
(Next post: Lecture 1 – a blitz through classical statistical learning theory . See also all seminar posts)
This semester I am teaching a seminar on the theory of machine learning. For the first lecture, I would like to talk about what is the theory of machine learning. I decided to write this (very rough!) blog post mainly to organize my own thoughts.
In any science, ML included, the goals of theory and practice are not disjoint. We study the same general phenomena from different perspectives. We can think of questions in computation at a high level as trying to map the unknown terrain of the computational cost of achieving certain quality of output, given some conditions on the input.

Practitioners aim to find points on this terrain’s practically relevant regions, while theoreticians are more interested in its broad landscape, including at points far out into infinity. Both theoreticians and practitioners care about discontinuities, when small changes in one aspect correspond to large changes in another. As theoreticians, we care about computational/statistical tradeoffs, particularly about points where a small difference in quality yields an exponential difference in time or sample complexity. In practice, models such as GPT-3 demonstrate that a quantitative increase in computational resources can correspond to a qualitative increase in abilities.
Since theory and practice study the same phenomenon in different ways, their relation can vary. Sometimes theory is forward-looking or prescriptive – giving “proof of concepts” results that can inspire future application or impossibility results that can rule out certain directions. Sometimes it is backward-looking or descriptive – explaining phenomena uncovered by experiments and putting them in a larger context.
What is machine learning?
Before we talk about what is machine-learning theory, we should talk about what is machine learning. It’s common to see claims of the form “machine learning is X”:
- Machine learning is just statistics
- Machine learning is just optimization
- Machine learning is just approximation or “curve fitting”
and probably many more.
I view machine learning as addressing the following setup:

There is a system 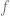
For example, a self-driving car is “successful” if it gets passengers from point A to point B safely, quickly, and comfortably. It is “unsuccessful” if it gets into accidents, takes a long time, or drives in a halting or otherwise uncomfortable manner.
Three levels of indirection
The system
- The model gap: We do not optimize over all possible systems, but rather a small subset of such systems (e.g., ones that belong to a certain family of models).
- The metric gap: In almost all cases, we do not optimize the actual measure of success we care about, but rather another metric that is at best correlated with it.
- The algorithm gap: We don’t even optimize the latter metric since it will almost always be non-convex, and hence the system we end up with depends on our starting point and the particular algorithms we use.
The magic of machine learning is that sometimes (though not always!) we can still get good results despite these gaps. Much of the theory of machine learning is about understanding under what conditions can we bridge some of these gaps.
The above discussion explains the “machine Learning is just X” takes. The expressivity of our models falls under approximation theory. The gap between the success we want to achieve and the metric we can measure often corresponds to the difference between population and sample performance, which becomes a question of statistics. The study of our algorithms’ performance falls under optimization.
The metric gap is perhaps the widest of them all. While in some settings (e.g., designing systems to play video games) we can directly measure a system’s success, this is typically the exception rather than rule. Often:
- The data we have access to is not the data the system will run on and might not even come from the same distribution.
- The measure of success that we care about is not necessarily well defined or accessible to us. Even if it was, it is not necessarily in a form that we can directly optimize.
Nevertheless, the hope is that if we optimize the hell out of the metrics we can measure, the system will perform well in the way we care about. In other words:

A priori, it is not clear that this should be the case, and indeed it’s not always is. Part of the magic of auto-differentiation is that it allows optimization of more complex metrics that match more closely with the success metric we have in mind. But, except for very special circumstances, the two metrics can never be the same. The mismatch between the goal we have and the metric we optimize can manifest in one of the following general ways:
- “No free lunch” or Goodhart’s law: If we optimize a metric
then we will get a system that does very well at
- “It’s not the destination, it’s the journey” or Anna Karenina principle: All successful systems are similar to one another, and hence if we make our system successful with respect to a metric

At the moment, we have no good way to predict when a system will behave according to Goodhart’s law versus the Anna Karenina principle. It seems that when it comes to learning representations, machine learning systems follow the Anna Karenina principle: all successful models tend to learn very similar representations of their data. In contrast, when it comes to making decisions, we get manifestations of Goodhart’s law, and optimizing for one metric can give very different results than the other.
The model gap is the gap between the set of all possible systems and the set that we actually optimize over. Even if a system can be captured as a finite function (say a function mapping 
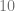
This raises the question of whether we should expect a realizable system to exist, let alone for us to find it. Often machine learning is used in artifical intelligence applications, where we are trying to mimic human performance. In such cases, human performance is an “existence proof” that some reasonably-sized circuit is successful in the goal. But whether this circuit can be embedded in our model family is still an open question.
Remember when I said that sometimes it’s not about the journey but about the destination? I lied. The algorithm gap implies that in modern machine learning, there is a certain sense in which it is always about the journey. In modern machine learning, the system 


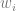
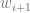
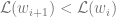
Modern machine learning systems are non convex, which means that the final point 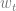
Types of theory for machine learning (and for CS in general)
Given the above discussion, what kind of theoretical results should we expect in machine learning? Let’s try to classify the type of results we see in general theoretical computer science. In the discussion below, I will focus on the limitations of these theoretical results and use humorous names, but make no mistake: all of these categories correspond to valuable theoretical insights.
End to end analysis
The quicksort algorithm provides a canonical example of algorithm analysis. At this point, we have a reasonably complete understanding of quicksort. We can analyze the distribution of its running time down to the constant.
Hence we have an efficient algorithm, used in practice, with rigoroulsy proven theorems that precisely characterize its performance. This is the “gold standard” of analysis, but also an unrealistic and unachievable goal in almost any other setting.
Proof of concept
A more common situation is that we have algorithms that work in practice and algorithms with rigorous analysis, but they are not the same algorithms. A canonical example is linear programming. The simplex algorithm often works well in practice but was known to take exponential time on certain instances. For a long time, it was an open question whether or not there is an algorithm for linear programming that take polynomial time in the worst case.
In 1979, Khachiyan gave the Ellipsoid algorithm that runs in polynomial time, but with a polynomial so large that it is impractical. Still, the Ellipsoid algorithm was a great breakthrough, giving hope for better algorithms and a new approach for defining progress measures for linear programming instances. Indeed in 1984, Karmarkar came up with the interior points algorithm, with much better time dependence.
The interior-point algorithm is practical and often outperforms the simplex method on large enough instances. However, the algorithm as implemented is not identical to the one analyzed- implementations use different step sizes and other heuristics for which we do not have a precise analysis.
Nevertheless, even if (unlike quicksort) the rigorously analyzed algorithm is not identical to the practical implementations, the story of linear programming shows how crucial “proofs of concept” can be to introducing new ideas and techniques.
The flip side of “proof of concept” results are impossiblity results that rule out even “proof of concept ” algorithms. Impossibility results always come with fine print and caveats (for example, NP-hardness results always refer to worst case complexity). However, they still teach us about the structure of the problem and help define the contours of what we can expect to achieve.
Character witness
“End to end analysis” is when we can prove the guarantees we need on algorithms we actually want to use. “Proof of concept” is when we prove the guarantees we need on impractical algorithms. A “character witness” result is when we prove something positive about an algorithm people use in practice, even if that positive property falls short of the guarantees we actually want.
While the term “character witness” sounds derogatory, such results can sometimes yield truly profound insights. A canonical example again comes from linear programming. While the simplex algorithm can be exponential in the worst case, in a seminal work, Spielman and Teng showed that it does run in polynomial-time if the input is slightly perturbed- this is so-called smoothed analysis. While the actual polynomial and the level of perturbation do not yield practical bounds, this is still an important result. It gives formal meaning to the intuition that the simplex only fails on “pathological” instances and initiated a new mode of analyzing algorithms between worst-case and average-case complexity.
In machine learning, a “character witness” result can take many forms. For example, some “character witness” results are analyses of algorithms under certain assumptions on the data, that even if not literally true, seem like they could be “morally true”. Another type of “character witness” result shows that an algorithm would yield the right results if it is allowed to run for an infinite or exponentially long time. Evaluating the significance of such results can be challenging. The main question is whether the analysis teaches us something we didn’t know before.
A third type of “character witness” results are quantitative bounds that are too weak for practical use but are still non-vacuous. For example, approximation algorithms with too big of an approximation factor, or generalization bounds with too big of a guaranteed gap. In such cases, one would hope that these bounds will be at least correlated with performance: algorithms with better bounds will also have higher quality output.
Toy problems
The name “toy problem” also sounds derogatory, but toy problems or toy models can be extremely important in science, and machine learning is no different. A toy model is a way to abstract the salient issues of a model to enable analysis. Results on “toy models” can teach us about general principles that hold in more complex models.
When choosing a toy model, it is important not to mistake models that share superficial similarity with models that keep the salient issues we want to study. For example, consider the following two variants of deep neural networks:
- Networks that have standard architecture except that we make them extremely wide, with the width tending to infinity independently of all other parameters.
- Networks where all activation functions are linear.
Since the practical intuition is that bigger models are better, it may seem that such “ultra-wide” models are not toy models at all and should capture state of the art deep networks. However, the neural tangent kernel results show that these models become kernel models that do not learn their representation at all.
Intuitively, making activation functions linear seems pointless since the composition of linear functions is linear, and hence such linear networks are no more expressive than a layer one linear net. Thus such linear networks seem too much of a “toy model” (maybe a “happy meal model”?). Yet, it turns out that despite their limited expressivity, deep linear networks capture an essential feature of deep networks- the bias induced by the gradient descent algorithm. For example, running gradient descent on a depth two linear network translate to regularizing by a proxy of rank. In general, gradient descent on a deep linear network induces a very different geometry on the manifold of linear functions.
Hence, although the first model seems much more “real” than the second one, there are some deep learning questions where the second model is more relevant.
Theory without theorems
One might think that the whole point of theory is to provide rigorous results: if we are not going to prove theorems, we might as well use benchmarks. Yet, there are important theoretical insights we can get from experiments. A favorite example of mine is the result of Zhang, Bengio, Hardt, Recht, and Vinyals that deep neural networks can fit random labels. This simple experiment ruled out in one fell swoop a whole direction for proving generalization bounds on deep nets. A theory work does not have to involve theorems: well-chosen experiments can provide important theoretical insights.
Conclusion
The above was a stream-of-consciousness and very rough personal overview of questions and results in ML theory. In the coming seminar we will see results of all the types above, as well as many open questions.
Acknowledgements: Thanks to Yamini Bansal and Preetum Nakkiran for helpful comments (though they are not to blame for any mistakes!)

Great post, Boaz! If I were not taking time off this spring, I would definitely be enrolling in this course. Sounds incredible.
Looking forward to seeing you again soon, hopefully in the fall 🙂
Thanks Andrew!!
Very nice post! (And memorable drawings.)
Thank you!!