I just gave the final lecture in my seminar on Sum of Squares Upper Bounds, Lower Bounds, and Open Questions. (see also this previous post). The lectures notes are available on the web page and also as a single pdf file. They are extremely rough but I hope they would still be useful, as some of this material is not covered (to my knowledge) elsewhere. (Indeed two of the papers we covered are “hot off the press”: the work of Meka-Potechin-WIgderson on the planted clique problem hasn’t yet been posted online, and the work of Lee-Raghavendra-Steurer on semidefinite extension complexity was just posted online two weeks ago.)
Some of the topics we covered included the SDP based algorithms for problems such as Max-Cut, Sparsest-Cut, and Small-Set Expansion, lower bounds for Sum-of-Squares: 3XOR/3SAT and planted clique, using SOS for unsupervised learning, how might (and of course also might not) the SOS algorithm be used refute the Unique Games Conjecture, linear programming and semidefinite programming extension complexity.
Thanks to everyone that participated in the course and in particular to the students who scribed the notes (both in this course and my previous summer course) and to Jon Kelner and Ankur Moitra that gave guest lectures!
I thought I might post here the list of open problems I ended with- feel free to comment on those or add some of your own below.
In most cases I phrased the problem as asking to show a particular statement, though of course showing the opposite statement would be very interesting as well. This is not meant to be a complete or definitive list, but could perhaps spark your imagination to think of those or other research problems of your own. The broader themes these questions are meant to explore are:
- Can we understand in what cases do SOS programs of intermediate degree (larger than
but much smaller than
) yield non-trivial guarantees?
It seems that for some problems (such as 3SAT) the degree/quality curve has a threshold behavior, where we need to get to degree roughlyto beat the performance of the degree
algorithm, while for other problems (such as UNIQUE GAMES) the degree/quality curve seems much smoother, though we don’t really understand it.
Understanding this computation/quality tradeoff in other settings, such as average case complexity, would be very interesting as well for areas such as learning, statistical physics, and cryptography. - Can we give more evidence to, or perhaps refute, the intuition that the SOS algorithm is optimal in some broad domains?
- Can we understand the performance of SOS in average-case setting, and whether there are justifications to consider it optimal in this setting as well? This is of course interesting for both machine learning and cryptography.
- Can we understand the role of noise in the performance of the SOS algorithm? Is noise a way to distinguish between “combinatorial” and “algebraic” problems in the sense of my previous post?
Well posed problems
Problem 1
Show that for every constant 
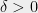
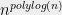


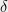
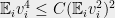

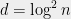
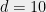
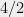
Problem 2
Show that there is some constant 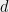


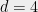
Problem 3
Show that the SOS algorithm is optimal in some sense for “pseudo-random” constraint satisfaction problems, by showing that for every predicate 
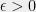

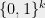

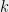


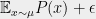
Problem 4
More generally, can we obtain a “UGC free Raghavendra Theorem”? For example, can we show (without relying on the UGC) that for every predicate 
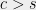

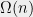



Problem 5
Show that there is some 
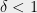

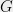
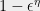
Problem 6
If you think the above cannot be done, even showing that the degree 

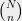
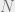
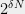
The following statement, if true, demonstrates one of the challenges in proving the soundness of KM construction: Recall that the KM boundary test takes a function 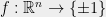



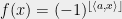
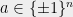
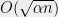
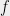

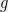

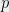
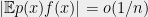
Problem 7
Show that there are some constant 

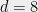

Problem 8
Give a polynomial-time algorithm that for some sufficiently small 

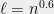


Problem 9
Improve the dictionary learning algorithm of [Barak-Kelner-Steurer] (in the setting of constant sparsity) from quasipolynomial to polynomial time.
Problem 10
(Suggested by Prasad Raghavendra.) Can SDP relaxations simulate local search?
While sum of squares SDP relaxations yield the best known approximations for CSPs, the same is not known for bounded degree CSPs. For instance, MAXCUT on bounded degree graphs can be approximated better than the Goemans-Willamson constant 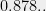

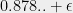
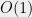

[Update: Prasad notes that the first problem for Max-Cut actually is solved as stated, since the paper also shows that the SDP integrality gap is better than
Problem 11
(Suggested by Ryan O’Donnell) Let 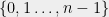

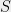

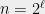
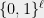
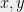
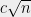



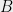
[Update: William Perry showed a degree 4 proof (using the triangle inequality) for the fact that the least expanding sets a power of the cycle. Sangxia Huang proved independently a similar result.]
Fuzzier problems
The following problems are not as well-defined, but this does not mean they are less important.
Problem A
Find more problems in the area of unsupervised learning where one can obtain an efficient algorithm by giving a proof of identifiability using low degree SOS.
Problem B
The notion of pseudo-distributions gives rise to a computational analog of Bayesian reasoning about the knowledge of a computationally-bounded observer. Can we give any interesting applications of this? Perhaps in economics? Or cryptography?
SOS, Cryptography, and 
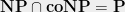

Problem C
Find some evidence to the conjecture of Barak-Kindler-Steurer (or other similar conjectures) that the SOS algorithm might be optimal even in an average case setting. Can you find applications for this conjecture in cryptography?
Problem D
Can we use a conjectured optimality of SOS to give public key encryption schemes? Perhaps to justify the security of LWE? One barrier for the latter could be that breaking LWE and related lattice problems is in fact in
Problem E
Understand the role of noise in the performance of the SOS algorithm. The algorithm seems to be inherently noise robust, and it also seems that this is related to both its power and its weakness– as is demonstrated by cases such as solving linear equations where it cannot get close to the performance of the Gaussian elimination algorithm, but the latter is also extremely sensitive to noise.
Can we get any formal justifications to this intuition? What is the right way to define noise robustness in general? If we believe that the SOS algorithm is optimal (even in some average case setting) for noisy problems, can we get any quantitative predictions to the amount of noise needed for this to hold? This may be related to the question above of getting public key cryptography from assuming the optimality of SOS in the average case (see Barak-Kindler-Steurer and Applebaum-Barak-Wigderson).
Problem F
Related to this: is there a sense in which SOS is an optimal noise-robust algorithm or proof system? Are there natural stronger proof systems that are still automatizable (maybe corresponding to other convex programs such as hyperbolic programming, or maybe using a completely different paradigm)? Are there natural noise-robust algorithms for combinatorial optimizations that are not captured by the
SOS framework? Are there natural stronger proof systems than SOS (even non
automatizable ones) that are noise-robust and are stronger than SOS for natural combinatorial optimization problems?
Can we understand better the role of the feasible interpolation property in this context?
Problem G
I have suggested that the main reason that a “robust” proof does not translate into an SOS proof is by use of the probabilistic method, but this is by no means a universal law and getting better intuition as to what types of arguments do and don’t translate into low degree SOS proofs is an important research direction. Ryan O’Donnell’s problems above present one challenge to this viewpoint. Another approach is to try to use techniques from derandomization such as use of additive combinatorics or the Zig-Zag product to obtain “hard to SOS” proofs. In particular, is there an SOS proof that the graph constructed by Capalbo, Reingold, Vadhan and Wigderson (STOC 2002) is a “lossless expander” (expansion larger than 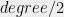

Let me add a couple of comments.
1. I feel like I say this comment every time I chat with Boaz about SOS, but I’ll say it one more time 🙂 The fact that sublinear-degree SOS cannot refute random 3SAT has **nothing** to do with whether or not “Chernoff+union bound” is SOS-able or not SOS-able. That is a totally irrelevant issue. To try to say it another way, imagine an alternate universe where there *is* a low-degree SOS proof of Chernoff bounds or, Chernoff+union-bounds, or whatever. Now I pick a typical random 3SAT instance, call it H, and ask you to refute it with low-degree H. What are you going to do?
The fact that you can SOS-prove that 99.9% of random 3SAT instances are unsatisfiable in no way helps you prove that *this specific* H is unsatisfiable.
Indeed, I distinguish between two kinds of SOS lower bounds: a) those, like Grigoriev’s “Knapsack” lower bound and random-3XOR-perfect-satisfiability lower bound, where low-degree SOS fails even though we know simple proofs in other proof systems; b) those, like the random-3SAT lower bounds or the planted clique lower bounds, where low-degree SOS fails because *we expect that every proof system fails*. Results of type (a) are interesting because they show actual limitations of SOS per se; results of type (b) are interesting because they are example confirmations of our belief that all proof systems fail, even the quite strong proof system SOS.
Going back to random 3SAT, when you pick a random instance H, one of three things can happen:
i) with negligible probability, H is miraculously satisfiable;
ii) with (presumably) low (inverse-poly) probability, H is unsatisfiable but for an unusually simple reason (e.g., you happened to pick all 8 possible SAT constraints on the literals associated with x1,x2,x3);
iii) with (presumably) all the rest of the probability, H is unsatisfiable but *there is no succinct reason why it’s unsatisfiable*.
In case (iii), neither constant-degree SOS, nor poly-size Cutting Planes, nor poly-size Extended Frege, nor even poly-size ZFC (presumably) can show that H is unsatisfiable. So it’s not really an SOS thing per se, and it has nothing to do with the SOS-izability or non-SOS-izability of Chernoff.
2. This comment is kind of a joint observation/problem with Sangxia Huang (also based on ideas told to me by Yuan Zhou); hope he doesn’t mind me posting it. Say you are an algorithmicist trying to use constant-degree SOS on your favorite CSP-maximization instance H with m constraints. Perhaps you ask SOS for the optimum value and it returns to you k = (3/4)m. At first you think to yourself, “OK, well, I know the true maximum is at most k; perhaps I can round my SOS solution to get a genuine solution satisfying close to k constraints.” But what I claim you should actually do next is say, “OK SOS, you claim the optimum value is k, huh? What do you say if I take the instance H and add “OBJECTIVE = k” as an SOS constraint?” I kind of feel that in many cases, SOS will now return “infeasible” for this augmented instance. And then you know the true optimum is actually at most k-1.
Indeed, instead of using SOS to maximize an objective subject to (typically) X_i^2 = X_i for all i, you should try all SOS-feasibility instances of the form constraints + “OBJ = k” for all 0 <= k <= m. Seems quite natural, no?
The *flip* side to this is that if you are proving SOS lower bounds, and you show that there is a pseudo-solution where the objective function has pseudo-expectation at least k, even though the true optimum is k' = (1/4 – o(1))m, or even = (1/4)m?
At first we thought: “Sure. Just take the Grigoriev/Schoenebeck pseudodistribution; it’s easy to see that when you look at the pseudoexpectation of the objective function, it’ll be exactly (1/4)m.” But… I do not know how to show that this pseudoexpectation will actually SOS-satisfy the constraint “OBJ = (1/4)m”. Indeed, I do not know how to construct any number k >= (1/4 – o(1))m together with a pseudoexpectation which SOS-satisfies the constraint “OBJ = k”.
Hi Ryan,
1) Regarding your first comment, I am trying to understand if this is a technical or philosophical issue. I think this is a great point (which I keep forgetting and should have emphasized in the seminar more) that if you want to come up with an unsatisfiable SAT instance I for which there exists no short proof that I is unsatisfiable, then *you* better have no proof for this as well. And so, the best approach we have for such constructions is to use the probabilistic method so we generate an instance I that is only unsatisfiable with high probability, and so we ourselves don’t have a proof it’s unsatisfiable.
But, that said, this is a necessary condition for not having a proof in general, but it’s not a sufficient condition even for not having SOS proofs. In particular, if you used >> n^{1.5} random clauses then there will be an SOS proof of unsatisfiability.
I do believe that part of the “reason” is that when you do the Chernoff+union bound argument then if you open up Chernoff to a bound on moments, then you need to consider very large moments (of linear size) and this is the reason this proof doesn’t translate into an SOS proof, or perhaps more accurately, this is the reason the proof that an instance is unsatisfiable w.h.p. doesn’t also show that an instance has a low degree SOS proof of unsatisfiability w.h.p I guess to see if what I say makes sense one should see if one can find a natural way to extract the existence of an Omega(n) degree SOS proof of unsatisfiability from the chernoff+union bound argument.
2) Your second point is another excellent one. Taking the viewpoint of pseudo-distributions, (which as usual I like to pretend are actual distribubtions) I think you are distinguishing between the case that the objective value is (3/4)m in expectation and the case that it satisfies this with probability 1. I do agree the latter is often more natural to think of. Another way to state that a pseudo expectation E satisfies the constraint P=0 with probabilty 1 (when P is a polynomial) is to require that E P^2 = 1.
I actually think that the Gregoriev/Schoenebeck pseudo-distribution do satisfy that the objective value is m with probability 1 (since its expectation is m, and it cannot be larger than m, this must hold if it was an actual distribution, and I think that E (val-m)^2 = 0 can be shown to hold)
I must confess I still have no idea what you’re saying with respect to point 1. Re the number of constraints, yes, I’m assuming we’re working with m = Cn constraints for C a large constant. The point is that in this regime, a random 3SAT instance is not just unsatisfiable with high probability — rather, experts like Pudlak or Santhanam or Feige or whoever would conjecture that “with high probability it’s unsatisfiable for an *incomprehensible/non-succinct global reason*”. Whereas once m >> n^{1.5}, your Coja-Oghlans and your Feige-Ofeks have indeed shown that for a random 3SAT instance there is a *comprehensible/succinct* — albeit still global — reason why it’s unsatisfiable. (Basically, there’s a spectral proof. And indeed SOS can find it, as can a suitably set up “GW/basic SDP”.) Incidentally, once m >> n^2, there are even simple *local* reasons for unsatisfiability (whp).
But your last paragraph I don’t understand at all. If you could somehow efficiently certify that a particular 3SAT instance with Cn clauses was both: a) generated at random; b) was not atypical of this random generation; *then* I’d believe that Chernoff-bound-proof-complexity had something to do with SOS-refutability-of-most-random-3SAT instances. But surely that certification task is not doable (nor even well-posed, really).
Let me put it another way. If you go to “my homepage / my-instance.cnf” you’ll find a 3SAT instance with n = 10,000 and m = 160,000 I just created. I personally swear to you on my honor that I generated it at random, in the usual way. I solemnly swear it. Now: can you, Boaz Barak, find any proof of its unsatisfiability written in any mathematical language using at most 10,000,000 symbols? Probably not, right? But it’s not because you, Boaz Barak, do not know how to prove the Chernoff bound (you do). It’s because probably no such proof exists.
(Here the word “probably” is encompassing two things: 1. The probability that my-instance.cnf really is unsatisfiable, and not for a flukishly simple reason. 2. The correctness of the general “AvgNP \not \subset co-NP”-ish type belief about random 3SAT held by most complexity experts; you know, roughly the belief that the Alekhnovitch cryptosystem is secure even against coNP attacks.)
PS: re point number 2, yes indeed the Grigoriev/Schoenebeck pseudodistribution has objective value m “with probability 1” as you say, which is why I count these as legitimate SOS lower bounds. On the other hand, I do not know how to show that a random 3AND instance has objective value m/4 “with probability 1”.
(Re my-instance.cnf, let me add that “very probably” there is no low-degree SOS proof that it’s unsatisfiable. Here “very probably” ONLY refers to the probability that my-instance.cnf has the typical amount of expansion. By virtue of Grigoriev’s paper, one doesn’t need to have any other “probably-true-but-unsubstantiated” beliefs about hardness-on-average of 3SAT.)
Re point 2, indeed I think giving a “probability 1” lower bound for random 3AND is a great suggestion for another open problem.
Re point 1, let me try to clarify things. Like I said, I am not sure we have a technical disagreement. I was merely proposing an empirical heuristic as to when we should expect looking at a proof in a paper that, say, a formula from some distribution is unsatisfiable, that this proof would actually show that the SOS algorithm certifies this with low degree, and when we should be worried that this would not be the case. The point is not whether I (or the SOS algorithm) can prove the Chernoff bound, but that the Chernoff bound does not yield as a corollary the existence of a low degree proof, while other techniques (such as those used to show unsatisfiability of denser formulas) do.
Let me try to elaborate more, in the hope of not confusing things even further. For starters, I do believe in the “average case NP\neq coNP” conjecture of Feige et al, so I do not believe there is *any* succinct proof for the instance you generated (even without actually seeing it – I got a 404 error at http://www.cs.cmu.edu/~odonnell/my-instance.cnf ). My point was different.
Whenever you prove that a random formula f is unsatisfiable w.h.p., you actually prove that w.h.p. f has some deterministic property P which implies that f is unsatisfiable. (This of course can be satisfied vacuously but please bear with me.) Now, in some cases, such as in the spectral proof that an m^{1.5} clause formula is unsatisfiable, it turns out that the proof establishes a strong property P that also implies the existence of a constant degree SOS proof that f is unsatisfiable. I was trying to say that if you wanted to look at an actual proof and guess whether it’s likely to implicitly yield such a property P, the clearest markers of trouble are the use of Chernoff+Union bound arguments.
Specifically, in the case of Chernoff+Union bound arguments, the proof is essentially a high degree Markov argument. That is, one defines some non-negative polynomial Q (of degree O(n) ) that takes as input both the coefficients f defining the formula and the n variables x_1…x_n defining the assignments, and you show that on one hand for fixed x and random f, E Q(f,x)=1 and on the other hand if x satisfies f then Q(f,x) > 100^n . (You can let Q(x,f) be the twice the fraction of satisfied constraints raised to the power 10n.) Then we can use Markov to argue that the probability for every x that x satisfies f is 100^{-n} and so we can use the union bound over all 2^n choices for x.
Now I didn’t verify this but I think that for a fixed random f we will in fact have an SOS proof to bound this polynomial and show that Q(f,x) << 100^n for every x. The problem is that this SOS proof will have degree comparable to the degree of Q which is of course very large. (BTW the degree of the SOS transitions smoothly from Omega(n) degree for O(n)-constraint formulas to O(1) degree for O(n^{1.5})-constraint formulas; it might be interesting to understand whether there is a natural way to get a similar transition from the chernoff+union bound proof to the spectral proof.)
OK, I more or less accept your point, thanks.
PS: OK, I didn’t actually make my-instance.cnf 🙂
That’s a shame, I was going to assign it as a take home exam 🙂