This blog post is an introduction to the “Sum of Squares” (SOS) algorithm from my biased perspective. This post is rather long – I apologize. You might prefer to view/print it in pdf format. If you’d rather “see the movie”, I’ll be giving a TCS+ seminar about this topic on Wednesday, February 26th 1pm EST. If you prefer the live version, I’ll be giving a summer course in Stockholm from June 30 till July 4th. I’ve been told that there are worse places to be in than Stockholm in June, and there are definitely worse things to do than taking a course on analysis of Boolean functions from Ryan O’Donnell, which will also be part of the same summer school.
This post starts with an 1888 existential proof by Hilbert, given a constructive version by Motzkin in 1965. We will then go through proof complexity and semidefinite programming to describe the SOS algorithm and how it can be analyzed. Most of this is based on my recent paper with Kelner and Steuer and a (yet unpublished) followup work of ours, but we’ll also discuss notions that can be found in our previous work with Brandao, Harrow and Zhou. While our original motivation to study this algorithm came from the Unique Games Conjecture, our methods turn out to be useful to problems from other domains as well. In particular, we will see an application for the Sparse Coding problem (also known as dictionary learning) that arises in machine learning, computer vision and image processing, and computational neuroscience. In fact, we will close a full circle as we will see how polynomials related to Motzkin’s end up playing a role in our analysis of this algorithm.
I am still a novice myself in this area, and so this post is likely to contain inaccuracies, misattributions, and just plain misunderstandings. Comments are welcome! For deeper coverage of this topic, see Pablo Parrilo’s lecture notes, and Monique Laurent’s monograph. A great accessible introduction from a somewhat different perspective is given in Amir Ali Ahmadi’s blog posts (part I and part II). In addition to the optimization applications discussed here, Amir mentions that “in dynamics and control, SOS optimization has enabled a paradigm shift from classical linear control to … nonlinear controllers that are provably safer, more agile, and more robust” and that SOS has been used in “areas as diverse as quantum information theory, robotics, geometric theorem proving, formal verification, derivative pricing, stochastic optimization, and game theory”.
1. Sum of squares and the Positivstellensatz
One of the tedious exercises in high school mathematics involves finding the minimal value of a polynomial such as
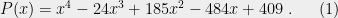
To solve this, we were taught to go over all critical points (where the derivative vanishes) and check their values, so eventually we get a picture like this
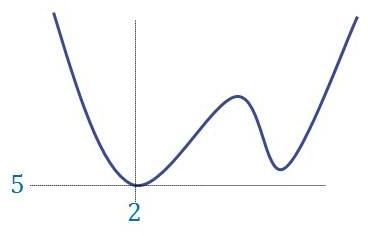
and can deduce that the minimum is achieved at the point 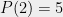
As theoretical Computer Scientists, we can make this feeling of tedium precise— this method involves exhaustive search over all local optima and hence can take 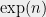


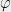

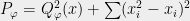
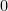
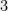
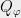

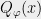

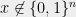
However, some times there is a nicer, more global way to argue about the extremal points of polynomials. For example, one can see that the minimum of the polynomial 
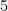

using the simple (but deep!) fact that a square of a number is never negative.
Bruce Reznick paraphrased Jane Austen to say
It is a truth universally acknowledged, that a mathematical object whose orderings are non-negative must be in want of a representation as a sum of squares.
Despite this saying, the 3SAT example above implies that (assuming NP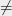
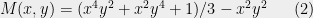
is always non-negative since the last term is the geometric mean of 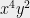

However, we cam still prove Motzkin’s polynomial is non-negative via a simple and short “SOS proof” since it is the sum of squares of four rational functions:
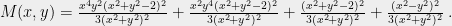
Already Hilbert was aware of this notion of SOS proofs, and asked as his 17th problem whether we can always certify the non-negativity of any polynomial by such a proof. Through works of Artin (1927), Krivine (1964), and Stengle (1974), we know the answer is a resounding yes!. These results, which serve as the foundation of real algebraic geometry, are known as the Positivstellensatz and hold for even more general polynomial equalities and inequalities. In particular, given some polynomials 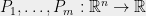

is unsatisfiable if and only if this can be certified by finding 


(The Positivstellensatz applies to polynomials inequalities as well, but in the context of optimization, one can always transform an inequality 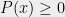
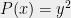
2. Proof systems and algorithms
As Theoretical Computer Scientists, we typically try to make qualitative questions into quantitative ones, and indeed in 1999 Gregoriev and Vorobjov defined the Positivstellensatz proof complexity of a set of equations as the minimal degree needed for the polynomials 
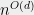
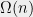
Bounds on the degree turn out to be very important for optimization as well. Several researchers, including N. Shor, Y. Nesterov, P. Parrilo, and J. Lasserre, realized independently that it is possible to search for a degree 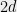
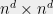
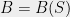
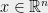
![{B \cdot x^{\otimes 2d} = \sum_{i_1,\ldots,i_{2d}\in[n]} B_{i_1,\ldots,i_{2d}} x_{i_1}\cdots x_{i_{2d}} = S(x)}](https://s0.wp.com/latex.php?latex=%7BB+%5Ccdot+x%5E%7B%5Cotimes+2d%7D+%3D+%5Csum_%7Bi_1%2C%5Cldots%2Ci_%7B2d%7D%5Cin%5Bn%5D%7D+B_%7Bi_1%2C%5Cldots%2Ci_%7B2d%7D%7D+x_%7Bi_1%7D%5Ccdots+x_%7Bi_%7B2d%7D%7D+%3D+S%28x%29%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
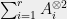
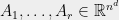
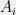
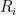
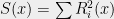
So, we can efficiently certify the unsatisfiability of a set of polynomial equations if it has a low degree SOS proof. But under what conditions will it have such a proof? and what about finding solutions for satisfiable polynomial equations?
Progress on these questions has been quite slow. For computational problems of interest, degree upper and lower bounds have both been very hard to come by. We essentially knew only one degree lower bound— Gregoriev’s result mentioned above (later rediscovered by Schoenebeck and expanded upon by Tulsiani). As for upper bounds, until very recently we essentially had none, in the sense of having no significant algorithmic results using the SOS algorithm that did not already follow from weaker algorithms. However, some recent results, including the quasipolynomial time quantum separability algorithm of Brandao, Christiandl and Yard, and our results on solving “hard” unique games instances, gave some signs that the SOS framework does have the potential to solve problems beyond the reach of other techniques. In a very recent work with Kelner and Steurer, we show a general way to exploit the power of SOS, which I will now describe.
3. Pseudoexpectations and Combining algorithms
Our approach for using SOS to solve computational problems is based on the following wise proverb
It is easier to solve a problem if you already have a solution.
Specifically, fix the set of polynomial equations (3). A combining algorithm is an algorithm 
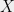
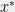


![{i_1,\ldots,i_d \in [n]}](https://s0.wp.com/latex.php?latex=%7Bi_1%2C%5Cldots%2Ci_d+%5Cin+%5Bn%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
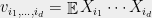

How do we construct those “fake moments”? and when will we be lucky? Those “fake moments” are more formally known as pseudoexpectations, and can be found using a semidefinite program which is the dual to the SOS program. In particular, they will obey some of the consistency properties of actual moments, most importantly that for every degree 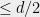

4. Machine learning application: the sparse coding problem
To make things more concrete, we now sketch an example taken from an upcoming paper with Kelner and Steurer. One can see other examples in our original paper. One of the challenging tasks for machine learning is to find good representations for data. For example, representing a picture as a bitmap of pixel works great for projecting it on a screen, but not is not as well suited for trying to decide if it’s a picture of a cat or a dog. Finding the “right” representation for, say, images, is often a first task not just in learning applications, but also for other tasks such as edge detection, image denoising, image completion and more. Sparsity is one way to capture “rightness” of representation. For example, it is often the case that the data is sparse when represented in the “right” linear basis (such as the Fourier or wavelet bases). Olshausen and Field (1997) argued that this may be the way that images are represented by in visual cortex, and they used a heuristic alternating-minimization based algorithm to recover the following basis (also known as a dictionary) for natural images.

But of course as theorists we are not satisfied with a heuristic that works fast and achieves good results. We want a slower algorithm with worse performance that we can prove something about. This is where Sum of Squares comes to the rescue. (At least on some of the counts: it is definitely slower, and we can prove something about it; however “unfortunately” beyond just amenability to analysis there is an (unverified) chance that it actually outperforms the heuristics on some instances, since at least in principle it can avoid getting stuck in local minima.) Recently there have been several works giving rigorous guarantees for sparse coding (e.g., [SWW12 , AGM13, AAJNT13]) but all of them require the representations to be “super-sparse”- have less than 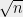
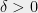
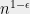
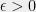
We now sketch the ideas behind the solution. For simplicity of notation, lets assume that the “right basis” is in fact an orthonormal basis 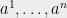
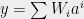

![{\Pr [ W_i = 0 ] = 1 - p}](https://s0.wp.com/latex.php?latex=%7B%5CPr+%5B+W_i+%3D+0+%5D+%3D+1+-+p%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![{\Pr[ W_i = +1 ] = \Pr[ W_i = -1] = p/2}](https://s0.wp.com/latex.php?latex=%7B%5CPr%5B+W_i+%3D+%2B1+%5D+%3D+%5CPr%5B+W_i+%3D+-1%5D+%3D+p%2F2%7D&bg=eeeeee&fg=000000&s=0&c=20201002)

We focus on the task of approximately recovering a single basis vector: once you have such a subroutine, recovering all vectors is not that hard. We do so in three steps:
- Using the examples observed, we construct a system
of polynomial equations. We argue that any solution
More concretely, we will find some polynomial
whose projection on the sphere looks somewhat like this
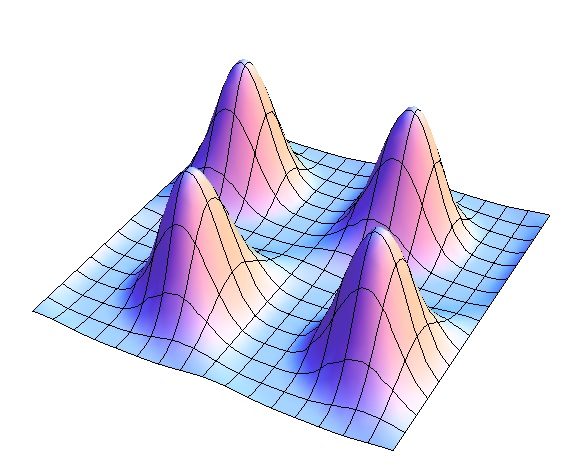
and whose maximum points correspond to the unknown vectors of our dictionary.
- On its own, phrasing the question as a polynomial system is not necessarily helpful, since
- We then verify that all our arguments in Steps 1 and 2 can be encapsulated in the SOS proof system with a low degree, and hence
We now describe how to implement those three steps.
Step 1: The system of equations. Given examples 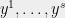
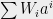


(As mentioned before, we can always translate the inequality into an equality by adding an auxiliary variable.)
As 

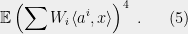
It suffices to take 

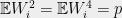

which equals

since the 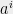
Note that 
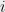
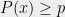
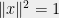
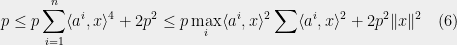
which for 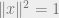
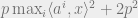

which means that
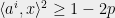
for some
Step 2: Combining algorithm. I will describe a particularly simple combining algorithm that will involve moments up to logarithmic order, and hence result in a quasipolynomial time algorithm. Under some conditions (namely 
The combining algorithm gets access to a distribution 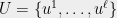

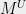

where 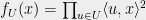
We claim that with probability 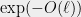
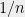
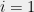

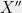
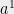
Note that for any unit vector 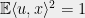

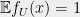
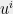
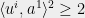
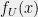
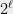
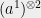
Step 3: Lifting to pseudoexpectations. Step~3 is in some sense the heart of the proof, moving from a combining algorithm, that requires an actual distribution (which we don’t have), to a rounding algorithm, that only needs a pseudo-distribution (which we can find using semidefinite programming). However, it is also the most tedious, since it involves going over the steps of the proof one by one, verifying that each one only used SOS arguments. However, occasionally “lifting” the proofs for pseudoexpectations requires more care. Rather than giving the full proof here, we show just one example of how we deal with one of those more subtle cases.
Recall that while deriving (6), we used the following simple inequality:
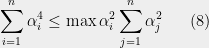
(substituting 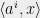
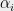

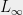
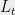

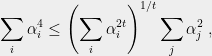
for some large 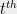
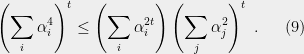
(9) becomes non-trivial to prove in SOS for 
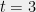

The RHS has the form

Fixing some particular 

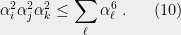
(10) follows from

but this is just our old friend the AMGM inequality 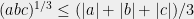
here.) Thus (11) holds if the
Conclusion
While until recently we had very little tools to take advantage of the SOS algorithm (at least in the sense of having rigorous analysis), we now have some indications that, when applied to the right problems it can be a powerful tool, that may may be able to goals that resisted previous attempts. We have seen some examples of this phenomenon, but I hope (and believe) the best is yet to come, and am looking forward to seeing how this research area develops in the near future.
Acknowledgements. Many thanks to David Steurer for great suggestions, corrections, and insights that greatly improved this blog post, as well as for patiently explaining to me for the nth time the difference between the Positivstellensatz and Nullstellensatz. Thanks to Amir Ali Ahmadi, Jon Kelner, and Pablo Parrilo for showing me the SOS proof for (11) in the ICERM workshop on semidefinite programming and graph partitioning. Thanks to Amir for also pointing out an error in my previous reduction from 3SAT.

the Olshausen/Field 1997 ref is really signficant & quite compelling in the way that it hints the sparse encoding model so well, maybe nearly “perfectly” describes the visual area yet might be used also outside of the visual area in other brain areas. this paper shows that sparse encoding might be one of the most plausible known mathematical mechanisms for biological algorithms of cognition. also sparse coding has turned into an extremely significant field since the paper was written.
recently there is intense advancement in the field of deep learning, and more interest in Spiking Neural Networks (along with neuromorphic computing) and it would be great if those more biologically realistic models could be tied with sparse encoding algorithms somehow, am not aware of anyone yet making the connection(s)….
another aspect of biology that seems highly relevant to these models is what is known as “lateral inhibition” which is typical of biological neurons in the brain it seems, but havent seen that tied in with these algorithmic models either. it seems to be a way for neurons to avoid taking on similar feature detection functions ala edelmans “neural darwinism”….
anyway some of the pieces of the puzzle coming together!
I am not an expert on deep learning, and definitely don’t know much about the biology part of it, but indeed there does seem to be some relation to sparse coding, at least in the first layer of deep networks, as visualizations of it do look similar to the Olshausen/Field picture above.
hi BB few are expert on deep learning at this point it is a rather young field (by reasonable measures less than a decade old); it depends on large supercomputers/clusters which are only recently becoming available. the google experiments were able to create higher-level feature detectors eg the famous “cat”.. but it seems quite possible the lower level feature detectors are nearly the same as the sparse lines found above. this is an amazing concept that few seem to realize– is the basic cognition system in biology building complex higher level feature detectors out of lower level ones out of an apparent recursive/hiearchical-like organization of neurons & learning algorithms? that seems very likely to me to be the case. by the way hubel/wiesel won the 1981 nobel prize for discovering mammalian line/feature detectors in the visual cortex.
My (limited) understanding is that this is the intuition in this field – that in the “artificial” deep networks used for learning state of the art concepts, and (here is where I am much more shaky) perhaps the biological networks that inspired them, the bottom layer detecting lower level features is something like the sparse coding representation, and then higher layers use this representation to detect higher level features (like “having an eye”, and at the highest level features such as “being a Chihuahua”).
yes so far re “hierarchical feature detectors” it seems to be merely an intuition that is not backed up by much careful analysis & havent seen this idea written up anywhere in scientific papers/books etc except possibly in the (imho) rather sketchy “hierarchical temporal memory” ideas floating around by Hawkins. (maybe should write this up sometime in my own blog as best possible.)
for example the recent google image recognition project (Ng et al) found the high level cat detector but not sure if they identified the low-level line detectors. it seems to be the data deluge problem (big data all over again), there is probably much more to analyze in their results than they have published so far. it would be so great if they did an open-science release of their actually neural weights and allowed people to distributedly datamine it ala say the analysis of NASA images or “folding@home”…. there is probably very significant stuff lurking in it that they havent found on 1st pass….
did just write up a big list of links on deep learning for anyone interested. & deep learning & big data go together like chocolate & peanut butter! both sure to be in the limelight over the next few years & presumably in some more blockbuster/gamechanging results also! early days/scratching the surface/tip of the iceberg right now!
Great result, Boaz et al. It combines two of my recent interests 🙂
I wanted to quickly clarify something for the readers who may not know the prior art. A major issue in such algorithms is whether they continue to work when the input is noisy.
The earlier paper of Spielman, Wang and Wright on learning dictionaries couldn’t handle noise. Allowing noisy inputs was one of the main motivations behind our subsequent works cited above.
It would be very interesting to do noise-tolerant dictionary learning via SOS hierarchies.
Another issue in all the algorithms is the need to make fairly strong stochastic assumptions on the hidden vector x, and it would be nice to relax them further.
Deep learning is indeed a good motivation for dictionary learning, and was the reason we became interested. Seems to me that any provable approach to learning deep nets has to first handle dictionary learning, which is a very simple subcase (intuitively, not formally).
hi SA wrote a reply to your other blog from not long ago on peer review. did someone delete that? on accident/purpose? or maybe it didnt save right? 😡 … wanted to post a few related links… also thinking of blogging on this myself sometime….
vznvzn: Sorry I don’t know. I was only a guest blogger; the blog is run out of MSR.
Hi Sanjeev, . Indeed, we only need the approximation to be in the spectral norm of the coefficient matrix (as opposed to the Frobnieus norm), which, roughly speaking, means it only needs to agree with P on the approximate maxima and not on the rest of the space.
. Indeed, we only need the approximation to be in the spectral norm of the coefficient matrix (as opposed to the Frobnieus norm), which, roughly speaking, means it only needs to agree with P on the approximate maxima and not on the rest of the space.
Thanks for your comment. Indeed our approach is somewhat inherently noise-tolerant, since we are fine with first only having an approximation to the polynomial P, and (more importantly) with the polynomial P itself being only an approximation to the polynomial
p.s. vznvzn – i wasn’t in charge of moderating comments on that post. you could try to post your comment again if comments aren’t already closed on that post, though comments with links in them often get automatically flagged as spam.
hi BB ran across this great video by Andrew Ng: Deep Learning, Self-Taught Learning and Unsupervised citing olshausen/field as precursor for the deep learning neural networks algorithms. at about 30m he talks about Honglak Lee’s great paper using hierarchical feature detection. had not seen this before. its basically just a hierarchy of sparse encoding networks & functions well. wonder how close google’s algorithm is to that, have to do more research….