
Scribe notes by Praneeth Vepakomma
Previous post: Unsupervised learning and generative models Next post: Inference and statistical physics. See also all seminar posts and course webpage.
lecture slides (pdf) – lecture slides (Powerpoint with animation and annotation) – video
In this blog post, we will focus on the topic of robustness – how well (or not so well) do machine learning algorithms perform when either their training or testing/deployment data differs from our expectations.

We will cover the following areas:
- Math/stat refresher
- Multiplicative weights algorithm
- Robustness
- train-time
- robust statistics
- robust mean estimation
- data poisoning
- test-time
- distribution shifts
- adversarial perturbations
- train-time
📝Math/stat refresher
KL refresher
The KL-divergence between the probability distributions is the expectation of the log of probability ratios:

KL-divergence is always non-negative and can be decomposed as the difference between negative entropy and cross-entropy. The non-negativity property thereby implies that 


Introduction to concentration
Consider a Gaussian random variable 
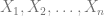
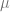
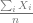
Therefore the standard deviation of the empricial average is smaller than the standard deviation of each of the 


![P[|\sum_i X_i - \mu.n| \geq \epsilon n] \approx \exp(-\epsilon^2 n)](https://s0.wp.com/latex.php?latex=P%5B%7C%5Csum_i+X_i+-+%5Cmu.n%7C+%5Cgeq+%5Cepsilon+n%5D+%5Capprox+%5Cexp%28-%5Cepsilon%5E2+n%29+&bg=ffffff&fg=666666&s=0&c=20201002)
Matrix notations
Norms
We denote the spectral norm of a matrix 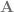
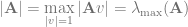
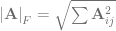
PSD Ordering
We use the matrix ordering 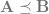
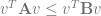

![\mathbf{A} \in [a,b] \mathbf{I}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BA%7D+%5Cin+%5Ba%2Cb%5D+%5Cmathbf%7BI%7D&bg=ffffff&fg=666666&s=0&c=20201002)

Matrix/vector valued random variables
Vector valued normals: If 
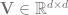


![\mathbb{E}\left[x_{i}\right]=\mu_{i}, \;\; \mathbb{E}\left[\left(x_{i}-\mu_{i}\right)\left(x_{j}-\mu_{j}\right)\right]=\mathbf{V}_{i, j}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5Bx_%7Bi%7D%5Cright%5D%3D%5Cmu_%7Bi%7D%2C+%5C%3B%5C%3B+%5Cmathbb%7BE%7D%5Cleft%5B%5Cleft%28x_%7Bi%7D-%5Cmu_%7Bi%7D%5Cright%29%5Cleft%28x_%7Bj%7D-%5Cmu_%7Bj%7D%5Cright%29%5Cright%5D%3D%5Cmathbf%7BV%7D_%7Bi%2C+j%7D&bg=ffffff&fg=666666&s=0&c=20201002)
For every psd matrix V, there exists a Normal distribution where
![\mathbb{E}\left[\left(x_{i}-\mu_{i}\right)\left(x_{j}-\mu_{j}\right)\right]=\mathbf{V}_{i, j}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cleft%28x_%7Bi%7D-%5Cmu_%7Bi%7D%5Cright%29%5Cleft%28x_%7Bj%7D-%5Cmu_%7Bj%7D%5Cright%29%5Cright%5D%3D%5Cmathbf%7BV%7D_%7Bi%2C+j%7D&bg=ffffff&fg=666666&s=0&c=20201002)
Standard vector-valued normal: This refers to the case when 

![\mathbb{E} x=\overrightarrow{0},\;\; \mathbb{E}\left[x x^{\top}\right]=I \quad\left(\begin{array}{l} \mathbb{E} x_{i}^{2}=1 \ \mathbb{E} x_{i} x_{j}=0 \text { for } i \neq j \end{array}\right)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+x%3D%5Coverrightarrow%7B0%7D%2C%5C%3B%5C%3B+%5Cmathbb%7BE%7D%5Cleft%5Bx+x%5E%7B%5Ctop%7D%5Cright%5D%3DI+%5Cquad%5Cleft%28%5Cbegin%7Barray%7D%7Bl%7D+%5Cmathbb%7BE%7D+x_%7Bi%7D%5E%7B2%7D%3D1+%5C+%5Cmathbb%7BE%7D+x_%7Bi%7D+x_%7Bj%7D%3D0+%5Ctext+%7B+for+%7D+i+%5Cneq+j+%5Cend%7Barray%7D%5Cright%29&bg=ffffff&fg=666666&s=0&c=20201002)
Matrix concentration
For scalar random variables, we saw that if 
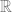
![\mathrm{Pr}\left[\left|\sum Y_{i}-\mu \cdot n\right| \geq \epsilon n\right] \approx \exp \left(-\epsilon^{2} n\right)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D%5Cleft%5B%5Cleft%7C%5Csum+Y_%7Bi%7D-%5Cmu+%5Ccdot+n%5Cright%7C+%5Cgeq+%5Cepsilon+n%5Cright%5D+%5Capprox+%5Cexp+%5Cleft%28-%5Cepsilon%5E%7B2%7D+n%5Cright%29&bg=ffffff&fg=666666&s=0&c=20201002)
If the random variables were vectors instead, we can easily generalize this to 
Matrix Bernstein inequality:
If 

![\mathrm{Pr}\left[\left|\sum Y_{i}-\mu \cdot n\right| \geq \epsilon n\right] \approx d \cdot \exp \left(-\epsilon^{2} n\right)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D%5Cleft%5B%5Cleft%7C%5Csum+Y_%7Bi%7D-%5Cmu+%5Ccdot+n%5Cright%7C+%5Cgeq+%5Cepsilon+n%5Cright%5D+%5Capprox+d+%5Ccdot+%5Cexp+%5Cleft%28-%5Cepsilon%5E%7B2%7D+n%5Cright%29&bg=ffffff&fg=666666&s=0&c=20201002)
Note that 
Another property that follow is the the expected norm of the difference follows

There are some long-standing conjectures and results on cases when one can get rid of this additional factor of
Trivia on log factors: For example as a tangent (as well as some trivia!) on some results of this flavor, where a 

Random matrices
For a random 

![[-2\sqrt{d},+2\sqrt{d}]](https://s0.wp.com/latex.php?latex=%5B-2%5Csqrt%7Bd%7D%2C%2B2%5Csqrt%7Bd%7D%5D&bg=ffffff&fg=666666&s=0&c=20201002)


Marchenko-Pastur distribution (for random empirical covariance matrices)
For
we have 
the eigenvalues are distributed according to the Marchenko-Pastur distribution. In the case when, 




Connections to the stability of linear regression
In the regime, when 

Digression: Multiplicative Weights Algorithm
Note: Its variants/connections include techniques/topics of, Follow The Regularized Leader / Regret Minimization / Mirror Descent. Elad Hazan’s lecture notes on online convex optimization and Arora, Hazan, Kale’s article on multiplicative and matrix multiplicative weights are a great reading source for these topics.
The following is a general setup in online optimization and online learning.
Setup:

At time 


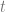
The following is the overall approach for learning to optimize in this online setup.
Overall Approach:
- Initialize
distribution over action space
. We then take a step based on this distribution and observe the incurred loss.
- Then the distribution is updated as
by letting
. i.e, if an action gave a bad outcome in terms of loss, we downweight it’s probability for the next draw of action to be taken.
is the penalty terms that governs the aggresiveness of the downweighting.
The hope is that this approach converges to a “good aggregation or strategy”. We measure the quality of the strategy using regret.

The difference between the cost we incur and the optimal action (or probability distribution over actions) in hindsight is known as the (average) regret.
Note that we compare the loss we incur with the best loss over a fixed (i.e., nonadaptive) probability distribution over the set of possible actions. It can be shown that the best such loss can always be achieved by a distribution that puts all the weight on a single action.
The following theorem bounds the regret.

The ‘prior ignorance’ term captures how good the initialization is. The ‘sensitivity per step’ term captures how aggressive the exploration is (i.e this term governs the potential difference between loss incurred at 
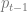
The first inequality of this theorem is always true for any 


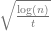

To state the ‘overall approach’, more precisely, there needs to be a normalization 
The above can be rearranged as follows upon taking log


By substituting this in below

we get the following expanded version of what the regret amounts to be:

The last equation above is due to the telescoping sum where adjacent terms cancel out except the first and last terms.

The last inequality here is because the cross-entropy is always at least as large as the entropy.
So now we have this so far
PF: Regret
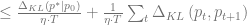
Now there is this property that if 

![\rho_{i} \in[1-\eta, 1+\eta]](https://s0.wp.com/latex.php?latex=%5Crho_%7Bi%7D+%5Cin%5B1-%5Ceta%2C+1%2B%5Ceta%5D&bg=ffffff&fg=666666&s=0&c=20201002)
Therefore upon substituting this, we prove the upper bound stated over the regret.

This subclaim that was used can be proved as follows

Generalization of multiplicative weights: Follow The Regularized Leader (FTRL)
When the set K of actions is convex (set of probability distributions on discrete actions is convex),
At time 
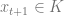

Now the new action in FTRL is based on the following optimization which is a regularized (with 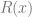
FTRL:

In this case, the regret bound is given by the following theorem.

![K={\text { set of all distributions on action space }[n]}, \text {and} \; R(x)=-\frac{1}{\eta} H(x)](https://s0.wp.com/latex.php?latex=K%3D%7B%5Ctext+%7B+set+of+all+distributions+on+action+space+%7D%5Bn%5D%7D%2C+%5Ctext+%7Band%7D+%5C%3B+R%28x%29%3D-%5Cfrac%7B1%7D%7B%5Ceta%7D+H%28x%29&bg=ffffff&fg=666666&s=0&c=20201002)
Train-Time Robustness
We now look at some robustness issues specific to the training phase in machine learning.

For example, during training, there could be adversarially poisoned examples in the training dataset that damage the trained model’s performance.
Setup: Suppose 



Assume 

Let us start with the task of estimating the mean under this setup.
Mean estimation: Estimate

Noiseless case: In the noiseless case, the best estimate for the mean under many measures is the empirical mean
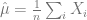
Standard concentration results show that for 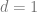

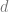
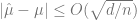
Adversarial case: If there is even a single malicious sample (that can be arbitrarily large or small) then it is well known that the empirical mean can give an arbitrarily bad approximation of the true population mean. For 

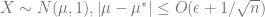
In a higher-dimension, this story instead goes as follows:
Setup: 
Median of coordinates (a starter solution): When 



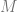
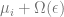

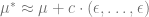


The obvious next question is: Can we do better? i.e, can we avoid paying this dimension-dependent 
Yes we can! We can use the ‘Tukey Median’!.
What is a Tukey median?
Informally via the picture below, if you have a Tukey median (red), no matter which direction you take from it and look at the half-space, it exactly partitions the data into about half the # of points.
Formal definition of Tukey median is given as follows (fixing some parameters):
A Tukey median* of 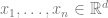



A Tukey median need not always exist for a given data. However, we will show that if the data is generated at random according to a nice distribution, and then at most
Existence of Tukey median
THM: If 

- Tukey median
exists and
- For every Tukey median
.
Together 1. and 2. mean that if we search over all vectors and output the first Tukey median that we find, then (a) this process will terminate and (b) its output will be a good approximation for the population mean. In particular, we do not have to pay the extra
** Proof of 1 (existence):**
The mean itself is the Tukey median in this case because, 
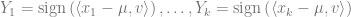
![\mathrm{Pr}\left[\sum Y_{i}>\epsilon k\right]<\exp \left(-\epsilon^{2} n\right) \ll \exp (-d)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D%5Cleft%5B%5Csum+Y_%7Bi%7D%3E%5Cepsilon+k%5Cright%5D%3C%5Cexp+%5Cleft%28-%5Cepsilon%5E%7B2%7D+n%5Cright%29+%5Cll+%5Cexp+%28-d%29&bg=ffffff&fg=666666&s=0&c=20201002)




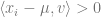

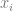

** Proof of 2:**
Let 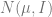

Let 

Note that 
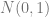
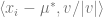

Hence, if 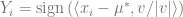
![\mathrm{Pr}\left[Y_{i}=-1\right]=\mathrm{Pr}[N(10\epsilon ,1) < 0] \leq 1 / 2-5 \epsilon](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D%5Cleft%5BY_%7Bi%7D%3D-1%5Cright%5D%3D%5Cmathrm%7BPr%7D%5BN%2810%5Cepsilon+%2C1%29+%3C+0%5D+%5Cleq+1+%2F+2-5+%5Cepsilon&bg=ffffff&fg=666666&s=0&c=20201002)
This implies that via a similar concentration argument as above, for every 

Exactly computing the Tukey median is NP-hard, but efficient algorithms for robust mean estimation of normals and other distributions exist as referred to in Jerry Li’s lecture notes. In particular, we can use the following approach using spectral signatures and filtering.
Spectral Signatures can efficiently certify that a given vector is in fact a robust mean estimator.
Let 
Let 


Claim:

In other words, if the spectral norm of the empirical covariance matrix is small, then the empirical mean is a good estimator for the population mean.
Note


The Proof for this claim is given below
Explanation: Here, we assume the 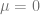
Filtering is an approach to turn the certificate into an algorithm to actually find the estimator. The idea is that the same claim holds for non-uniform reweighting of data points to estimate the empirical mean and covariance. Hence we can use a violation of the spectral norm condition (the existence of a large eigenvalue) to assign “blame” to some data points and down-weigh their contributions until we reach a probability distribution over points that on the one hand is spread on roughly 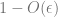

Explanation: We first compute the mean and covariance based on uniform weighting based, and the certificate is checked via the spectral norm of the covariance. If the quality isn’t good enough, then the blame is given to the largest eigenvector of the covariance that contributes to the most error. The weighting is now improved from the uniform initialization via the multiplicative weights styled update as given in step 3. Jerry Li and Jacob Steinhardt have wonderful lecture notes on these topics.
The algorithm above is computationally efficient while the bounds are not that tight.
SoS algorithms: Another approach is via sum of squares algorithms where the guarantees for statistical robustness are much tighter, but they are computationally not very efficient although they are polynomial time. A hybrid approach might as well give a balance of these based on the problem at hand to bridge this gap between computational efficiency vs. statistical efficiency.
A list of relevant references is given below.

Test-time robustness
We now cover robustness issues with distribution shift and adversarial data poisoning during the testing phase in machine learning.
Warm-up with pictures


As shown in Steinhardt, Koh, Liang, 2017 the images below illustrate how poisoning samples can drastically alter the performance of a classifier from good to bad.


Shafahi , Huang, Najibi, Suciu, Studer, Dumitras, Goldstein, 2018 showed how poisoning images look perfectly fine to the human perception, while they flip the model’s performance where a fish is considered to be a dog and vice versa as shown below.

Another problem with regards to test-time robustness is the issue of domain shift where the distribution of test data is different from the distribution of training data.


For example, images of dogs taken say in a forest vs. images of dogs taken on roads have huge distance in measures like the ones mentioned above, as many pixels (although not important pixels) across the images are very different and there could be a classifier that performs terribly across the test while it does good on train. But magically, there appears to be a linear relationship between the accuracy on 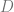

i.e say if it was trained on cifar 10 (
What are the potential reasons (intuitively)?
i) Overfitting on cifar test,
ii) Fewer human annotators per image introduces skew towards hardness of dataset,
iii) Running out of images by human annotators as they might end up choosing images that are easier to annotate.
If we achieve better accuracy on

A toy theoretical model
Here is a toy model can demonstrate this surprising linear relationship between accuracies under domain shift.
Let us do a thought experiment where things are linear. Let us assume there was a true vector cat direction in terms of the representation(feature) as shown in the cartoon below. Let there be some correlated idiosyncratic correlations. An example, idiosyncrasy is say due to cats tending to be photographed more in indoors than in outdoors.
Consider 

In some dataset 
![] \propto \exp (\beta\langle x, C A T+\alpha I\rangle)](https://s0.wp.com/latex.php?latex=%5D+%5Cpropto+%5Cexp+%28%5Cbeta%5Clangle+x%2C+C+A+T%2B%5Calpha+I%5Crangle%29&bg=ffffff&fg=666666&s=0&c=20201002)
where 
Dataset 
![] \propto \exp \left(\beta^{\prime}\left\langle x, C A T+\alpha^{\prime}I^{\prime}\right\rangle\right)](https://s0.wp.com/latex.php?latex=%5D+%5Cpropto+%5Cexp+%5Cleft%28%5Cbeta%5E%7B%5Cprime%7D%5Cleft%5Clangle+x%2C+C+A+T%2B%5Calpha%5E%7B%5Cprime%7DI%5E%7B%5Cprime%7D%5Cright%5Crangle%5Cright%29&bg=ffffff&fg=666666&s=0&c=20201002)
Intuitively 

So in this toy model, the best accuracy that can be reached for any linear classifier is given by the following, where the softmax of the RHS is the classification probability.
The first term of this accuracy is the universal and transferable part and the second term is the idiosyncratic part.
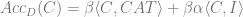
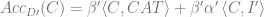
The following is an For the 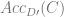




If the model is learnt by gradient descent then the gradient direction will always be proportional to 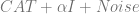
So, if 
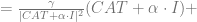
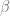
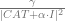
Therefore the accuracies will be as follows
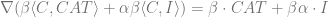
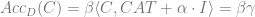

Therefore, we see this form of a linear relationship:

Note that:
iff
harder than
grows with idiosyncratic component of
Although this is a toy theoretical model, it explains a linear relationship. However, finding a model that explains this linear relationship in real-life will be an interesting project to think of.
Adversarial perturbations
We now move to the last (yet another active) topic of our blog: adversarial perturbations. As an introductory example (taken from this tutorial), the hog image 
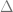


Should we be surprised with the efficacy of such adversarial perturbations? Originally-certainly yes, but not as much now in hindsight!
In this example it turns out that the magnitude of each element satisfies 

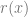


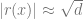
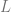
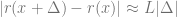

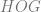

![h o g] \propto\langle H O G, r(x)\rangle](https://s0.wp.com/latex.php?latex=h+o+g%5D+%5Cpropto%5Clangle+H+O+G%2C+r%28x%29%5Crangle&bg=ffffff&fg=666666&s=0&c=20201002)
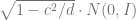


![]=\frac{\exp (-C)}{\exp (C)+\exp (-C)}](https://s0.wp.com/latex.php?latex=%5D%3D%5Cfrac%7B%5Cexp+%28-C%29%7D%7B%5Cexp+%28C%29%2B%5Cexp+%28-C%29%7D&bg=ffffff&fg=666666&s=0&c=20201002)
As we know that the observed probability of 
Upon normalizing 
Therefore the norm of the projection of 

So say if the 2048 vector had one larger element which accounts for the HOG direction, although it still accounts for a small proportion of its total norm. Therefore it wouldn’t need too much noise to flip one class to its wrong class label as shown in the cartoons below.


So if the Lipschitz constant is greater than around 2.5 or 3, then a fraction of 1/25 is enough to zero out the hog direction (as 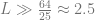
Robust loss
What are some strategies for training neural networks that are robust to perturbations?
- A set of transformation that do not change the true nature of the data such as for e.g:
where the set is

i.e, they only perturb the image or data sample by atmost
Now, given a loss function 

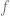


Robust training:
Given 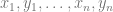

Now for the subgoal of finding 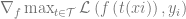



i.e for any function 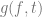

Note: The paper below extends to the case when 
On the empirical side, there seems to be a trade-off. If one wants to achieve adversarial robustness, it can be achieved by letting go of some model accuracy. See discussion here and the papers cited below.


Very interesting post! I especially like the back-of-the-envelope calculations about Lipschitzness and robustness.
I wanted to share a related post on this topic, which observes that standard image datasets are separated (images from different classes are far apart, e.g., in MNIST, CIFAR-10, etc), and argues that this implies that there should not necessarily be a trade-off between robustness and clean accuracy, at least for such datasets:
https://ucsdml.github.io/jekyll/update/2020/05/04/adversarial-robustness-through-local-lipschitzness.html
It is based on this paper from NeurIPS 2020:
https://arxiv.org/abs/2003.02460
I think it adds a different perspective compared to the papers mentioned at the end of this post =)