In the last post we discussed some questions about discrepancy and the ‘Six Standard Deviations Suffice’ theorem stated below (without the 
Theorem 1 For vectors
, there exists
such that for every
,
.
In this post (second and the most technical of the three post series) we will see a proof of the above result. The theorem was proved by Spencer in 1985 using Beck’s partial coloring approach. Independently of Spencer, the result was proved by Gluskin in 1988 in a convex geometric context. Here we will review Gluskin’s proof which is quite beautiful.
Gluskin’s proof will also give us an excuse to look at some elegant (and simple to describe) results in convex geometry which may be of use elsewhere. Finally, the geometric view here will actually be useful in the next post when we discuss an algorithmic proof. Gluskin’s paper is truly remarkable and seems to reinvent several key ideas from scratch such as Sidak’s lemma, a version of Kanter’s lemma for Gaussians in convex geometry and even has the partial coloring approach implicit in it. I recommend taking a look at the paper even if it is a bit of a tough read. Much of the content in the post is based on discussions with Shachar Lovett and Oded Regev, but all mistakes are mine.
Gluskin’s proof follows the partial coloring approach with the crucial lemma proved using a volume argument. The partial coloring method was introduced by Beck in 1981 and all proofs of Theorem 1 and many other important discrepancy results in fact use this method. Here, instead of looking for a 

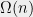
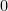
Lemma 2 For vectors
such that for every
and
.
To prove the above partial-coloring-lemma, let us first rephrase the problem in a geometric language. Let 



![\displaystyle \mathcal{K} = \{x: |\langle a^j,x\rangle| \leq \Delta, \forall j \in [n]\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BK%7D+%3D+%5C%7Bx%3A+%7C%5Clangle+a%5Ej%2Cx%5Crangle%7C+%5Cleq+%5CDelta%2C+%5Cforall+j+%5Cin+%5Bn%5D%5C%7D.&bg=eeeeee&fg=000000&s=0&c=20201002)
We want to show that 
![{\mathcal{K} \cap [-1,1]^n}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BK%7D+%5Ccap+%5B-1%2C1%5D%5En%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
I don’t have a clear intuitive reason for why the Gaussian distribution is better than the Lebesgue measure in this context. But if one looks at the analysis, a clear advantage is that projections behave better (when considering volumes) in the Gaussian space. For example, if we take a set like 
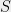
We next go over all the main pieces in Gluskin’s proof.
Sidak’s Lemma Suppose we have a standard Gaussian vector 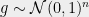
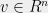
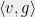



Lemma 3 (Sidak’s Lemma) Let
,
![\displaystyle Pr\left[|\langle v_1,g\rangle| \leq t_1 \;\wedge\; |\langle v_2,g\rangle| \leq t_2\;\wedge\; \cdots \;\wedge\; |\langle v_m,g\rangle| \leq t_m\right] \geq](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr%5Cleft%5B%7C%5Clangle+v_1%2Cg%5Crangle%7C+%5Cleq+t_1+%5C%3B%5Cwedge%5C%3B+%7C%5Clangle+v_2%2Cg%5Crangle%7C+%5Cleq+t_2%5C%3B%5Cwedge%5C%3B+%5Ccdots+%5C%3B%5Cwedge%5C%3B+%7C%5Clangle+v_m%2Cg%5Crangle%7C+%5Cleq+t_m%5Cright%5D+%5Cgeq+&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\; Pr\left[|\langle v_1,g\rangle |\leq t_1\right] \cdot Pr\left[|\langle v_2,g\rangle|\leq t_2\right] \cdots Pr\left[|\langle v_m,g\rangle|\leq t_m\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B+Pr%5Cleft%5B%7C%5Clangle+v_1%2Cg%5Crangle+%7C%5Cleq+t_1%5Cright%5D+%5Ccdot+Pr%5Cleft%5B%7C%5Clangle+v_2%2Cg%5Crangle%7C%5Cleq+t_2%5Cright%5D+%5Ccdots+Pr%5Cleft%5B%7C%5Clangle+v_m%2Cg%5Crangle%7C%5Cleq+t_m%5Cright%5D.+&bg=eeeeee&fg=000000&s=0&c=20201002)
The proof of the lemma is actually not too hard and an excellent exposition can be found in this paper.
The lemma is actually a very special case of a longstanding open problem called the Correlation Conjecture. Let me digress a little bit to state this beautiful question. In the above setup, let slab 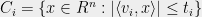
![\displaystyle Pr[g \in C_1 \wedge C_2 \wedge \cdots \wedge C_m] \geq Pr[g \in C_1] \cdot Pr[g \in C_2] \cdots Pr[g \in C_m].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr%5Bg+%5Cin+C_1+%5Cwedge+C_2+%5Cwedge+%5Ccdots+%5Cwedge+C_m%5D+%5Cgeq+Pr%5Bg+%5Cin+C_1%5D+%5Ccdot+Pr%5Bg+%5Cin+C_2%5D+%5Ccdots+Pr%5Bg+%5Cin+C_m%5D.&bg=eeeeee&fg=000000&s=0&c=20201002)
The correlation conjecture asserts that this inequality is in fact true for all symmetric convex sets (in fact, we only need to look at 
Kanter’s Lemma The second inequality we need is a comparison inequality due to Kanter. The lemma essentially lets us lift certain relations between two distributions 

Let 
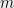
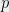




Kanter’s lemma says that the peakedness relation tensorises provided we have unimodality. A univariate distribution is unimodal if the corresponding probability density function has a single maximum and no other local maxima. I won’t define what it means for a multivariate distribution to be unimodal here, but we only need the lemma for univariate distributions. See this survey for the formal definition.
Lemma 4 (Kanter’s lemma) Let
such that
be a unimodal distribution on
,
on
, satisfy
.
The proof of the lemma is not too hard, but is non-trivial in that it uses the Brunn-Minkowski’s inequality. Combining the above lemma with the not-too-hard fact that the standard Gaussian distribution is less peaked than the uniform distribution on ![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
 .
. Minkowski’s Theorem The final piece we need is the classical Minkowski’s theorem form lattice geometry:
Theorem 6 (Minkowski’s Theorem) Let
be a symmetric convex set of Lebesgue volume more than
for an integer
. Then,
contains at least
points from the integer lattice
.
Putting Things Together We will prove the partial coloring lemma Lemma 2. The proof will be a sequence of simple implications using the above lemmas. Recall the definition of
Our goal (Lemma 2) is equivalent to showing that 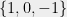
Note that 
![\displaystyle Pr[g \in \mathcal{K}] \geq \prod_{j=1}^n Pr[|\langle a^j,g\rangle| \leq \Delta] \geq \prod_{j=1}^n\left(1-2\exp(-\Delta^2/2n)\right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr%5Bg+%5Cin+%5Cmathcal%7BK%7D%5D+%5Cgeq+%5Cprod_%7Bj%3D1%7D%5En+Pr%5B%7C%5Clangle+a%5Ej%2Cg%5Crangle%7C+%5Cleq+%5CDelta%5D+%5Cgeq+%5Cprod_%7Bj%3D1%7D%5En%5Cleft%281-2%5Cexp%28-%5CDelta%5E2%2F2n%29%5Cright%29%2C&bg=eeeeee&fg=000000&s=0&c=20201002)
where the last inequality follows from the fact that 
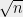
![\displaystyle Pr[g \in \mathcal{K}] \geq (3/4)^n.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr%5Bg+%5Cin+%5Cmathcal%7BK%7D%5D+%5Cgeq+%283%2F4%29%5En.&bg=eeeeee&fg=000000&s=0&c=20201002)
Now, let 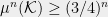
![{\mathcal{K}' = \mathcal{K} \cap [-1,1]^n}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BK%7D%27+%3D+%5Cmathcal%7BK%7D+%5Ccap+%5B-1%2C1%5D%5En%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
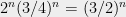





Now, note that the only lattice points in 
Discussion The above argument can actually be simplified by replacing the use of Kanter’s lemma with an appropriate version of Miknowski’s theorem for Gaussian volume as done here. But I like any excuse to discuss Kanter’s lemma.
More importantly, the proof seems to be more amenable to generalization. The core of the proof really is to use Sidak’s lemma to lower bound the Gaussian volume of the convex set
Question Is it true that for a universal constant
with
,
![\displaystyle Pr_{g \sim \mathcal{N}^n}\left[\|g_1 A_1 + g_2 A_2 + \cdots + g_n A_n \| \leq C \sqrt{n}\right] \geq (3/4)^n\,?](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr_%7Bg+%5Csim+%5Cmathcal%7BN%7D%5En%7D%5Cleft%5B%5C%7Cg_1+A_1+%2B+g_2+A_2+%2B+%5Ccdots+%2B+g_n+A_n+%5C%7C+%5Cleq+C+%5Csqrt%7Bn%7D%5Cright%5D+%5Cgeq+%283%2F4%29%5En%5C%2C%3F&bg=eeeeee&fg=000000&s=0&c=20201002)
Acknowledgments Thanks to Shachar Lovett, Oded Regev and Nikhil Srivastava for helpful suggestions, comments, and corrections during the preparation of this post.

Very nice post!
I may be missing something, but I think Giannopoulos’s proof also gives the implication from Gaussian volume lower bounds to a partial coloring.
Let be the set of “small discrepancy fractional colorings” (the same set you define), and assume
be the set of “small discrepancy fractional colorings” (the same set you define), and assume ![\Pr_g[g \in K] > 2^{-c_1n}](https://s0.wp.com/latex.php?latex=%5CPr_g%5Bg+%5Cin+K%5D+%3E+2%5E%7B-c_1n%7D&bg=eeeeee&fg=666666&s=0&c=20201002) . Then let
. Then let  be the number of sign sequences
be the number of sign sequences  such that
such that 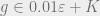 . From looking at the pdf of the standard gaussian,
. From looking at the pdf of the standard gaussian, ![\Pr[g \in 0.01\varepsilon + K] >= 2^{-c_2n}](https://s0.wp.com/latex.php?latex=%5CPr%5Bg+%5Cin+0.01%5Cvarepsilon+%2B+K%5D+%3E%3D+2%5E%7B-c_2n%7D&bg=eeeeee&fg=666666&s=0&c=20201002) for some
for some 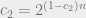 . So there must exist a point $\latex x$ which is in at least
. So there must exist a point $\latex x$ which is in at least  sets
sets  . For any two
. For any two  ,
,  , and since
, and since 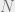 is so large, there must exist two
is so large, there must exist two  such that
such that  and
and  has large support. I chose 0.01 very conservatively, much better constants should do the job.
has large support. I chose 0.01 very conservatively, much better constants should do the job.
But Kanter’s lemma is cool in any case!
Indeed, Giannopoulos’s proof is simpler – one can view the argument you described (a typo: c_2 should be a constant) as a kind of Gaussian version of Minkowski’s theorem which by itself is a nice thing to know.
Sorry for the typo. I wish there was a way to preview comments by the way.
I could’ve been more explicit:![\Pr[g \in x + K] \geq e^{0.5\|x\|_2^2}](https://s0.wp.com/latex.php?latex=%5CPr%5Bg+%5Cin+x+%2B+K%5D+%5Cgeq+e%5E%7B0.5%5C%7Cx%5C%7C_2%5E2%7D&bg=eeeeee&fg=666666&s=0&c=20201002) for any centrally symmetric $K$ and any
for any centrally symmetric $K$ and any  , so
, so  . I guess I was really conservative with constants.
. I guess I was really conservative with constants.