[Yet another “philosophizing” post, but one with some actual numbers. See also this follow up. –Boaz]
Recently there have been many debates on “artificial general intelligence” (AGI) and whether or not we are close to achieving it by scaling up our current AI systems. In this post, I’d like to make this debate a bit more quantitative by trying to understand what “scaling” would entail. The calculations are very rough – think of a post-it that is stuck on the back of an envelope. But I hope that this can be at least a starting point for making these questions more concrete.
The first problem is that there is no agreement on what “artificial general intelligence” means. People use this term to mean anything between the following possibilities:
- Existence of a system that can meet benchmarks such as getting a perfect score on the SAT and IQ tests and passing a “Turing test.” This is more or less the definition used by Metaculus (though they recently updated it to a stricter version).
- Existence of a system that can replace many humans in terms of economic productivity. For concreteness, say that it can function as an above-average worker in many industries. (To sidestep the issue of robotics, we can restrict our attention to remote-only jobs.)
- Large-scale deployment of AI, replacing or radically changing the nature of work of a large fraction of people.
- More extreme scenarios such as consciousness, malice, and super-intelligence. For example, a system that is conscious/sentient enough to be awarded human rights and its own attorney, or malicious enough to order DNA off the Internet, build a nanofactory to construct a diamondoid bacteria riding on miniature rockets, so they enter the bloodstream of all humans and kills everyone instantly, while not being detected.
I consider the first scenario– passing IQ tests or even a Turing test– more of a “parlor trick” than actual intelligence. The history of artificial intelligence is one of underestimating future achievements on specific benchmarks, but also one of overestimating the broader implications of those benchmarks. Early AI researchers were not only wrong about how long it will take for a computer program to become the world chess champion, but they also wrongly assumed that such a program would have to be generally intelligent as well. In a 1970 interview, Minsky was quoted as saying that by the end of the 1970s, “we will have a machine with the general intelligence of an average human being … able to read Shakespeare, grease a car, play office politics, tell a joke, have a fight. At that point, the machine will begin to educate itself with fantastic speed. In a few months, it will be at genius level, and a few months after, its powers will be incalculable… In the interests of efficiency, cost-cutting, and speed of reaction, the Department of Defense may well be forced more and more to surrender human direction of military policies to machines.”
Brooks explains that early AI researchers thought intelligence was “best characterized as the things that highly educated male scientists found challenging.” Since playing championship-level chess was hard for them, they couldn’t imagine a machine doing it without doing all other tasks that they considered more trivial. Getting a high SAT or IQ exam score is no more meaningful (for machines or humans) than doing well in chess.
The fourth scenario is, at the moment, too speculative for quantitative discussion and hence less appropriate for this post (though see the addendum below). We will focus on the second and third scenarios, which are necessary stepping stones for the more extreme fourth option. For the sake of concreteness, I will make the optimistic assumption that “scale is all you need” to achieve either of these scenarios. I will then try to see our best estimates on how much scale and at what cost.
The point of this post is not to argue that we will never achieve scenarios 2 or 3. Instead, it is to try to get quantitative estimates on challenges we would need to overcome to do so. I believe it is possible, but it would be more than just getting better hardware.
This is a long post. If I had to TL;DR it, I would say that we have significant uncertainty on how much scale we need for AGI. Scaling to 10-100 Trillion parameters may well get us to Scenario 2 or something near. Still, training and (potentially) inference costs may be prohibitive to achieving the reliability and generality needed for actual deployment. Some challenges we face include:
(1) Maintaining long-term context without model size exploding.
(2) Making training more efficient, particularly finding ways to train N-sized models at a near-linear cost instead of quadratic in N.
(3) Avoid running out of data, perhaps by using video/images and programmatically generated interactive simulations.
(4) Handling multi-step interactions without the interaction going “off the rails” and without needing to scale policy/value gradients to an unfeasible number of interactions (perhaps by using smaller RL-trained “verifier models” to choose between options produced by a large statically-trained model).
This post is focused on quantitative issues rather than questions such as “consciousness” or the risks of AI. Those deserve a post of their own. See the addendum at the end for some more philosophical/speculative discussion.
Initial notes
Since artificial intelligence exists in the virtual space, people often assume that we can clone it an arbitrary number of times. But modern AI systems have a highly non-trivial physical footprint. Current models require dozens of GPUs to store their parameters, and future ones would be even larger. Creating many copies of such systems is going to be challenging.
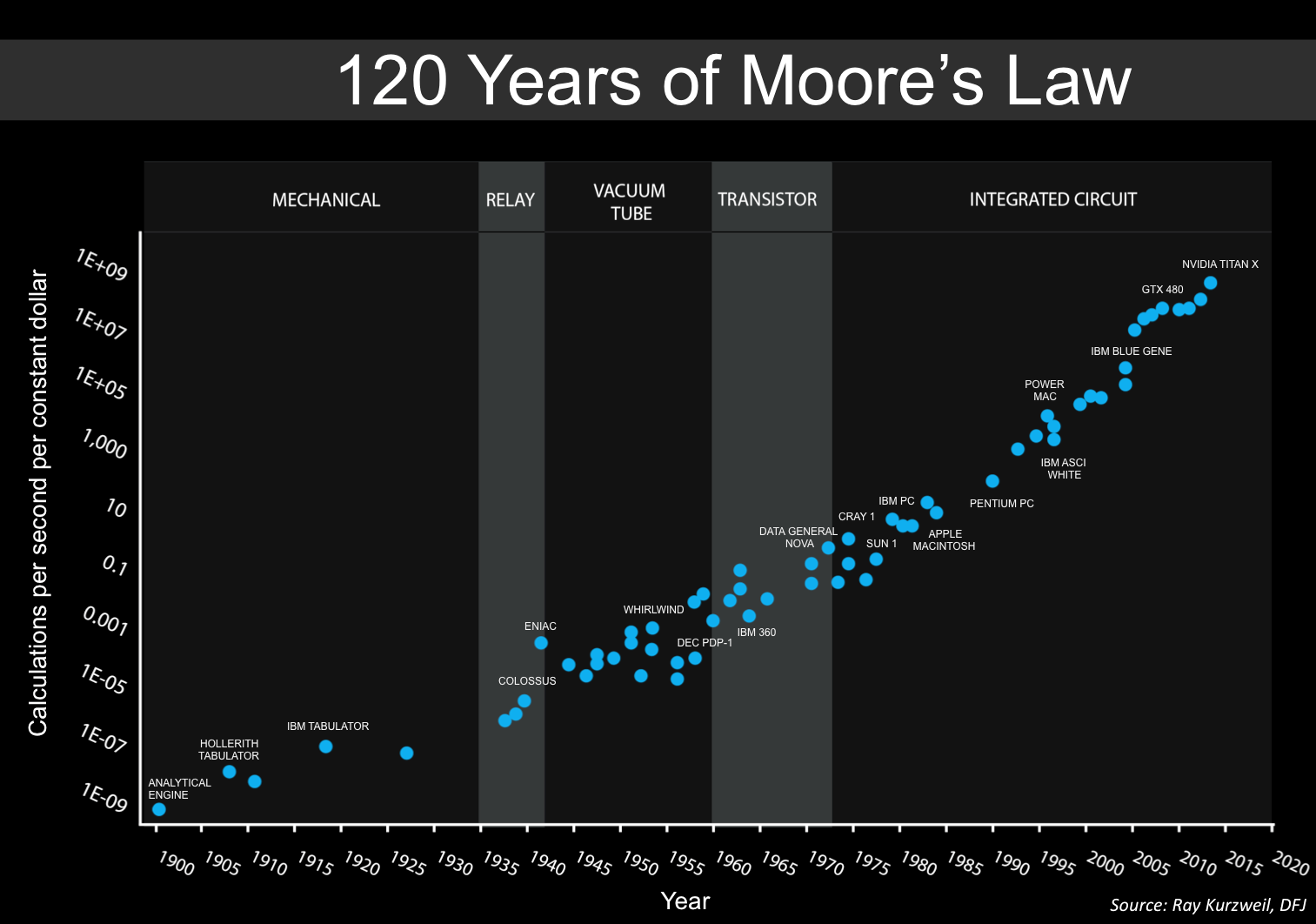
Another common assumption is that by Moore’s law, if we manage to build a system at the level of (say) a sixth-grader, then in a year, we would have a virtual Einstein. However, often performance on a metric scale with the logarithm of the number of parameters (e.g., see Big-bench and Parti figures). So, perhaps a better assumption is that if we manage to build a virtual sixth-grader, then the following year, we would have a virtual seventh-grader.

If scale is all you need, how much scale will we need?
Let’s assume that we could reach the second scenario (proof of concept general AI system) by simply scaling up our current auto-regressive language models by a factor of X. What would be X?
Adaptivity. One crucial difference between the tasks we currently test language models on and general intelligence is adaptivity. A model that answers a question correctly with 95% probability is excellent. But with a 5% chance of error, such a model may go “off the rails” in a back-and-forth conversation with more than 20 steps. Adaptivity is one reason why robotics performance (even in simulated virtual worlds) still lags far behind humans. It is not so much that the physical environment is higher dimensional than the inputs to language models, but the fact that robots’ actions impact it (and unlike in the case of Chess, Go, or Atari, we don’t have an unlimited number of restarts and simulations). Navigating the social and technical environment of (even a virtual) workplace is no less challenging. Squeezing out that final performance (e.g., from 95% to 99%) is usually when power laws kick in, reducing error by a factor of k, requiring a multiplicative overhead of k to some power a>1.
Context length. Another way to think of scaling is the length of the context window models keep. To be useful in replacing a human worker, we don’t want to continuously simulate their first day at work. We want an employee that remembers what they did yesterday, last week, and last year. GPT-3 maintains a window of 2048 tokens, corresponding to roughly 1500 words or three pages of text. However, if you had to write a letter to your future self detailing everything they should remember from your interactions so far, it would likely be much longer. (Claude Fredericks, who may have been the most prolific diarist in history, wrote a diary of approximately 65,000 pages.)
Unfortunately, in standard transformer models, computation and memory cost quadratically with the context (though due to weight-sharing between different tokens, the number of learned parameters doesn’t have to increase), which means that increasing the context by (say) a factor of 100 will require increasing model size by a factor of 10,000. However, several alternative transformer architectures aim to achieve linear or near-linear model size scaling with the context.
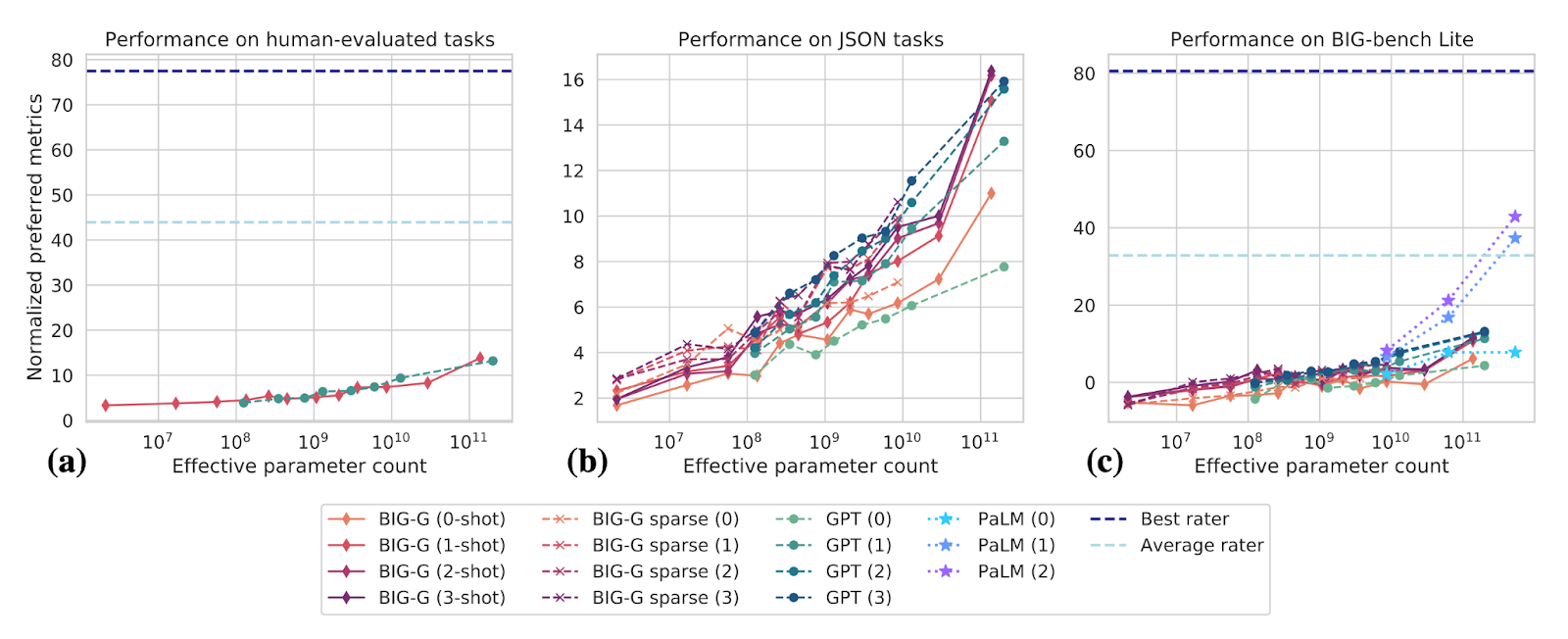
Empirical scaling of performance. The recent BIG-bench paper is perhaps the most comprehensive study of how large language models’ performance improves with scale. They assembled an extensive collection of tasks, each with a score normalized to (mostly) stay in the interval 0-100, with a score of zero corresponding to trivial (e.g., random) performance and a score of 100 corresponding to near-perfect performance (e.g., expert human). In many of these tasks, current models score lower than 20. We still don’t have enough data to know how truly large models behave. On the one hand, naive extrapolation suggests that we need many orders of magnitude for high performance (e.g., a score of 80 points or above). On the other hand, larger models such as Google PaLM show evidence of “breakthrough capabilities”- performance growing super-linearly in the logarithm of size. It seems that to solve this benchmark fully, we would need at least a factor of 10 increase over the ½ Trillion parameter PaLM model.
Comparing with the brain. Another point of comparison could be the human brain. However, human brains and artificial neural networks have very different architectures, and we don’t know how many parameters correspond to a single neuron or synapse. Scott Alexander quotes this estimate of 100 trillion parameters on the brain’s size, which would correspond to a factor of 100-1,000 larger than current models. However, the estimate is rather hand-wavy, and even if it wasn’t, there is no reason to expect that artificial neural networks would have the same “ability per parameter” ratio as human brains. In particular, artificial neural networks appear to compensate for relatively weaker reasoning skills by ingesting a massive amount of data, and with data, the model size grows as well.
Bottom line. Overall, it seems that X will need to be at least 10-100, though this is an extremely rough estimate. Also, while an X Trillion model might be the “core” of a system replacing a human worker, it will not be the whole of it, and we are likely to need new ideas beyond scale for these other components. In particular, a model designed for back-and-forth interaction is unlikely to simply use an auto-regressive language model as a black box, not even with chain-of-thought reasoning.
How much will it cost?
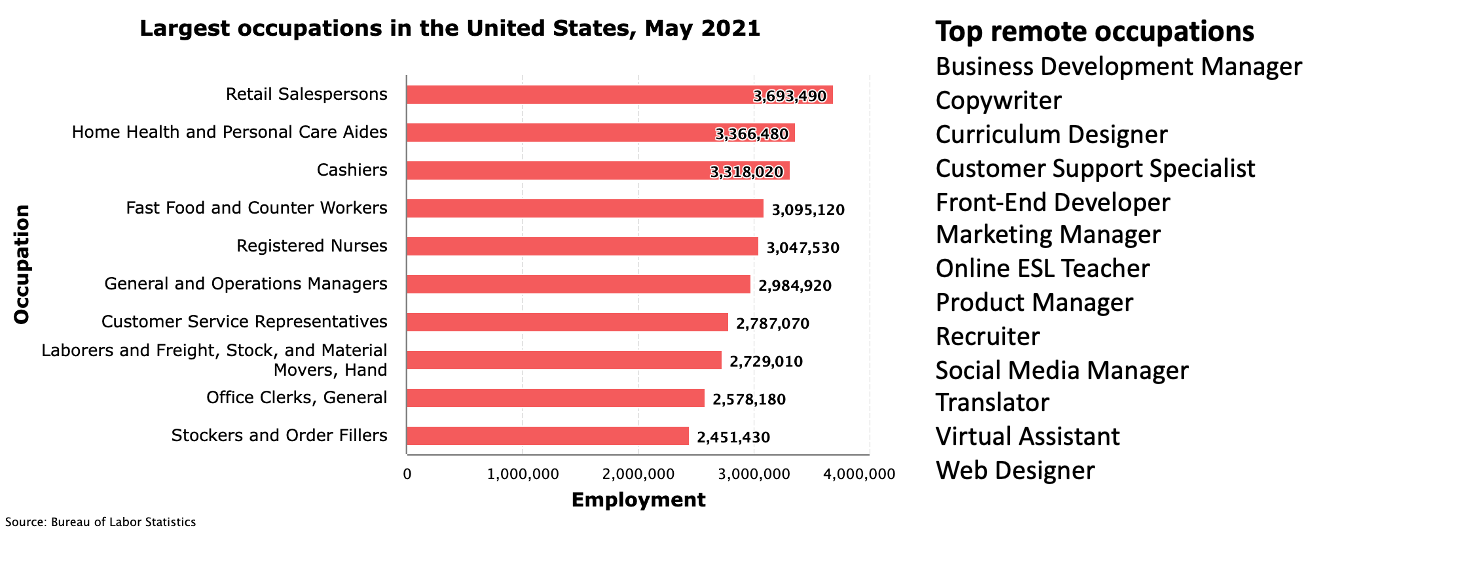
Suppose that scaling our current models by a factor of X can achieve “AGI” in the sense of yielding a system that can be as productive as humans in a wide variety of professions (say all the top remote jobs in the list from FlexJobs). How much do we expect it to cost to (1) build a single system of this magnitude and (2) widely deploy it?
The gap between a “proof of concept” to actual deployment can be pretty significant. For example, in 2007, CMU won the urban DARPA grand challenge, while in 2012, a Google autonomous car passed a driving test. Yet a decade later, we still don’t have a significant deployment of self-driving cars. Also, as described in the book (and film) Hidden Figures, despite Moore’s law starting in the 30s, NASA still employed human computers until the 1960s.
For this post, I will make the optimistic (and unrealistic) assumption that the difference between proof-of-concept and deployments corresponds to the difference between the cost of training a system vs. the cost of doing inference on it. If a system costs more than $100B to train, then it may never get built (for comparison, the Large Hadron Collider cost less than $5B to build). Similarly, a system costing $1000/hour to use is unlikely to replace human workers at scale.
The costs below are calculated with today’s dollars and today’s hardware. Of course, improvements in hardware will translate to cheaper training and inference. However, we have neglected costs that can scale super-linearly with model size, including communication between nodes, managing massive clusters and more. I consider only amortized costs since those are what matter when training and serving models at scale.
Cost of training
There is no point in training a large model if you don’t train it for enough time. The performance advantages of larger models are realized by allowing them to train on more data without “saturating”. In the words of the Chinchilla paper “for every doubling of model size the number of training tokens should also be doubled.” (See also the deep bootstrap paper). Hence the number of inferences applied using training also scales with the model size. This means that if a model grows by a factor of X then both the cost of a single inference as well as the total number of inferences grow by about X, meaning that the cost of training grows by about X2. In particular, we can expect training a model that is 100 times as large to cost 10,000 times more!
There are differing estimates on how much ~100B parameter GPT3 model cost to train, but they range in the $5M-$20M, let’s say $5M in pure training costs for simplicity. (This would correspond to a cost of 5M$/500B = 10-5 dollars per inference, which matches roughly with estimates below.) An X Trillion model (which, like Chinchilla, but unlike PaLM, would be fully trained to max out its advantages) might cost a factor of 100X2 more. For X=10, this would be a cost of $50B. For X=100, this would be 5 Trillion dollars!
Clearly, finding a way to train N-sized models on N tokens using less than O(N2) steps (e.g., O(N log N) ) can be crucial for scaling larger models. Training larger language models also runs into the problem that we have nearly “maxed out” the available textual data. Modern models are already trained on hundreds of billions of words, but there is a limit to how much novel text can be produced by a planet of 8 billion people. (Though multimodal models that are also trained on video would have access to much more data.)
Cost per inference
Suppose that we have managed to train a large model of X Trillion parameters. How much do we expect inference to cost in dollars? In transformer architectures, the number of floating-point operations required to make a single model evaluation (i.e., inference) is roughly the same as the number of parameters.
Hence an X Trillion parameter model requires about X TerraFLOPs (TFLOPs). Nvidia’s A-100 GPUs claims peak performance of about 300 TFLOP/s. (The effects of using 16-bit precision and not achieving 100% utilization roughly cancel out.) Renting such a machine costs about $1/hour, so we can get about 300*3600 ~ 1M TFLOPs per dollar. (This is up to order of magnitude and caring just about total FLOPs rather than wall-clock time; for careful calculations of inference time, see Carol Chen’s and Jacob Steinhardt’s blogs.)
So far, this sounds great – we could make 106/X inferences per dollar for an X trillion parameter model. However, in the real world costs are much higher. The same Nvidia blog shows that A-100 can handle 6000 inferences/sec of the 340M parameter Bert Large. Since an X Trillion model is 3000X larger, that would correspond to 2/X inferences per second or 7200/X inferences per hour/dollar. The calculations above predict that the 0.2 Trillion parameter GPT-3 would be able to perform 7200*5~35K inferences per dollar. However, OpenAI charges 6 cents per 1K tokens (including input tokens!), which depending on the length of the input, can be only 10 inferences per dollar. Bhavsar estimates GPT-3 can handle about 18K inferences per GPU hour. Overall it seems that 104/X inferences per dollar is an optimistic estimate.
However, the question is how many inferences we need to make per hour to simulate a human. The average person apparently speaks about 150 words (say 200 tokens) per minute. This would suggest we need about 200*60 ~ 10K inferences per hour to simulate a person. For an X Trillion sized model, that would cost $X per hour, which is not too bad if X is between 10 to 100.
The above price point sounds pretty good but will likely be an underestimate. First, to actually simulate a human, we need not just to simulate what they say but also what they think. So, to perform “chain of thought” reasoning, we would need to run an inference per word that is thought rather than a word that is uttered. We don’t know the speed of thought, but it will increase the number of inferences needed. Generally, to simulate a chain of reasoning of depth K, the number of inferences scales with K, even if the end result is just a single token. Second, to reach high reliability, it is likely that we will need to make Y inferences and use some mechanism to choose the best one out of these Y options. For example, AlphaCode generates millions of possible solutions to programming challenges and filters them into 10 candidate ones. It is hard to estimate what Y would be in a workplace environment, but it seems that Y would be somewhere between 10 to 100.
Bottom line for inference cost. The estimates above suggest that an X Trillion parameter model would require about 105 to 106 inferences per hour to simulate a person, with a cost that ranges from $10X to $100X per hour. This is already tight for X=10 and would be too much for X=100. However, it is not clear how many words/thoughts we need to simulate per given profession, so these estimates are very rough.
The bottom line
While the estimates above should be taken with huge grains of salt, I believe that generally useful artificial intelligence can likely be achieved, but it will require more than sheer scale. While in principle a perfect next-word extender is also a perfect reinforcement learner, we may not be able to get close enough to perfection by scale alone. More than any particular conclusions, I hope that the debate can move from general philosophical arguments to quantitative questions that have numerical answers.
Addendum: The “C word” and existential risk.
I tried to keep this post within the realms of calculations and away from philosophy. But given recent discussions and hype on whether AI systems can achieve “consciousness” or “sentience” and whether they pose a unique existential risk, I feel that I must address this at least briefly. Readers allergic to philosophy and unjustified speculations can stop here.
Consciousness is a tricky concept: the Stanford Encyclopedia of Philosophy entry lists nine different specific theories of consciousness, and there are more theories still. It is also intertwined with ethics: if we consider a creature to be conscious or sentient, then the boundaries of how we can treat it become an issue of ethics. I don’t think it’s the job of computer scientists (or any other scientists) to come up with a moral philosophy, and similarly, I don’t think defining consciousness falls in our domain.
Historically, there seem to be two kinds of non-human entities which we considered conscious or sentient. One is animals, to which people have felt superior. The other is gods, to which people have felt inferior. Before we understood the causes of planetary movements, weather events, and other natural phenomena, we ascribed them to conscious actions by various gods. Since we couldn’t predict or explain these phenomena, our only attempt at controlling them was through prayer and sacrifice to the presumably conscious entity that controls them.
Some discussions of potential future AI are reminiscent of those past gods. According to some, AI would be not just conscious but capricious and could (according to some, would) ensure that “everybody on the face of the Earth suddenly falls over dead within the same second.” It is of course, possible to construct hypothetical scenarios in which an AI system managed to start a nuclear war or design a lethal virus. We’ve all read such books and seen such movies. It is also possible to construct scenarios where humans start a nuclear war or design a lethal virus. There are also many books and movies of the latter type. In fact, many AI “doomsday scenarios” don’t seem to require super-human levels of intelligence.
The truth is that the reason that our world hasn’t been destroyed so far is not that humans were not intelligent enough nor because we haven’t been malicious enough. First, throughout most of human history, we did not have technologies such as nuclear weapons and others with the potential to cause planet-scale destruction. Second, while imperfect, we have developed some institutions, including international bodies, the non-proliferation treaty, standards for biolabs, pandemic preparations, and more to keep some of these capabilities in check. Third, we were lucky. From climate change through pandemic preparation to nuclear disarmament, humanity should be doing much more to confront the risks and harms of our own making. But this is true independently of artificial intelligence. Just as with humans, my inclination with AI would not to try to make systems inherently moral or good (“aligned” in AI-speak) but rather use the “trust, but verify” approach. One moral of computational complexity theory is that computationally weak agents can verify the computation of more powerful processes.
Many of the calculations above show how “scaling up” is going to be non-trivial, and it is unlikely to see AI making restaurant reservations one day, and secretly ordering material over the net to build a world-destroying nano-technology lab the next one. Even if it’s possible for a large-scale model to “train itself” to improve performance, without needing additional outside data, that model would still incur the considerable computational costs for training that we computed above.
In my previous post, I explained why I am not a “longtermist”. The above is why I don’t view an “AGI run amok” as a short-term existential risk. That doesn’t mean AI doesn’t have safety issues. AI is a new technology, and with any new technology come new risks. We don’t need science fiction to see real risks in both unintentional consequences of AI deployment such as discrimination and bias, as well as intentional consequences of deploying AI for weapons, surveillance, and social manipulation. I don’t think that debating the notion of consciousness and inventing doomsday scenarios is helpful for combatting any one of those.
Acknowledgments: Thanks to Jascha Sohl-Dikstein for many useful comments on a draft of this blog post, and on how to interpret the results of the BIG-bench paper.

Love your post. Especially appreciate the estimation of the training cost for future X-sized models.
Two more points which I would like to add.
1. It seems that it is possible to exchange between a number of parameters of the pretrained model and compute.
Examples:
Chain of thought prompting, beam search, test time augmentation, AlphaCode type clustering, etc.
In AlphaCode paper they said that both model size and compute spent gave log scale improvements.
Obviously, they did not spend compute optimally and maybe it’s quite possible to improve it, but it points to the fact that we don’t need some exact scale for AGI (as defined by 2., 3.). There is a Pareto frontier in training/inference cost.
2. We can use the AlphaCode model as a benchmark of performance.
Given that 21B model on 7000 TPU was about average human skill in this contest, we can guess that we will need at least 1 OOM (possibly more) to get to the top performance level. While if we look at the relative performance of GPT-3 and the model fine-tuned on code there are at least 3 OOM differences between them.
So to have a fully general model GPT-3 style, that can be a competitive programmer we would need at least 4 OOM.
The above is true only under the assumption that we keep the way we use extra compute. Which is clearly not efficient, but good enough for a rough approximation.
Would be glad to hear any thoughts on this. Especially if I’m wrong somewhere.
I think that in restricted domains like coding, we could use smaller models, but for more general open-ended tasks we do need the large model. The Chinchilla paper argued that the scaling is that we need to train such models for number of tokens proportional to their size if we want to make most efficient use of our total compute budget.
I’m not sure that I agree.
The Chinchilla paper discussed only training budget, but they don’t discuss inference budget.
I can give two more examples of “inference compute matter”.
One would be a recent wave of image models. VQ-GAN and diffusion models have one thing in common compared to original GANs or VAEs. They do inference not in one, but in many successive steps. And there is probably scaling law of how good can you made fid score depending on number of diffusion steps.
The second example would be human brain itself. I will not argue that it works the same way. However, from the perspective of compute budget we don’t expect humans to be able to solve any task in existence within one “inference step”. The harder the task, the more time people need to think about it.
I think I’m that sence something like lstm is much closer to human brain (because like humans it can spend additional computation to refine its internal state) and will make a huge comeback in near future.
It seems very unfair to reduce the AI risk concerns to “we’ve all seen those movies”. There are a collection of technical claims that point to the problem. Roughly:
1. People will develop increasingly autonomous AIs, that are capable of acting in the world independently. “Trust but verify” assumes you have a system that just spits out information for you that you can check, but the economic incentives point away from staying at that level.
2. Such systems are going to be given their own ability to make judgement calls, including about some things that humans don’t understand.
3. Human values are really complicated, so that getting an AI to “care” about humans in a way that we would endorse is practically intractable. Advanced systems will likely *understand* human ethics and psychology at some point, but getting a system to internally act according to what *any* plausible ethics recommends is harder.
4. If the goal the AI is pursuing isn’t fundamentally centered on human values, then the best way to optimize that usually involves getting rid of all humans. Humans would shut the AI off in this case, which reduces how well the goal is achieved, and we’re using plenty of important resources anyway. By now there is a good amount written on “instrumental drives” like this that are relatively goal independent. There are even some theorems, as in Turner’s collection of power-seeking results (https://arxiv.org/abs/2206.13477). It doesn’t take any particular malice to decide that a goal is better achieved if we aren’t in the way.
5. Even small misalignments with human values produce terrible results that we wouldn’t endorse. Human value is complex and fragile, so that even if we aren’t literally wiped out the future is much worse off, by our lights, if we don’t strongly succeed here.
6. We only have to fail at this *once* to have a serious problem. It’s not really enough to just generally get it right, or make some pretty good systems the first time. If there is any level of “safety net” it’s not clear how we would get it.
So 4) argues danger-by-default, with 5) somewhat enhancing the problem. 3) argues that we don’t know how to get ourselves out of the dangerous regime, and that we in fact won’t get out without very careful planning that not many people are doing right now. This implies that we stand a serious risk of making a system that “wants” to harm us. 1), 2) and 6) argue that there are reasons to think that we can’t cooperate well enough to avoid this, even though it’s obviously a bad idea. Another point I would emphasize is that consciousness isn’t required for any of this. What matters is making systems capable enough to overpower us.
There are more detailed writings of course, including out of an increasing number of academic establishments like BERI and CHAI at Berkeley, and the FHI at Oxford. It might be better to layout which of the above steps you find so implausible that the risk isn’t worth acting on, or what perspective you would adopt instead.
(I also don’t expect “trust but verify” to extend out to the real world. The most practical attempt at doing this is OpenAI’s debate method based on PH>P. For such a strong complexity-theoretic result it seems to fail pretty early, and fooling people in realistic even mildly open-ended settings is not that hard. There’s more work to be done in that direction for sure, but so far I wouldn’t bet my life on it.)
Note that the notion of “trust but verify” was not coined about simple systems that spit out information, but about humans – namely the Americans vs Russians – that actually had very little trust in one another.
You can assume that the AI may be a malicious agent, but still interact with it in a useful way.
Humans themselves don’t have values that align with one another, but we still manage to collaborate.
As hinted by its name, “artificial intelligence” is often used to achieve human capabilities, and specifically to achieve economic efficiency by replacing humans in particular jobs, including drivers, call center operators, personal assistants and more.
Just like we did not rely on the goodness of the humans that did these jobs, we don’t need the AI to be “aligned” for it to do these jobs. None of the humans in these jobs have gotten access to the nuclear launch code, and neither will the AI.
Thanks for the reply! I’m not sure how to best organize my thoughts on this, so I’m just responding to each point roughly in order. Sorry if this looks disjointed.
I admit it doesn’t put me at ease to hear a safety strategy descended from muddling through the Cold War. Creating more situations where that’s the best we have is a serious problem! Going directly for ‘trust but verify’ seems like designing a nuclear reactor and saying “well we don’t have to think about designing the reactor itself with those ‘safety principles’, we can just surround it in a concrete dome.” The usual way to design beneficial technology is to build its internal mechanisms to be safe by default. If you’re in even a metaphorically adversarial relationship with technology something has gone terribly wrong, so I’m not sure why you see attempted containment like this as a good alternative to alignment-style work. Building a potentially harmful black box that needs constant active vigilance to be used is already unacceptably close to causing damage, if it can at all be avoided.
In the article you say “just as with humans, I wouldn’t try to make AI systems moral” as if the difference between AI and humans is similar to the differences between humans themselves. If the AI merely wasn’t the Dalai Lama, I wouldn’t be strongly concerned. But the human parallel is a *huge* thing to assume, and the people doing alignment work are doing it because they don’t think it holds: even a basic level of cooperation or sensible extrapolation doesn’t happen without intentional design. E.g. one great property would be if the AI could judge actions with the principle “I’ll negatively score actions that most humans would strongly disapprove of, even though I could do them”, or “This solution involves ideas humans don’t understand, so I should avoid doing it since I can’t know what behaving correctly means here”. A main theme of alignment research is that we don’t even know how to install very basic principles like this, not that we need every AI to be some kind of moral philosopher. A lot of the intuitive picture of “don’t cause problems”, once you try to actually spell it out, rests on internal motivation from basic ethics that we generally don’t think about.
When humans *really* have values that don’t align with each other, the result is often horrific. “We don’t hate you, you’re just on land that we think is ours” didn’t historically end in cooperation unless both sides were strong enough to make it the selfish strategy. And this is among humans who mostly understand each other, suffer when they hurt others, and have many values in common. I think that “we still manage to collaborate” requires a lot more common ground than you seem to be assuming, and it doesn’t come for free. Especially not from some technical artifact that isn’t built like a human at all.
I think part of the difference in opinion here is also the picture of what the future will look like. Your picture seems to involve no one giving an AI control over something big enough to be potentially dangerous, and running everything by human overseers who can fully understand the AI’s plans and potential consequences (enough to detect any clever deception?), but that seems unlikely to me. I guess the standard term in these circles is that you think we would only make “Tool AIs” that don’t have independent agency and stay well within human-understandable bounds, but many incentives point away from that. It’s also yet another thing on the list that might *also* be helpful but that we don’t actually know how to do, or even specify properly.
First of all, assuming adversarial failures of pieces of technology is very standard – this is what “Byzantine failures” mean. Also systems like cryptocurrencies are exactly about trying to decentralize and reduce trust.
My intuition is it would be more productive to surround pieces that do useful work (e.g answer phones and make restaurant reservations, be personal assistants etc) with guardrails on what they are allowed to access than to try to program them with some sense of morality.
We have a long history of building systems around human or technological components that are not trusted. We have no history of trying to program in morals.
Re your point yes I think we would use AI to do the jobs many humans do today, but these humans don’t need the nuclear launch codes to do their jobs and neither will the AI