
Scribe notes by Franklyn Wang
Previous post: Robustness in train and test time Next post: Natural Language Processing (guest lecture by Sasha Rush). See also all seminar posts and course webpage.
lecture slides (pdf) – lecture slides (Powerpoint with animation and annotation) – video
Digression: Frequentism vs Bayesianism
Before getting started, we’ll discuss the difference between the two dominant schools of thought in probability: Frequentism and Bayesianism.
Frequentism holds that the probability of an event is the long-run average proportion of something that happens many, many times, so a coin has 50% probability of being heads if on average half of the flips are heads. One consequence of this framework is that a one-off event like Biden winning the election doesn’t have any probability as by definition they can only be observed once.
Bayesians reject this model of the world. For example, a famous Bayesian, Jaynes, even wrote that “probabilities are frequencies only in an imaginary universe.”
While these branches of thought are different, generally the answers to most questions are the same, so the distinction will not matter for this class. However, these branches of thought inspire different types of methods, which we now discuss.
For example, suppose that we have a probability distribution 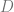





A frequentist does this by defining a family 
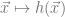


These equations amount to saying that 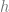
By contrast, a Bayesian approaches this task by assuming that 
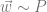

Then, let 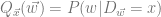



In fact, Bayesian approaches extend beyond this, as if you can sample from a posterior you can do more than just minimize a loss function.
In Bayesian inference, chosing the prior 
These two minimization equations con sometimes lead to identical results, but often in practice they work out differently once we introduce computational constraints into the picture. In the frequentist approach, we generally constrain the family of mappings 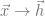

Part 1. An introduction to Statistical Physics

Compare water and ice. Water is hotter, and the molecules move around more. In ice, by contrast, the molecules are more stationary. When the temperature increases, the objects move more quickly, and when they decrease the objects have less energy and stop moving. There are also phase transitions, where certain temperatures cause qualitative discontinuities in behavior, like solid to liquid or liquid to gas.
See video from here:

An atomic state can be thought of as 

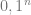
Each atomic state has a negative energy function (which we will think of as a utility function) 
![\mathbb{E}_{x \sim p}[ W(x)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D%5B+W%28x%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
Thus, an axiom of thermodynamics states that to find the true distribution, we need only look at the maximizer of
![p = \arg\max_{q} \mathbb{E}_{x \sim q}[W(x)] + \tau \cdot H(q).](https://s0.wp.com/latex.php?latex=p+%3D+%5Carg%5Cmax_%7Bq%7D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+q%7D%5BW%28x%29%5D+%2B+%5Ctau+%5Ccdot+H%28q%29.&bg=ffffff&fg=666666&s=0&c=20201002)
That is, it is the probability distribution which maximizes a linear combination of the expected negative energy and the entropy, with the temperature controlling the coefficient of entropy in this combination (the higher the temperature, the more the system prioritizes having high entropy).
The variational principle, which we prove later, states that the 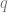

which is known as the Boltzmann Distribution. We often write this with a normalizing constant, so 
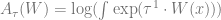
Before proving the variational principle, we will go through some examples of statistical physics.
Example: Ising Model
In the Ising model, we have 

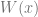
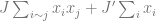



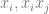
![\mathbb{E}[W(x)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BW%28x%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![\mathbb{E}[x_i]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bx_i%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![\mathbb{E}[x_i x_j]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bx_i+x_j%5D&bg=ffffff&fg=666666&s=0&c=20201002)

and a video can be found here.
This is what a low-temperature Ising model looks like – note that
The Sherrington-Kirkpatrick model is a generalization of the Ising model to a random graph, which represents a disordered mean field model. Here, 
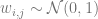

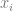

Our third example is the posterior distribution, where 


so 
Proof of the Variational Principle
Now, we prove the variational principle, which states that if 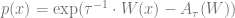
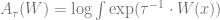

Before proving the variational principle, we make the following claim: if

Proof of claim:
Write
(where we plugged in the definition of 

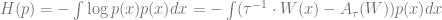
We can now rewrite this as

which means that

using the fact that 


Proof of variational principle:
Given the claim, we can now prove the variational principle.
Let

where the first equation uses our likelihood expression. This implies that 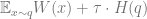

Remarks:
- When
, we have
.
- In particular, for every value of

which we’ve seen before! Note that equality holds when 
In many situations, we can compute 
Markov Chain Monte Carlo (MCMC)
An important task in statistics is to sample from a distribution 


Metropolis-Hastings Algorithm:
- Draw
at random.
- For
, choose an arbitrary

Then, 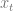

The stationary distribution is often unique, so we’ve proven that this samples from
Indeed, there are examples where convergence to the stationary distribution would take exponential time.
Note: One way to make MCMC faster is to let 
Applications of MCMC: Simulated Annealing
One application of MCMC is in simulated annealing. Suppose that we have 

To this end, we now create a sequence of Markov chains supported on 

Simulated annealing lets us begin by sampling from 


Simulated Annealing Algorithm:
- Cooling Begin
1a. Settling Now, repeatedly move from
Since simulated annealing is inspired by physical intuition, it turns out that its shortcomings can be interpreted physically too. Namely, when you cool something too quickly it becomes a glassy state instead of a ground state, which often causes simulated annealing to fail, and for this algorithm to get stuck in local minima. Note how this is fundamentally a failure mode with MCMC – it can’t mix quickly enough.
See this video for an illustration of simulated annealing.
Part 2: Bayesian Analysis
Note that the posterior of 


We now have 
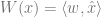


Sampling from a Tree-Structured Distribution
Now how do we sample from a tree-structured distribution? The most direct way is by calculating the marginals. While marginalization is generally quite difficult, it is much more tractable on certain types of graphs. For a sense of what this entails, suppose that we have the following tree-structured statistical model:
 ,
,
whose joint PDF is 
(The unusual notation is chosen so that the relationships between the marginals is clean. The log-density in question is a Laplacian Quadratic Form.)
Then one can show that if the marginal of 

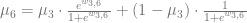
This will give six linear equations in six unknowns, which we can solve. Once we can marginalize a variable, say, 
This algorithm (with some modifications) also works for general graphs, but what it represents on general graphs is not the exact marginal, but rather an extension of that graph to a tree.
General Exponential Distributions
Now let’s try to develop more theory for exponential distributions. Let the PDF of this distribution be 
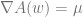
By the variational principle, we have that among all distributions with the same sufficient statistics as a given Boltzmann distribution, the true one maximizes the entropy, so

An analagous idea gives us

so 
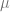
The important consequence of these two facts is that in principle,
Now, how do we do this algorithmically? Using 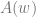


On the other hand, if you have 
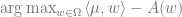

Thus going from
When
Examples of Exponential Distributions
There are many examples of exponential distributions, which we now give.
- High-Dimensional Normals:
,
- Ising Model:
,
. A sufficient statistic for these is
, a fact which we will invoke repeatedly.
- There’s many many more, including Gaussian Markov Random Fields, Latend Dirchlet Allocation, and Mixtures of Gaussians.

Going from canonical parameters to mean parameters
Now, we show how to go from 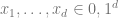
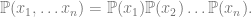
Recall that the partition function can be computed as
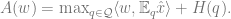
where 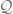
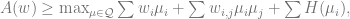
where 
![K = { \mu\in [0,1]^d | \sum \mu_i = 1 }](https://s0.wp.com/latex.php?latex=K+%3D+%7B+%5Cmu%5Cin+%5B0%2C1%5D%5Ed+%7C+%5Csum+%5Cmu_i+%3D+1+%7D&bg=ffffff&fg=666666&s=0&c=20201002)
We can generally maximize concave functions over a convex set such as 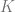
CAVI Algorithm
- Let
- Repatedly choose values of
(possibly at random, or in a loop.)
2a. Update(where
represents the non-

Part 3. Solution landscapes and the replica method
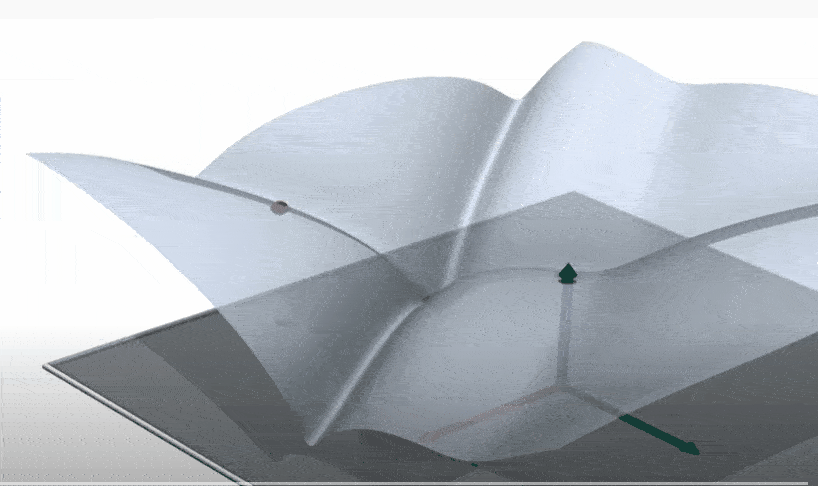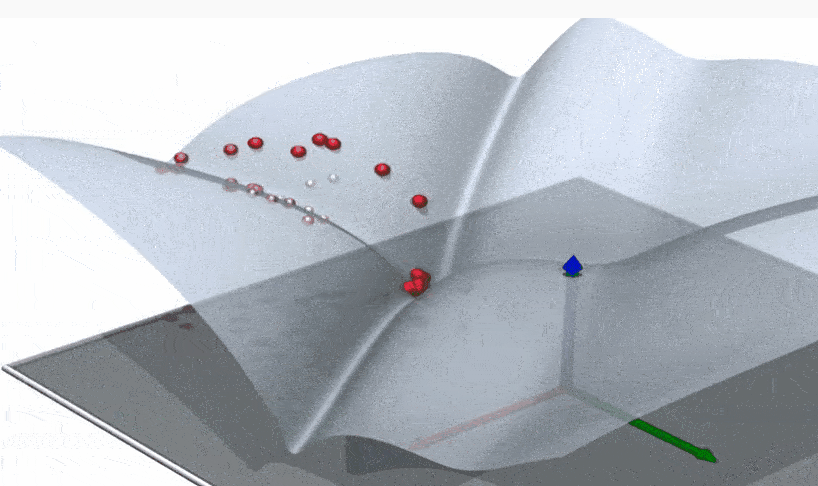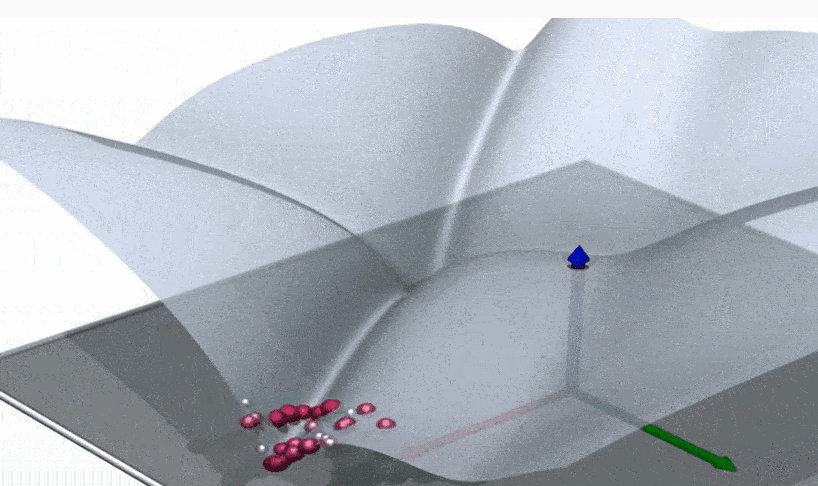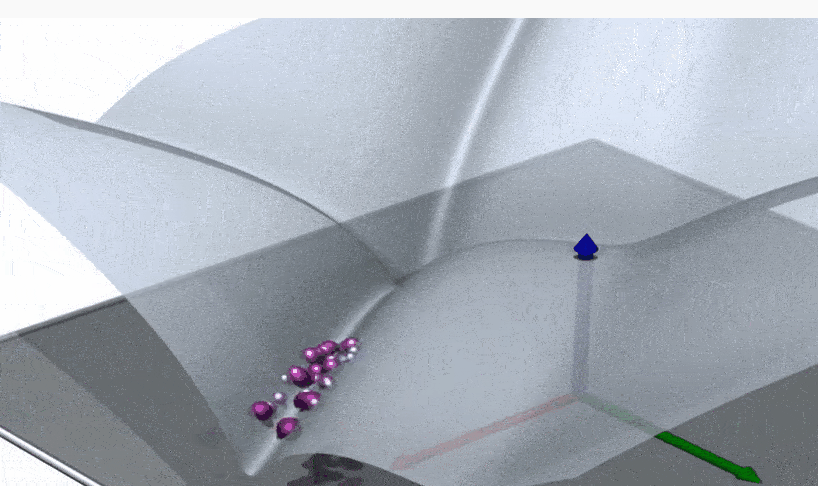
This part is best explained visually. Suppose that we have a Boltzman distribution. In the infinite temperature limit the this is the uniform distribution, distributed over the entire domain. As you decrease the temperature, the support’s size decreases. (Note: The gifs below are just cartoons. These pretend as if the probability distribution is always uniform over a subset. Also, in most cases of interest for learning, only higher order derivatives of entropy will be discontinuous.)

Sometimes there’s a discontinuity in entropy, and the entropy “suddenly drops” in a discontinuity. Often the entropy function itself is continuous, but the derivatives are not continuous at that point – a higher order phase transition.
Sometimes the geometry of the solution space undergoes a phase transition as well, with it “shattering” to several distinct clusters.

The replica method
Note: We will have an extended post on the replica method later on.
If you sampled 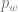
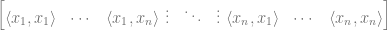
we approximate as

where
Suppose
![\mathbb{E}_{w}[A(w)] = \mathbb{E}_{w}\left[ \log \int \exp(\langle w, \hat{x} \rangle)\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bw%7D%5BA%28w%29%5D+%3D+%5Cmathbb%7BE%7D_%7Bw%7D%5Cleft%5B+%5Clog+%5Cint+%5Cexp%28%5Clangle+w%2C+%5Chat%7Bx%7D+%5Crangle%29%5Cright%5D%2C&bg=ffffff&fg=666666&s=0&c=20201002)
which is the expected free energy. However, it turns out to be much easier to find 
![\mathbb{E}_{w} [A(w)] = \lim{n \rightarrow 0} \frac{\mathbb{E}_{w} [\text{exp}(n \cdot A(w))] - 1}{n}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bw%7D+%5BA%28w%29%5D+%3D+%5Clim%7Bn+%5Crightarrow+0%7D+%5Cfrac%7B%5Cmathbb%7BE%7D_%7Bw%7D+%5B%5Ctext%7Bexp%7D%28n+%5Ccdot+A%28w%29%29%5D+-+1%7D%7Bn%7D&bg=ffffff&fg=666666&s=0&c=20201002)
This should already smell weird, because

which we can write as

Now these 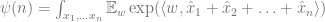
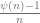
Generally speaking, ![\mathbb{E}_{w} [\exp(w, \hat{x}_1 + \cdots + \hat{x}_n)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bw%7D+%5B%5Cexp%28w%2C+%5Chat%7Bx%7D_1+%2B+%5Ccdots+%2B+%5Chat%7Bx%7D_n%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
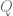
Examples:
We’ll now give an example of how this is useful. Consider a spiked matrix/tensor model, where we observe 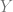

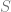


and we want to analyze 
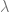

Other examples include Teacher-student models, where 

Symmetry breaking
Lastly, we’ll talk about replica symmetry breaking. Sometimes, discontinuities don’t just make the support smaller, but actually break the support into many different parts. For example, at this transition the circle becomes the three green circles.
When this happens, we can no longer make our overlap matrix assumption, as there are now asymmetries between the points. This leads to the overlap matrix being striped, in the fashion one would anticipate.

Sometimes, the support actually breaks into infinitely many parts, in a phenomenon called full replica symmetry breakng.
Finally, some historical notes. This “plugging in zero” trick was introduced by Parisi approximately 30 years ago, receiving a standing ovation at the ICM. Since then, some of those conjectures have been rigorously formalized, but many haven’t. It is still very impressive that Parisi was able to do it.

Great lecture (the video). Learned some things I always wanted to know. (Like why simulated annealing works better if only a single coordinate gets modified in each step. That was a lesson I had learned the hard way.) Reminds me a bit on Luca Trevisan’s series on online optimization. I guess I should try to watch or study your other lectures from this series too.