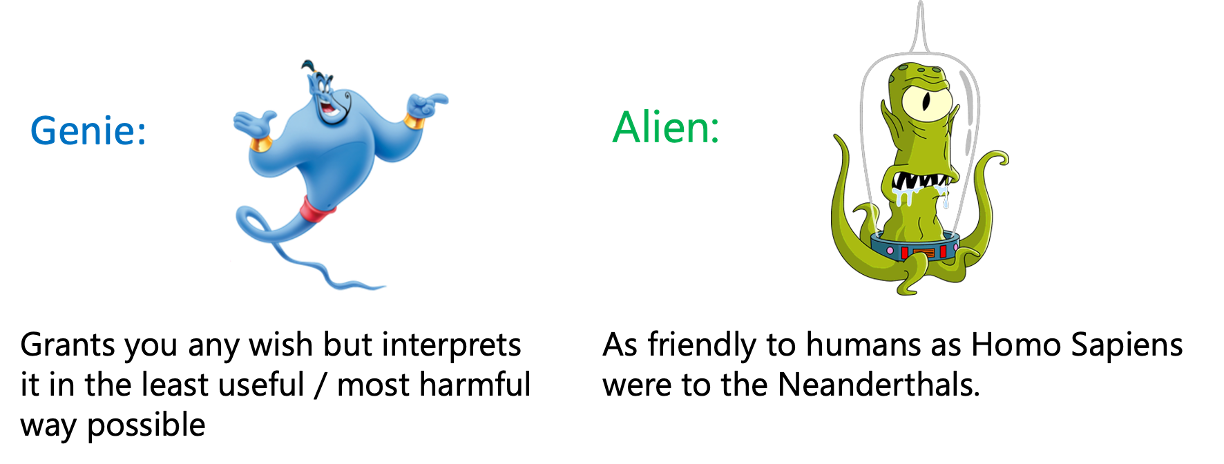
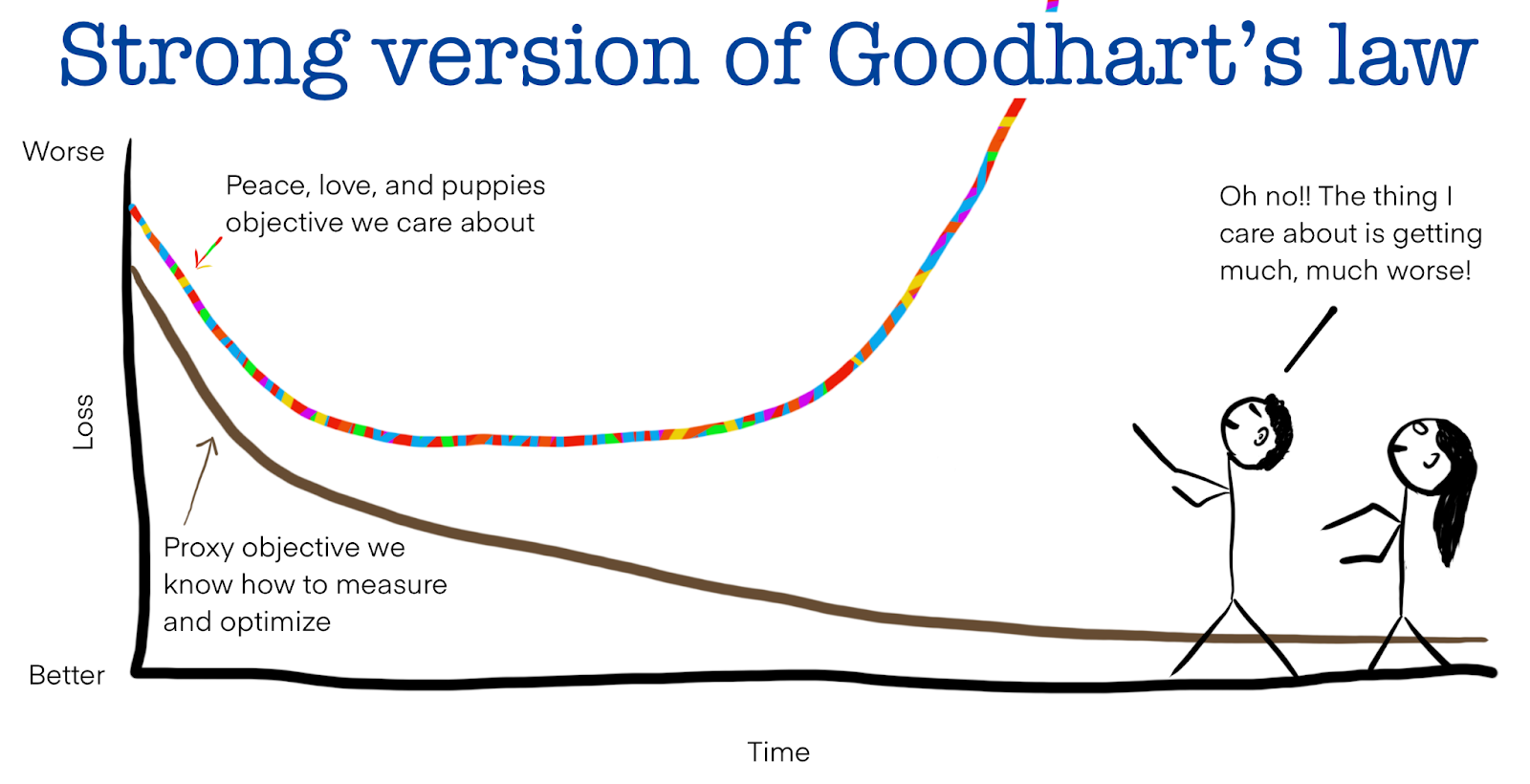
There are two metaphors for a “super human AI”. One is the model of an AI as a “genie”: an entity that is single-mindedly focused on optimizing some objective (a.k.a granting a wish). However, like the genies in many stories, it may interpret the wish in a way that is literally true but completely misaligned with the intentions and interests of the human who made it. A less fanciful way to phrase this is that we expect that any objective, when pursued relentlessly, will eventually be misaligned with the general well-being of society. In his blog, Jascha Sohl-Dickstein called this principle the “strong version of Goodhat’s law” and illustrated it as follows:
Specifically, the concern is that to satisfy any objective, it seems useful to seek power, and it is possible systems might use deception as well. Ngo et al raised the concern that such systems would develop “situational awareness” and behave differently when trained and deployed.
The other metaphor for a “super-human AI” is the one of the “alien”: it is highly intelligent, but like us, it is not focused on a single goal; rather, its intelligence (to use another term from Sohl-Dickstein) is a “hot mess”. Being like us is not necessarily a good thing. For example, the interaction between early modern humans and the Neanderthals did not go well for the latter. (Though we don’t know whether or not Homo Sapiens had cognitive advantages over Neanderthals, and if so, whether those played a key role in the Neanderthal’s extinction. Also, as our society has grown more sophisticated, we are trying to do more to conserve rather than extinguish other species.)
The “AI as a genie” metaphor arises from the fact that AI systems are often the result of some optimization procedure. In particular, in reinforcement learning (RL), the system is trained to maximize some reward. While RL wasn’t used in earlier large language models (LLMs), it has recently been used in models such as GPT3.5, training a “reward model” from human feedback that is later used in an RL procedure to generate a sequence of tokens that maximizes the reward (this is known as RL from human feedback or RLHF). Ngo et al claimed that the use of RLHF could lead models to “reward hacking” in which the model pursues goals that, like in the “strong version of Goodhart’s law” would be ultimately detrimental to humanity.
To me, this particular concern hinges on the question of whether RLHF amounts to most of the “magic” in modern LLMs or whether (to use a phrase favored by Yann LeCun) it is merely the “cherry on top”.

If we believe that “magic” corresponds to computational or data resources, then RLHF is merely the “cherry on top”. While OpenAI did not reveal details, Anthropic trained a similar model and used about 10¹¹ tokens in pre-training, while only about 10⁵ human annotations for RLHF. So if the computational scale is the same as “magic,” then intelligence is formed at pre-training and only shaped by RLHF. Is scale the same as magic? I would argue that this is what the bitter lesson tells us.
Even so, should we still be worried about the “alien” model? The question is, again, who is the alien? Do we think of the AI system as the combination of the pre-trained model and whatever “fine tuning” or “reinforcement learning” adapter is on top of it? Or is the heart of the system the pre-trained model itself?
If we consider the pre-trained model as the heart of the system, then I argue that modeling it as an individual entity or agent is misguided. In fact:
A pre-trained language model is not an imitation of any human, it is an imitation of all of humanity.
A pre-trained generative text model is not designed to model any particular entity. Rather, it is designed to generate all text that it has been trained on and, along the way, develop the skills to perform deductions, combinations, and style transfers on this text. To use such a model as an assistant, we need to condition it by providing a prompt, much like we can condition an image generative model to generate images inside one particular building. If we think of a pre-trained model as an “intelligence engine” that is later used with “adapters” (that could include learned models, hard-coded programs, as well as humans), then our assumptions on the risk scenarios change. Rather than a monolithic “AI system” that could act in adversarial ways, we might have a variety of agents/modules built on top of the “intelligence engine”. Some of these agents, whether human or artificial, may well be adversarial. However, all of those would have access to the same “engine,” and so the rising tide of AI will lift all (good and bad) boats.
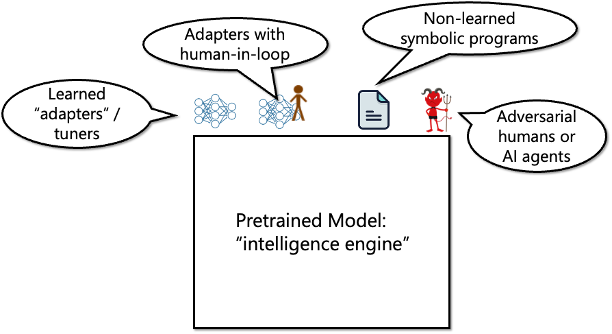
Generally, I think that the view of “intelligence” as some inherent skill belonging to a monolithic entity or agent is quite anthropocentric. In fact, it’s not even true for humans. While the human brains have not grown for more than hundred thousand years, human society has collectively become more intelligent over the last millennia and centuries, and all of us can access this collective intelligence. Indeed, with modern deep learning, we can take any advanced AI system and fine-tune it to achieve a particular task of interest. Hence intelligence is not so much a skill of an individual as a capability of the system as a whole.
Verification
Regardless of whether you are concerned about AI taking over humanity or simply about the wisdom of deploying highly complex systems that we don’t fully understand, verification can be a crucial element for ensuring safety. One of the general principles we see time and again in theoretical computer science is that
Verification is easier than creation.
(In other words, it’s easier to be the critic than the “man in the arena” – and that’s a good thing!)
This is the content of the P vs NP conjecture and also underlies the theory of probabilistically checkable proofs. (PCPs) These are now used in cryptography to delegate computation by a weak verifier to a powerful server (see this interview with Yael Kalai, and her survey) which is a problem not unlike the task of verifying a powerful AI by a weaker entity.
I recently saw a talk by Zico Kolter in which he put forward the following equation as to when generative models have positive utility:

That is, as long as the time for us to verify a solution is smaller than the time to generate it ourselves multiplied by the probability that the model’s output is correct, then we can efficiently use a model by always verifying its output, spending the effort to generate a solution ourself if verification fails. Our expected time would be smaller than the time spent generating solutions from scratch, even if the model is far from always correct.
The principle that verification can be done even with powerful provers is one we see in human enterprises as well. Terence Tao might be (by some measures) the world’s top mathematician. But he still submits his papers to peer review, and they can (and are) checked by mere “mortals”. Indeed I would argue that this ability to communicate, verify, and teach is the reason that human society has managed to “stand on the shoulders of giants” and achieve such growth in productivity despite working with the same human brains our ancestors used to run from animals. Theories like relativity may have taken a huge effort to discover, but once discovered, could be communicated, verified, and are now taught to first-year undergraduates.
Interestingly, it seems that the professions that are more subject to verification are not the ones that require the most information-processing skills but rather “alignment”: more “wisdom” than “smartness”. Perhaps those professions would not be the professions most amenable for AIs.

Practical verification of ML systems is still an ongoing effort. There are methods for red teaming, self-critiquing, probing for consistency, or testing generated code that can reduce errors. However, we do not yet have robust verification schemes in the sense that we can reliably drive the error probability to zero by spending more effort at inference (let alone drive it exponentially fast to zero, as we can often do in theoretical CS- something that may be crucial for ensuring robustness against adversarial inputs).
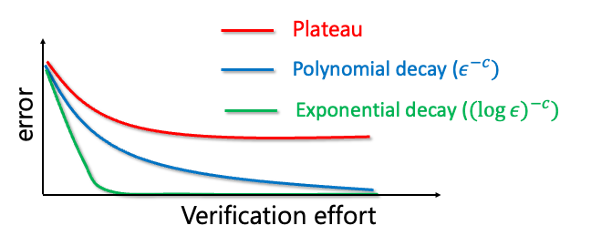
One potential advantage of AI models is that they can themselves write symbolic proofs that may later be verifiable with formal theorem provers. For example, Wu et al used LLMs to formalize mathematical competition problems in the systems Isabelle/HOL. Overall, there seems to be a huge potential in combining the rich literature on proof systems with the power of modern language models.
To sum up, artificial Intelligence has made great strides in performance over the last decade and will be widely deployed across many fields in the near future. As the use of AI systems increases, so will the importance of ensuring reliability, fairness, trustworthiness, and security.
