[Note: As I commented on Omer’s touching post, I too was shocked by the sudden closure of the amazingly successful MSR Silicon Valley lab. I hope that this blog, whose contents had very little to do with MSR itself and everything to do with the great group of people that was there, would continue to flourish on, independently of its former MSR connection.]
I am teaching a seminar series at MIT with the title above, and thought I would post the introduction to the course here. For the complete notes on the first lecture (and notes of future lectures), please see the course webpage, where you can also sign up for the mailing list to get some future updates. While the SOS algorithm is widely studied and used for a great many applications (see for example the courses of Parrilo and Laurent and the book of Lasserre) , this seminar will offer a different perspective of theoretical computer science. One tongue-in-cheek tagline for this course can be
Rescuing the Sum-of-Squares algorithm from its obscurity as an algorithm that keeps planes up in the sky into a way to refute computational complexity conjectures.
Prelude
Consider the following questions:
- Do we need a different algorithm to solve every computational problem, or can a single algorithm give the best performance for a large class of problems?
- In statistical physics and other areas, many people believe in the existence of a computational threshold effect, where a small change in the parameters of a computational problems seems to lead to a huge change in its computational complexity. Can we give rigorous evidence for this intuition?
- In machine learning there often seem to be tradeoffs between sample complexity, error probability, and computation time. Is there a way to map the curve of this tradeoff?
- Suppose you are given a 3SAT formula
with a unique (but unknown) satisfying assignment
. Is there a way to make sense of statements such as “The probability that
is
” or “The entropy of
“?
- (even though of course information theoretically
or
and
- Is Khot’s Unique Games Conjecture true?
If you learn the answers to these questions by the end of this seminar series, then I hope you’ll explain them to me, since I definitely don’t know them. However we will see that, despite these questions a-priori having nothing to do with Sums of Squares, that the SOS algorithm can yield a powerful lens to shed light on some of those questions, and perhaps be a step towards providing some of their answers.
Introduction
Theoretical computer science studies many computational models for different goals. There are some models, such as bounded-depth (i.e. 

The Sum of Squares (SOS) algorithm (discovered independently by researchers from different communities including Shor, Parrilo, Nesterov and Lasserre) can be thought of as another example of a concrete computational model. On one hand, it is sufficiently weak for us to know at least some unconditional lower bounds for it. In fact, there is a sense that it is weaker than
The possibility of the existence of such an optimal algorithm is very exciting. Even if at the moment we can’t hope to prove its optimality unconditionally, this means that we can (modulo some conjectures) reduce analyzing the difficulty of a problem to analyzing a single algorithm, and this has several important implications. For starters, it reduces the need for creativity in designing the algorithm, making it required only for the algorithm’s analysis. In some sense, much of the progress in science can be described as attempting to automate and make routine and even boring what was once challenging. Just as we today view as commonplace calculations that past geniuses such as Euler and Gauss spent much of their time on, it is possible that in the future much of algorithm design, which now requires an amazing amount of creativity, would be systematized and made routine. Another application of optimality is automating hardness results— if we prove the optimal algorithm can’t solve a problem X then that means that X can’t be solved by any efficient algorithm.
Beyond than just systematizing what we already can do, optimal algorithms could yield qualitative new insights on algorithms and complexity. For example, in many problems arising in statistical physics and machine learning, researchers believe that there exist computational phase transitions— where a small change in the parameter of a problems causes a huge jump in its computational complexity. Understanding this phase transitions is of great interest for both researchers in these areas and theoretical computer scientists. The problem is that these problems involve random inputs (i.e., average case complexity) and so, based on current state of art, we have no way of proving the existence of such phase transitions based on assumptions such as 

Perhaps the most exciting thing is that an optimal algorithm gives us a new understanding of just what is it about a problem that makes it easy or hard, and a new way to look at efficient computation. I don’t find explanations such as “Problem A is easy because it has an algorithm” or “Problem B is hard because it has a reduction from SAT” very satisfying. I’d rather get an explanation such as “Problem A is easy because it has property P” and ”Problem B is hard because it doesn’t have P” where P is some meaningful property (e.g., being convex, supporting some polymorphisms, etc..) such that every problem (in some domain) with P is easy and every problem without it is hard. For that, we would want an algorithm that will solve all problems in P and a proof (or other evidence) that it is optimal. Such understanding of computation could bear other fruits as well. For example, as we will see in this seminar series, if the SOS algorithm is optimal in a certain domain, then we can use this to build a theory of “computational Bayesian reasoning” that can capture the “computational beliefs” of a bounded-time agent about a certain quantity, just as traditional Bayesian reasoning captures the beliefs of an unbounded-time agent about quantities on which it is given partial information.
I should note that while much of this course is very specific to the SOS algorithms, not all of it is, and it is possible that even if the SOS algorithm is superseded by another one, some of the ideas and tools we develop will still be useful. Also, note that I have deliberately ignored the question of what family of problems would the SOS be optimal for. This is clearly a crucial issue— every computational model (even
In this course we will see:
- A description of the SOS algorithm from different viewpoints— the traditional semidefinite programming/convex optimization view, as well as the proof system view, and the “pseudo-distribution” view.
- Discussion of positive results (aka “upper bounds”) using the SOS algorithms to solve graph problems such as sparsest cut, and problems in machine learning.
- Discussion of known negative results (aka “lower bounds” / “integrality gaps”) for this algorithm.
- Discussion of the interesting (and not yet fully understood) relation of the SOS algorithm to Khot’s Unique Games Conjecture (UGC). On one hand, the UGC implies that the SOS algorithm is optimal for a large class of problems. On the other hand, the SOS algorithm is currently the main candidate to refute the UGC.
2. Polynomial optimization
The SOS algorithm is an algorithm for solving a computational problem. Let us now define what this problem is:
Definition 1 A polynomial equation is an equation of the form
(in which case it is called an
inequality) or an equation of the form(in which case it is called an equality) where
is a multivariate polynomial
mappingto
. The equation
) is satisfied by
(resp.
).
A set
of polynomial equations is satisfiable if there exists an
that satisfies all equations in
The polynomial optimization problem is to output, given a set
(Note: throughout this seminar we will ignore all issues of numerical accuracy— assume the polynomials always have rational coefficients with bounded numerator and denominator, and all equalities/inequalities can be satisfied up to some small error 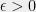
Here are some examples for polynomial optimization problems:
- Linear programming If all the polynomials are linear then this is of course linear programming that can be done in polynomial time.
- Least squares If the equations consist of a single quadratic then this is the least squares algorithm. Similarly, one can capture computing eigenvalues by two quadratics.
- 3SAT Can encode 3SAT formula as degree 3 polynomial equations: the equation
is equivalent to
.
The equationis equivalent to
.
- Clique Given a graph
the following equations encode that
indicator vector of a
-clique:
,
for all
.
The SOS algorithm is designed to solve the polynomial optimization problem. As we can see from these examples, the full polynomial optimization problem is NP hard, and hence we can’t expect SOS (or any other algorithm) to efficiently solve it on every instance.
Exercise 1: prove that this is the case even if all polynomials are quadratic, i.e. of degree at most 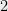
Understanding how close the SOS algorithm gets in particular cases is the main technical challenge we will be dealing with.
These examples also show that polynomial optimziation is an extremely versatile formalism, and many other computational problems (including SAT and CLIQUE) can be directly and easily phrased as instances of it. Henceforth we will ignore the question of how to formalize a problem as a polynomial optimization, and either assume the problem is already given in this form, or use the simplest most straightforward translation if it isn’t. While there are examples where choosing between different natural formulations could make a difference in complexity, this is not the case (to my knowledge) in the questions we will look at.
Note: We can always assume without loss of generality that all our equations are equalities, since we can always replace the equation 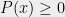

Also, we sometimes will ask the question of minimizing (or maximizing) a polynomial 
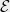


3. The SOS algorithm
The Sum of Squares algorithm is an algorithm to solve the polynomial optimization problem. Given that it is NP hard, the SOS algorithm cannot run in polynomial time on all instances. The main focus of this course is trying to understand in which cases the SOS algorithm takes a small (say polynomial or quasipolynomial) amount of time, in which cases it takes a large (say exponential) amount. An equivalent form of this question (which is the one we’ll mostly use) is that, for some small 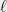
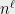
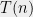
In fact, we will see that for every value of
Definition 2 (Sum of Squares – informal definition)
The SOS algorithm gets a parameterand a set of equations
and outputs either:
- An object we will call a “degree-
- A proof that a solution doesn’t exist.
We will later make this more precise: what is exactly a degree-
History. [Note: this is mostly from memory and not from the primary sources, so doublecheck this before quoting elsewhere. The introduction of this paper of O’Donnell and Zhou is a good starting point for the hisroty.] The SOS algorithm has its roots in questions raised in the late 

In his famous 2000 address, Hilbert asked as his 17th problem whether any polynomial can be represented as a sum of squares of rational functions. (For example, Motzkin’s polynomial (1) can be shown to be the sum of squares of (I think) four rational functions of denominator and numerator degree at most 



In the late 90’s / early 2000’s, there were two separate efforts on getting quantitative or algorithmic versions of this result. On one hand Grigoriev and Vorobjov asked the question of how large the degree of an SOS proof needs to be, and in particular Grigoriev proved several lower bounds on this degree for some interesting polynomials. On the other hand Parrilo and Lasserre (independently) came up with hierarchies of algorithms for polynomial optimization based on the Positivstallensatz using semidefinite programming. (Something along those lines was also described by Naum Shor in a 1987 Russian paper, and mentioned by Nesterov as well.)
It took some time for people to realize the connection between all these works, and in particular the relation between Grigoriev-Vorbjov’s work and the works from the optimization literature took some time to be discovered, and even 10 years after, it was still the case that some results of Grigoriev were rediscovered and reproven in the Lasserre language.
Applications of SOS SOS has applications to: equilibrium analysis of dynamics and control (robotics, flight controls, …), robust and stochastic optimization, statistics and machine learning, continuous games, software verification, filter design, quantum computation and information, automated theorem proving, packing problems, etc…

Remark: the TCS vs Mathematical Programming view of SOS
While the SOS algorithm is intensively studied in several communities, there are some differences in emphasizes between the different aspects. While I am not an expert on all SOS works, my impression is that the main characteristics of the TCS viewpoint as opposed to others are:
- In the TCS world, we typically think of the number of variables
and the degreeof the SOS algorithm as being relatively small— a constant or logarithmic.
In contrast, in the optimization and control world, the number of variables can often be very small (e.g. around ten or so, maybe even smaller) and hance, even
and
would take something like a petabyte of memory (in practice, though we didn’t try to optimize too much, David Steurer and I had a hard time executing a program with
and
on a Cornell cluster).
This may justify the optimization/control view of keeping - Typically in TCS our inputs are discrete and the polynomials are simple, with integer coefficients etc. Often we have constraints such as
- Traditionally people have been concerned with exact convergence of the SOS algorithm—- when does it yield an exact solution to the optimization problem. This often precludes
4. Several views of the SOS algorithm
We now describe the SOS algorithm more formally. For simplicity, we consider the case that the set
4.1. SOS Algorithm: convex optimization view
We start by presenting one view of the SOS algorithm, which technically might be the simplest, though perhaps at first not conceptually insightful.
Definition 3 Let
denote the set of
-variate polynomials of degree at most
. Note that
this is a linear subspace of dimension roughly.
We will sometimes also write this as
where we want to emphasize that these polynomials take the formal input
.
Definition 4 Let
be a set of polynomial equations where
for all
.
Letbe some integer multiple of
. The degree-
bilinear operatorsatisfying:
- Normalization:
(where
is simply the polynomial
).
- Symmetry: If
satisfy
then
.
- Non-nonnegativity (positive semi definiteness): For every
,
.
- Feasibility: For every
,
,
,
.
Exercise 2: Show that if the symmetry and feasibility constraints hold for monomials they hold for all polynomials as well.
Exercise 3: Show that the set of 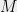
Indeed, such an 

The question is why does this have anything to do with solving our equations, and one answer is given by the following lemma:
Lemma 5 Suppose that
satisfying the conditions above.
Proof: Let 

that

Since the set of such operators 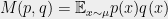
For this reason we will call 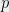

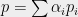



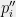
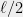
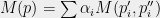
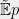
Exercise 4: Show that
4.2. Intuition- the Boolean cube
To get some intuition, we now focus attention about the special case that our goal is to maximize some polynomial 


This case is not so special in the sense that (a) it captures much of what we want to do in TCS and (b) the intuition it yields largely applies to more general settings.
Recall that we said that for every distribution 
Definition 6 A function
is a degree-
satisfies:
- Normalization:
.
- Restricted non-negativity: For every polynomial
,
,
where we defineas
.
Note that if
Exercise 5: Show that a degree 
Exercise 6: Show that if 
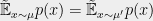

of
Exercise 7: Show that for every polynomial 



Therefore, we can say that the degree-
explicit proof of this fact that has a natural interpretation.
Exercise 8: (optional– for people who have heard about the Sherali-Adams linear programming hierarchy) Show that the variant of pseudo-distributions where we replace the condition that expectation is non-negative on all squares of degree
Are all pseudo-distributions distributions?
For starters, we can always find a distribution matching all the quadratic moments.
Lemma 7 (Gaussian Sampling Lemma) Let
.
Then there exists a distributionover
such that for every polynomial
of degree at most,
. Moreover,
is a (correlated) Gaussian distribution.
Note that even if 

Unfortunately, we don’t have an analogous result for higher moments:
Exercise 9: Prove that if there was an analog of the Gaussian Sampling Lemma for every polynomial 
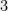
Unfortunately, this will not be our way to get fame and fortune:
Exercise 10: Prove that there exists a degree 
5. Sum of Square Proofs
As we said, when the SOS algorithm outputs \texttt{‘fail’} this can be interpreted as a proof that the system of equations is unsatisfiable. However, it turns out this proof actually has a special form that is known as an SOS proof or positivstenelsatz.
An SOS proof uses the following rules of inference

They should be interpreted as follows. If you know that a set of conditions 

Definition 8
Letvia a degree-
denoted, if
can be inferred from the constraints in
a sequence of applications of the rules above where all intermediate polynomials are of syntactic degree.
The syntactic degree of the polynomials in
(resp.
) is equal to the maximum (resp. the sum ) of the syntactic degrees of
.
That is, the syntactic degree tracks the degrees of the intermediate polynomials without accounting for
cancellations.
(Note: If we kept track of the actual degree instead of the syntactic degree we get a much stronger proof system for which we don’t have a static equivalent form, and can prove some things that the static system cannot. See the paper of Grigoriev, Hirsch and Pasechnik for discussion of this other system.)
Definition 9
Letof polynomial equalities.
We say that.
It turns out that a degree-
Exercise 11: For every 

has a degree-
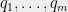




where 
(It’s OK if you lose a bit in each direction, i.e., in the if direction it could be that 

Exercise 12: Show that we can take 

Exercise 13}: Show that the set 
Positivstellensatz (Stengle 64, Krivine 74): For every unsatisfiable system
Exercise 14: Prove P-satz for systems that include the constraint 

In all TCS applications I am aware of, it’s easy to show that the SOS algorithm will solve the problem in exponential time. )
Exercise 15: Show that if there exists a degree-
degree-
SOS Theorem (Shor, Nesterov, Parrilo, Lasserre)} Under some mild conditions (see Theorem 2.7 in my survey with Steurer),
there is an
- A degree-
consistent with
- A degree-
6. Discussion
The different views of pseudo distributions: The notion of pseudo-distribution is somewhat counter-intuitive and takes a bit of time to get used to. It can be viewed from the following perspectives:
- Pseudo-distributions is simply a fancy name for a PSD matrix satisfying some linear constraints, which is the dual object to SOS proofs.
- SOS proofs of unbounded degree is a sound and complete proof system in the sense that they can prove
any true fact (phrased as polynomial equations) about actual distributions over.SOS proofs of degree
- In statistical learning problems (and economics) we often capture our knowledge (or lack thereof) by a distribution.
If an unknown quantityis selected and we are given the observations
by a the distribution.
In computational problems, often the observations
can still capture our “computational knowledge”. - The proof system view can also be considered as a way to capture our limited computational abilities.
In the example above, a computationally unbounded observer can deduce from the observations
and hence completely determine
Lessons from History It took about 80 years from the time Hilbert showed that polynomials that are not SOS exist non-constructively until Motzkin came up with an explicit example, and even that example has a low degree SOS proof of positivity. One lesson from that is the following:
“Theorem”: If a polynomial
not including probabilistic method), then there should be a low degree SOS proof for this fact.
Corollary (Marley, 1980): If you analyze the performance of an SOS based algorithm pretending pseudo-distributions
are actual distributions, then unless you used Chernoff+union bound type arguments, then every little thing gonna be alright.
We will use Marley’s corollary extensively in analyzing SOS algorithms. That is, we will pretend that the pseudo-distributions are actual distributions, and then cross our fingers and hope that our analysis will carry over when the algorithm actually works with pseudo-distributions. Thus one can think of pseudo-distributions as a “non type safe” notation that perhaps is not always sound, but makes it easier to phrase and prove theorems that we might not be able to do otherwise.
There is a recurring theme in mathematics of “power from weakness”. For example, we can often derandomize certain algorithms by observing that they fall in some restricted complexity classes and hence can be fooled by certain pseudorandom generator. Another example, perhaps closer to ours, is that even though the original way people defined calculus with “infitesimal” amounts were based on false permises, still much of the results they deduced were correct. One way to explain this is that they used a weak proof system that cannot prove all true facts about the real numbers, and in particular cannot detect if the real numbers are replaced with an object that does have such an “infitesimal” quantity added to it. In a similar way, if you analyze an algorithm using a weak proof system (e.g. one that is captured by a small degree SOS proof), then the analysis will still hold even if we replaced actual distributions with a pseudo-distribution of sufficiently large degree.

Dear Boaz Barak,
In definition 6, should the definition of E_{x\sim \mu} f(x) be \sum_{x\in {1,-1}^n} \mu(x)f(x) ?
Thank you,
Son P.
You are right – thanks!