(Also available as a pdf file. Apologies for the many footnotes, feel free to skip them.)
Computational problems come in all different types and from all kinds of applications, arising from engineering as well the mathematical, natural, and social sciences, and involving abstractions such as graphs, strings, numbers, and more. The universe of potential algorithms is just as rich, and so a priori one would expect that the best algorithms for different problems would have all kinds of flavors and running times. However natural computational problems “observed in the wild” often display a curious dichotomy— either the running time of the fastest algorithm for the problem is some small polynomial in the input length (e.g., 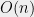
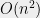

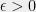
To be sure, none of these observations are universal laws. In fact there are theorems showing exceptions to such dichotomies: the Time Hierarchy Theorem says that for essentially any time-complexity function 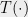
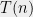
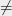
I believe that one reason underlying this pattern is that many computational problems, in particular those arising from combinatorial optimization, are unstructured. The lack of structure means that there is not much for an algorithm to exploit and so the problem is either very easy”— e.g., the solution space is simple enough so that the problem can be solved by local search or convex optimization2— or it is very hard”— e.g., it is NP-hard and one can’t do much better than exhaustive search. On the other hand there are some problems that posses a certain (often algebraic) structure, which typically is exploitable in some non-trivial algorithmic way. These structured problems are hence never “extremely hard”, but they are also typically not “extremely easy” since the algorithms solving them tend to be more specialized, taking advantage of their unique properties. In particular, it is harder to understand the complexity of these algebraic problems, and they are more likely to yield algorithmic surprises.
I do not know of a good way to formally classify computational tasks into combinatorial/unstructured vs. algebraic/structured ones, but in the rest of this essay, I try to use some examples to get a better sense of the two sides of this divide. The observations below are not novel, though I am not aware of explicit expositions of such a classification (and would appreciate any pointers, as well as any other questions or critique). As argued below, more study into these questions would be of significant interest, in particular for cryptography and average-case complexity.
Combinatorial/Unstructured problems
The canonical example of an unstructured combinatorial problem is SAT— the task of determining, given a Boolean formula 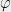



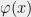

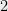
Random SAT formulas also display a similar type of dichotomy. Recent research into random 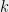

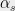


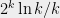

 |
 |
| Figure 1: An illustration of the solution space geometry of a random SAT formula, where each point corresponds to an assignment with height being the number of constraints violated by the assignment. The left figure depicts the “ball” regime, where a satisfying assignment can be found at the bottom of a smooth “valley” and hence local algorithms will quickly converge to it. The right figure depicts the “shattered” regime where the surface is very ragged, with an exponential number of crevices and local optima, thus local algorithms (and as far as we know any algorithm) will likely fail to find a satisfying assignment. Figures courtesy of Amin Coja-Oghlan. | |
Dichotomy means that when combinatorial problems are hard, then they are typically very hard, not just in the sense of not having a subexponential algorithm, but they also can’t be solved non-trivially in some intermediate computational models that are stronger than P but cannot solve all of NP such as quantum computers, statistical zero knowledge, and others. In particular for combinatorial problems (quoting Lovász) the existence of a good characterization (i.e., the ability to efficiently verify both the existence and non-existence of a solution) goes hand-in-hand with the existence of a good algorithm. Using complexity jargon, in the realm of combinatorial optimization it seems to hold that P
Combinatorial problems can be quite useful for cryptography. It is possible to obtain one-way functions from random instances of combinatorial problems such as SAT and CLIQUE. Moreover, the problem of attacking a cryptographic primitive such as a block cipher or a hash function can itself be considered a combinatorial problem (and indeed this connection was used for cryptanalysis). However, these are all private key cryptographic schemes, and do not allow two parties to communicate securely without first exchanging a secret key. For the latter task we need public key cryptography, and as we discuss below, the currently known and well-studied public key encryption schemes all rely on algebraic computational problems.
Algebraic/Structured problems
FACTORING is a great example of an algebraic problem; this is the task of finding, given an 





There is another, more subjective sense, in which I find FACTORING different from SAT . I personally would be much more shocked by a 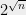

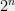
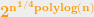

Not all algebraic problems are hard. Factoring univariate polynomials over finite fields can be solved efficiently using the Berlekamp or Cantor-Zassenhaus algorithms (see e.g. chapter 21 here). This algorithm also exemplifies the statement above, that algorithms for algebraic problems are often very specialized and use non-trivial properties of the problem’s structure. For this reason, it’s harder to predict with confidence what is the best algorithm for a given algebraic problems, and over the years we have seen several surprising algorithms for such problems, including, for example, the fast matrix multiplication algorithms, the non-trivial factoring algorithms and deterministic primality testing, as well as the new algorithm for discrete logarithm over small-characteristic fields mentioned above.
Relation to cryptography. Algebraic problems are very related to public key cryptography. The most widely used public key cryptosystem is RSA, whose security relies on the hardness of FACTORING . The current subexponential algorithms for FACTORING are the reason why we use RSA keys of 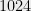




Cryptosystems based on the discrete logarithm problem in elliptic curves yield one alternative to RSA which currently is not known to be broken in subexponential time. Elliptic-curve discrete log is of course also very much an algebraically structured problem, and so, I would argue, one in which further algorithmic surprises are hard to rule out. Moreover, like factoring, this problem can be solved in polynomial time by quantum computers, using Shor’s algorithm.
The only other public key cryptosystems that are researched enough to have some confidence in their security are based on decoding problems for linear codes or integer lattices. These problems are not known to have subexponential algorithms, classical or quantum. Moreover, some variants of these problems are actually NP-hard. Specifically, theses problem are parameterized by a number 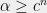




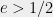
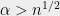


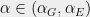
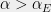
The bottom line is that based on the currently well studied schemes, structure is strongly associated with (and perhaps even implied by) public key cryptography. This is troubling news, since it makes public key crypto somewhat of an “endangered species” that could be wiped out by a surprising algorithmic advance. Therefore the question of whether structure is inherently necessary for public key crypto is not only of mathematical interest but also of practical importance as well. Cryptography is not just an application of this classification but also provides a useful lens on it. The distinction between private key and public key crypto mirrors the distinction between unstructured and structured problems. In the private key world, there are many different constructions of (based on current knowledge) apparently secure cryptosystems; in fact, one may conjecture (as was done by Gowers) that if we just combined a large enough number of random reversible local operations then we would obtain a secure block cipher. In contrast, for public key cryptography, finding a construction that strikes the right balance between structure and hardness is a very hard task, worthy of a Turing award, and we still only know of a handful or so such constructions.
A different approach to average case complexity
I am particularly interested in this classification in the context of average-case complexity. In the case of worst-case complexity, while we have not yet managed to prove that P

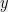

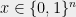
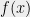

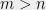
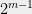
This difficulty is one reason why the theory of average-case complexity is much less developed than the theory for worst-case complexity, even though average-case complexity is much more relevant for many applications. The observations above suggest that at least for combinatorial problems, we might hope for a different approach: define a meta conjecture that stipulates that for a whole class of average-case problems, a certain algorithmic framework yields the optimal efficient algorithm, meaning that beating the performance of that algorithm would be infeasible (e.g., take exponential time). To make things more concrete, consider the following hypothesis from a paper with Kindler and Steurer:
Random CSP Hypothesis. For every predicate
, if we let
be the problem of estimating the fraction of constraints that can be satisfied for an instance chosen at random, then no efficient algorithm can obtain a better approximation to
, where
Note that this is a much more general conjecture that P

Despite it being such a general hypothesis, I don’t think the Random CSP Hypothesis is yet general enough— there may well be significant extensions to this hypothesis that are still true, involving combinatorial problems different than CSP’s, and distributions different than the uniform one. Perhaps with time, researchers will find the right’ ‘meta conjecture” which will capture a large fraction of the problems we consider “combinatorial”.
At first brush, it might seem that I’m suggesting to trivialize research in average-case complexity by simply assuming all the hardness results we wish for. But of course, there is still a very real challenge to find out if these assumptions are actually true! Given our current state of knowledge, I don’t foresee an unconditional proof of these types of assumptions, or even a reduction to a single problem, any time soon. But as I discussed before this doesn’t mean we can’t gather evidence on these meta assumptions. In particular, such assumptions form very “fat targets” for potential refutations. For example, all we have to do to refute the Random 3CSP Hypothesis is to find a single predicate 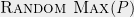
Conclusions
While much of what I discussed consists of anecdotal examples, I believe that some works, such as those related to the Feder-Vardi conjecture or to phase transitions in random CSP’s, offer a glimpse of a potential general theory of the complexity of combinatorial problems. I think there is room for some ambitious conjectures to try to illuminate this area. Some of these conjectures might turn out to be false, but we can learn a lot from exploring them. Understanding whether “the markers of structure” such as subexponential algorithms, quantum algorithms, good characterization, usefulness for public key cryptography, etc.. need always go together would be extremely useful for many applications, and in particular cryptography. Even more speculatively, perhaps thinking about these issues can help towards the goal of unconditional results. The richness of the space of algorithms is one of the main “excuses” offered for our relatively little success in proving unconditional lower bounds. If indeed this space is much more limited for combinatorial problems, perhaps this can help in finding such proofs.7
Thanks to Scott Aaronson, Dimitris Achlioptas, Amin Coja-Oghlan, Tim Gowers, and David Steurer for useful comments and discussions.
Footnotes
1 The standard definition of “convexity” of the solution space of some problem only applies to continuous problems and means that any weighted average of two solutions is also a solution. However, I use “convexity” here in a broad sense meaning having some non-trivial ways to combine several (full or partial) solutions to create another solution; for example having a matroid structure, or what’s known as “polymorphisms” in the constraint-satisfaction literature.} This phenomenon is also related to the unreasonable effectiveness” of the notion of NP-completeness in classifying the complexity of thousands of problems arising from dozens of fields. While a priori you would expect problems in the class NP (i.e., those whose solution can be efficiently certified) to have all types of complexities, for natural problems it is often the case that they are either in P (i.e., efficiently solveable) or are NP-hard (i.e., as hard as any other problem in NP, which often means complexity of 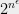
2 Of course even if the algorithm is simple, analyzing it can be quite challenging, and actually obtaining the fastest algorithm, as opposed to simply one that runs in polynomial time, often requires additional highly non-trivial ideas. ↺
3 The main stumbling block for completing the proof is dealing with those CSPs that require a Gaussian-elimination type algorithm to solve; one can make the argument that those CSP’s actually belong to the algebraic side of our classification, further demonstrating that obtaining precise definitions of these notions is still a work in progress. Depending on how it will be resolved, the Unique Games Conjecture, which I discussed here, might also give rise to CSP’s with “intermediate complexity” in the realm of approximation algorithms. Interestingly both these issues go away when considering random, noisy, CSP’s, as in this case solving linear equations becomes hard, and solving Unique Games becomes easy. ↺
4 The Survey Propagation Algorithm is a very interesting algorithm that arose from statistical physics intuition, and is experimentally better than other algorithms at solving random 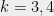
5 As further argument that reductions should increase the input length, note that if 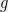
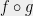
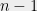
6 The notion of “chosen at random” roughly corresponds to the uniform distribution over inputs, or the uniform distribution with an “appropriately planted” satisfying assignment, with the precise notion of “estimation” being the appropriate one for these different models; see the paper for details. The Random CSP Hypothesis deals with the overconstrainted regime of random SAT formulas, as opposed to the underconstrained regime in discussed above in the the context of phase transitions. ↺
7 In some sense, such an approach to proving lower bounds is dual to Mulumley’s approach of “Geometric Complexity Theory” (GCT). (For more information about GCT, see the talks in this workshop, and also this StackExchange answer, this presentation and this paper ). The GCT approach attempts to use specific properties of structured functions such as the permanent to obtain a lower bound; these properties are actually “constructive” in the Razborov-Rudich sense of Natural Proofs. If we focused on combinatorial, “unstructured”, problems then we would need to come up with general properties guaranteeing hardness, that would also apply to random functions (which are the ultimate unstructured functions). The Razborov-Rudich result implies such properties would be inherently non-constructive. Valiant’s approach for proving certain types of lower bounds via Matrix Rigidity can be thought of as an instance of the latter approach. ↺

A very nice post. The hypothesis that good characterizations of a combinatorial optimization problem and its complement yield a good algorithm, which we would write as P=NP intersect coNP and which you seem to attribute to a quote of Lovasz actually was made by Jack Edmonds in his famous Paths, Trees, and Flowers paper in 1965. It was motivated by LP duality, but was made even before we knew that solving LP’s is in P.
Thanks Paul. I don’t attribute it to Lovasz, it’s just the one place I found an explicit quote (in his Combinatorial Problems book he says that “The existence of a good characterization tends to go hand in hand with the existence of good decision algorithms”).
I’ve heard that the notion of NP cap coNP was defined by Edmonds, but I don’t remember a discussion on it in the Paths, Trees and Flowers paper (there is an excellent discussion of the notion of “polynomial time” there) – do you know of a good reference for this discussion?
You are right. It isn’t there. What I saw was in some later work referring to Edmonds early papers and as I look at them it is pretty hard to find anything directly there. I know that I saw this conjecture explicitly in Edmonds work but it may have been later.
Great essay!
To focus on one of the issues raised, let me ask a very basic question. What’s the best result known for simulating an *arbitrary* quantum algorithm by a classical computer? If a problem in NP is known to be solvable in polynomial time by a quantum machine, is it even known whether it’s solvable in 2^{cn} time for some c<1 with a classical randomized algorithm?
That’s a good question – I don’t know the answer. While there are non-trivial simulations in terms of space (using polynomial space as opposed to the naive way which would keep track of all amplitude), I don’t know if there is any non-trivial exponential speedup.
A great post! I have a small remark regarding footnote 3: the power of a Gaussian-elimination type algorithm (called few subpowers, published by Idziak et al. in SICOMP 39(7):3023-3037, 2010) is known, see Berman et al. Trans. AMS 362(3):1445-1473, 2010, and it’s now clear that it won’t solve all remaining (open) CSPs. Few known classes combine the two techniques, few subpowers and consistency techniques, but it’s not clear that (a combination of) these two will be enough for the remaining CSPs that are conjectured to be tractable. It may need a completely new algorithmic approach!
A great post! I have a small remark regarding footnote 3: the power of a
Gaussian-elimination type algorithm (called few subpowers, published by Idziak
et al. in SICOMP 39(7):3023-3037, 2010) is known, see Berman et al. Trans. AMS
362(3):1445-1473, 2010, and it’s now clear that it won’t solve all remaining
(open) CSPs. Few known classes combine the two techniques, few subpowers and
consistency techniques, but it’s not clear that (a combination of) these two
will be enough for the remaining CSPs that are conjectured to be tractable. It
may need a completely new algorithmic approach!
Thank you! I am not really an expert on this literature – I seem to have a memory that the problematic CSP’s are those who can count, and hence require some gaussian elimination type algorithm, but indeed perhaps it’s not enough. Are there good references for this discussion of what algorithmic approaches would be needed to resolve it?
its great you cited transition point research into SAT, not everyone in complexity theory is aware of it. think it could be a rosetta stone for unlocking P≠NP, have studied it closely & think have somewhat recently pinpointed the way it interferes with Razborovs monotone circuit proofs, just looking for some expert [cyberspatial?] collaborators on that project/research program/direction/attack angle here…. also great minds think alike, scott aaronson just posted a high voted question on tcs.se along similar lines/theme of this post, overarching reasons why problems are in P
Indeed, I’ve linked to Scott’s question above.
A talk by Peter Winkler today reminded me I should have definitely also mentioned Allan Sly’s paper, that also gives some evidence as to how the threshold when the solution space geometry changes might be the same threshold as when the problem becomes computationally hard (this time in the context of the independent set problem).
Another property where combinatorial and algebraic problems seem to differ is robustness to noise. Combinatorial problems, perhaps because the algorithms are message passing or convex optimization, often seem to have similar difficulty when noise is added, while algebraic problems tend to be far more brittle, often becoming of very different complexity.
A very informative post. Thanks.
Thanks for the very interesting post!
It further encourages me to pursue hash-based digital signatures (http://pqcrypto.org/hash.html), which implement the “digital signature” operation (prove that a string was produced using knowledge of a specific secret, without revealing that secret) assuming only secure hash functions. Secure hash functions are eminently “unstructured” things. They are merely “bit blenders”.
I spent a little time trying to imagine how to get the “public key encryption” operation (encrypt so that only the holder of a specific private key can decrypt) from only secure hash functions, but didn’t get very far. David Molnar once patiently explained to me some reason why such a construction is implausible, but I didn’t understand his explanation. Such a construction would prove that we don’t live in Impagliazzo’s Minicrypt, I guess.
Merkle’s Puzzles (https://en.wikipedia.org/wiki/Merkle%27s_Puzzles) could be built solely out of secure hash functions, and they constitute public key encryption, but they give the interlocutors only a quadratic advantage over the eavesdropper. Does that mean anything about whether we live in Minicrypt?
In any case, it is interesting that of the two operations that are currently done with “structured” systems like RSA and Discrete Log — public key encryption and digital signature — one of them can be replaced by a purely “unstructured” alternative, and the other one can’t (unless quadratic advantage is good enough for you).
Impagliazzo and Rudich proved that any construction that uses (even an ideal) hash function as a black box can give at most (roughly)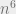 security, Mahmoody and I improved this bound to
security, Mahmoody and I improved this bound to 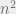 , thus proving that Merkle’s puzzle construction is optimal. Of course, this does not rule out non-black-box constructions.
, thus proving that Merkle’s puzzle construction is optimal. Of course, this does not rule out non-black-box constructions.
Thanks! In what paper did you prove this n² bound?
The paper with Mahmoody is “Merkle Puzzles are Optimal”, CRYPTO 2009. It can be found at the following link:
Click to access MerkleFull.pdf
BTW I have another paper with Mahmoody showing that any black box construction of signature schemes from hash functions will have to make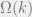 calls to the hash function where
calls to the hash function where  is the security parameter. See
is the security parameter. See
http://arxiv.org/abs/0801.3680
p.s. apologies to all commenters for the delay in moderation – for some reason I wasn’t getting the notification emails.
Beautiful essay!
A few comments:
1. You say: “In this regime no efficient algorithm is known to find the satisfying assignment, and it is possible that this is inherently hard.” This is true, but the only evidence we have is that in this reason search-based algorithms are inefficient. Our search algorithms are all based on resolution, which is a very weak proof system. Thus, there is no serious evidence that this region is inherent hard. It is also possible that this region is easy.
2. There is a class of problems in NP\cap co-NP for which we do not know any efficient algorithm. These include parity games, mean-payoff games, and stochastic games. Should we therefore assume that these problems are not in NP?
3. I think the evidence that CSP has a dichotomy is much stronger than the evidence that the theory of phase transitions offer a general approach to the complexity of combinatorial problems. Furthermore, low-density random problems are easy, even though they have no structure.
Anyway, these are just quibble.
Moshe
Thank you so much Moshe!
I agree the evidence for hardness in this region is so far very limited, and probably only a cryptographer would use it as a basis to conjecture hardness 🙂
I didn’t completely get your comment no 2 (am guessing you meant P and not NP in the end, right?). This class of problems is very interesting, and probably some of them are hard and some are easy. I would call problems in this class at least somewhat structured, and say that it’s far more challenging to get an understanding of their complexity (though notions such as PPAD-completeness and SZK-completeness are a promising direction).
I agree the evidence for CSP dichotomy is much stronger – many parts of your conjecture have already been proven and advances continue to be made. In contrast, it is not even clear what would be compelling evidence that phase transitions correspond to computational hardness (this is related to my previous post) though lower bounds for local search algorithms and hardness of approximation results such as Sly’s can be viewed as initial progress in this direction. As a side note, the easiness in the low density regime (where the solution space looks like the left side of Figure 1) corresponds to my intuition that unstructured problems are either very easy or very hard.
What I meant by comment 2 is that we have some problems in NP\cap co-NP that so far have resisted all attacks. They have structure, but I’d not rush to conjecture that they are in P. (Sorry for the typo.)
I did not mean to imply that structured problems are in P. In contrast, I think structured problems might be exactly those whose complexity is hard to determine and may be somewhere intermediate.
I just say for those problems, I am a bit more uncomfortable to conjecture they are not in P, especially if they have seen several advances in non-trivial algorithms and other non trivial structural results (most prominent example here being graph isomorphism).
We are in agreement.