
Blake Bordelon, Haozhe Shan, Abdul Canatar, Boaz Barak, Cengiz Pehlevan
[Boaz’s note: Blake and Haozhe were students in the ML theory seminar this spring; in that seminar we touched on the replica method in the lecture on inference and statistical physics but here Blake and Haozhe (with a little help from the rest of us) give a great overview of the method and its relations to ML. See also all seminar posts.]
See also: PDF version of both parts and part 2 of this post.
I. Analysis of Optimization Problems with Statistical Physics
In computer science and machine learning, we are often interested in solving optimization problems of the form

where 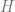

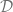
Here are a few examples of problems that fit this form:
- In supervised learning,
a set of neural network weights and
- We may want to find the most efficient way to visit all nodes on a graph. In this case
(or a very large number ) if it doesn’t encode a valid path.
- Satisfiability:
is a collection booleans which must satisfy a collection of constraints. In this case the logical constraints (clauses) are the parameters
can be the number of constraints violated by
- Recovery of structure in noisy data:
II. The Goal of the Replica Method
The replica method is a way to calculate the value of some statistic (observable in physics-speak) 
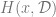

In Example 1 (supervised learning), the observable may be the generalization error of a chosen algorithm (e.g. a linear classifier) on a given dataset. For Example 2 (path), this could be the cost of the best path. For Example 3 (satisfiability), the observable might be whether or not a solution exists at all for the problem. In Example 4 (noisy data), the observable might be the quality of decoded data (distance from ground truth under some measure).
An observable like generalization error obviously depends on
For instance, in Example 1, we can draw all of our training data from a distribution. For each random sample of data points 
To give away a “spolier”, towards the end of this note, we will see how to use the replica method to give accurate predictions of performance for noisy least square fitting and spiked matrix recovery.

Generalization gap in least squares ridge regression, figure taken from Canatar, Bordelon, and Pehlevan

Performance (agreement with planted signal) as function of signal strength for spiked matrix recovery, as the dimension grows, the experiment has stronger agreement with theory. See also Song Mei’s exposition
A. What do we actually do?
Now that we are motivated, let’s see what quantities the replica method attempts to obtain. In general, given some observable 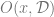

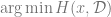
In other words, we want to compute the following quantity:
![\text{Desired quantity } = \mathbb{E}_{\mathcal{D}} \mathbb{E}_{x \in \text{arg}\min H(x,\mathcal{D})} \left[ O(x, \mathcal{D}) \right]](https://s0.wp.com/latex.php?latex=%5Ctext%7BDesired+quantity+%7D+%3D+%5Cmathbb%7BE%7D_%7B%5Cmathcal%7BD%7D%7D+%5Cmathbb%7BE%7D_%7Bx+%5Cin+%5Ctext%7Barg%7D%5Cmin+H%28x%2C%5Cmathcal%7BD%7D%29%7D+%5Cleft%5B+O%28x%2C+%5Cmathcal%7BD%7D%29+%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
The above equation has two types of expectation- over the disorder 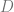
The physics convention is to
- use
for the expectation of a function
over the disorder
- use
for the expectation of a function
over
.
Using this notation, we can write the above as

where 

The ultimate goal of the replica method is to express

but it will take some time to get there.
B. The concept of “self-averaging” and concentration
Above, we glossed over an important distinction between the “typical” value of 





For example, suppose that 



![X \in [n/2 \pm O(\sqrt{n})]](https://s0.wp.com/latex.php?latex=X+%5Cin+%5Bn%2F2+%5Cpm+O%28%5Csqrt%7Bn%7D%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)

In contrast the random variable 




The example above is part of a more general pattern. Often even if a variable 
![\exp\left( \mathbb{E} [\log Y] \right)](https://s0.wp.com/latex.php?latex=%5Cexp%5Cleft%28+%5Cmathbb%7BE%7D+%5B%5Clog+Y%5D+%5Cright%29&bg=ffffff&fg=666666&s=0&c=20201002)
![\mathbb{E}[Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY%5D&bg=ffffff&fg=666666&s=0&c=20201002)
C. When is using the replica method a good idea?
Suppose that we want to compute a quantity of the form above. When is it a good idea to use the replica method to do so?
Generally, we would want it to satisfy the following conditions:
- The learning problem is high dimensional with a large budget of data. The replica method describes a thermodynamic limit where the system size and data budget are taken to infinity with some fixed ratio between the two quantities. Such a limit is obviously never achieved in reality, but in practice sufficiently large learning problems can be accurately modeled by the method.
- The loss or the constraints are convenient functions of
- Averages over the disorder in
- The statistic that we are interested in is self-averaging.
If the above conditions aren’t met, it is unlikely that this problem will gain much analytical insight from the replica method.
III. The Main Conceptual Steps Behind Replica Calculations
We now describe the conceptual steps that are involved in calculating a quantity using the replica method.
They are also outlined in this figure:

Step 1:”Softening” Constraints with the Gibbs Measure
The uniform measure on minimizers

where 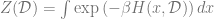

Hence we can write
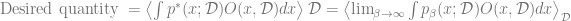
Physicists often exchange the order of limits and expectations at will, which generally makes sense in this setting, and so assume

Thus general approach taken in the replica method is to derive an expression for the average observable for any 

To compute the thermal average of

One can then check that

Hence our desired quantity can be obtained as

or (assuming we can again exchange limits at will):
![\text{Desired quantity } = \lim_{\epsilon \to 0} \tfrac{1}{\epsilon}\left[ \lim_{\beta \to \infty} \left< \log Z(\mathcal D, \epsilon) \right>{\mathcal D} - \lim_{\beta \to \infty} \left< \log Z(\mathcal D, 0) \right>_{\mathcal D}\right]](https://s0.wp.com/latex.php?latex=%5Ctext%7BDesired+quantity+%7D+%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D+%5Ctfrac%7B1%7D%7B%5Cepsilon%7D%5Cleft%5B+%5Clim_%7B%5Cbeta+%5Cto+%5Cinfty%7D+%5Cleft%3C+%5Clog+Z%28%5Cmathcal+D%2C+%5Cepsilon%29+%5Cright%3E%7B%5Cmathcal+D%7D+-+%5Clim_%7B%5Cbeta+%5Cto+%5Cinfty%7D+%5Cleft%3C+%5Clog+Z%28%5Cmathcal+D%2C+0%29+%5Cright%3E_%7B%5Cmathcal+D%7D%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
We see that ultimately computing the desired quantity reduces to computing quantities of the form

for the original or modified partition function 

Averaging over 
⚠ What Concentrates?: It is not just an algebraic convenience to average
instead of averaging
itself. When the system size
is large,
concentrates around its average. Thus, the typical behavior of the system can be understood by studying the quenched average
The partition function
(known as the “annealed average”) and
(known as the “quenched average”) could differ subtantially. For more information, please consult Mezard and Montanari’s excellent book, Chapter 5.
Step 2: The Replica Trick
Hereafter, we use 
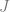


For the limit to make sense, 
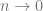
Recall that under the Gibbs distribution 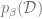
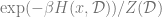

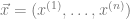
Since the partition function 

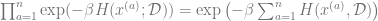
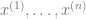
Now since each 
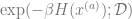

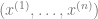
(The discussion on 
Hence
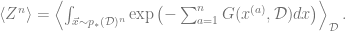
Step 3: The Order Parameters
The above expression is an expectation of an integral, and so we can switch the order of summation, and write it also as

It turns out that for natural energy functions (for example when 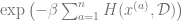

That is, rather than depending on all of these 

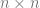

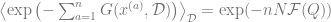
Hence we can replace the integral over 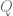

where the measure 
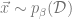
Since 
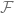

Once we arrive at this expression, the configurational average of 

⚠ Bad Math Warning: there are three limits,
, and
Coming up: In part two of this blog post, we will explain the replica symmetric assumption (or “Ansatz” in Physics-speak) on the order parameters

Thank you for the amazing post. Unfortunately, I’m lost at Step:2, specifically in the paragraph where you introduce G. What do you mean each x^{(a)} is weighted with the factor of \exp(-\beta H)?