[Guest post by Annie Wei who scribed Peter Shor’s lecture in our physics and computation seminar. See here for all the posts of this seminar. –Boaz]
On October 19, we were lucky enough to have Professor Peter Shor give a guest lecture about quantum error correcting codes. In this blog post, I (Annie Wei) will present a summary of this guest lecture, which builds up quantum error correcting codes starting from classical coding theory. We will start by reviewing an example from classical error correction to motivate the similarities and differences when compared against the quantum case, before moving into quantum error correction and quantum channels. Note that we do assume a very basic familiarity with quantum mechanics, such as that which might be found here or here.
1. Motivation
We are interested in quantum error correction, ultimately, because any real-world computing device needs to be able to tolerate noise. Theoretical work on quantum algorithms has shown that quantum computers have the potential to offer speedups for a variety of problems, but in practice we’d also like to be able to eventually build and operate real quantum computers. We need to be able to protect against any decoherence that occurs when a quantum computer interacts with the environment, and we need to be able to protect against the accumulation of small gate errors since quantum gates need to be unitary operators.
In error correction the idea is to protect against noise by encoding information in a way that is resistant to noise, usually by adding some redundancy to the message. The redundancy then ensures that enough information remains, even after noise corruption, so that decoding will allow us to recover our original message. This is what is done in classical error correction schemes.
Unfortunately, it’s not obvious that quantum error correction is possible. One obstacle is that errors are continuous, since a continuum of operations can be applied to a qubit, so a priori it might seem like identifying and correcting an error would require infinite resources. In a later section we show how this problem, that of identifying quantum errors, can be overcome. Another obstacle is the fact that, as we’ve stated, classical error correction works by adding redundancy to a message. This might seem impossible to perform in a quantum setting due to the No Cloning Theorem, which states the following:
Theorem (No Cloning Theorem): Performing the mapping

is not a permissible quantum operation.
Proof: We will use unitarity, which says that a quantum operation specified by a unitary matrix 

(This ensures that the normalization of the state 

Now suppose that we can perform the operation

Then, letting
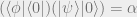
we note that by unitarity

But

and in general 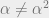
How do we get around this apparent contradiction? To do so, note that the no-cloning theorem only prohibits the copying of non-orthogonal quantum states. With orthogonal quantum states, either 

So how do we actually protect quantum information from noise? In the next section we first review classical error correction, as ideas from the classical setting re-appear in the quantum setting, and then we move into quantum error correction.
2. Review of Classical Error Correction
First we start by reviewing classical error correction. In classical error correction we generally have a message that we encode, send through a noisy channel, and then decode, in the following schematic process:

In an effective error correction scheme, the decoding process should allow us to identify any errors that occurred when our message passed through the noisy channel, which then tells us how to correct the errors. The formalism that allows us to do so is the following: we first define a 
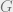





corresponding to the 7-bit Hamming codes, which encodes a 4-bit message as a 7-bit codeword. Note that this code has distance 3 since each of the rows in
We also define the parity check matrix 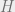
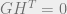
For example, to define

Then we may decode 
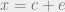
where 

Here 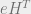
- Encode a
.
- Send the message through channel generating error
- Multiply by
to obtain the error syndrome
- Correct error
Having concluded our quick review of classical error correction, we now look at the theory of quantum error correction.
3. Quantum Error Correction
In this section we introduce quantum error correction by directly constructing the 9-qubit code and the 7-qubit code. Then we introduce the more general formalism of CSS codes, which encompasses both the 9-qubit and 7-qubit codes, before introducing the stabilizer formalism, which tells us how we might construct a CSS code.
3.1. Preliminaries
First we introduce some tools that we will need in this section.
3.1.1. Pauli Matrices
The Pauli matrices are a set of 2-by-2 matrices that form an orthogonal basis for the 2-by-2 Hermitian matrices, where a Hermitian matrix 



The Pauli matrices are given by


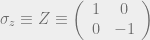
By direction computation we can show that they satisfy the relations




3.1.2. Von Neumann Measurements
We will also need the concept of a Von Neumann measurement. A Von Neumann measurement is given by a set of projection matrices 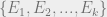

That is, the projectors partition a Hilbert space 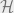

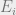

with probability 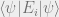
3.2. First Attempt at a Quantum Code
Now we make a first attempt at coming up with a quantum code, noting that our efforts and adjustments will ultimately culminate in the 9-qubit code. Starting with the simplest possible idea, we take inspiration from the classical repetition code, which maps
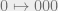

and decodes by taking the majority of the 3 bits. We consider the quantum analog of this, which maps


We will take our quantum errors to be the Pauli matrices 




We claim that this code can correct bit errors but not phase errors, which makes it equivalent to the original classical repetition code for error correction. To see this, note that applying an 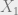

This can be detected by the von Neumann measurement which projects onto the subspaces




We could then apply 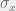

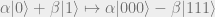
This is a valid encoding of the state 
What adjustments can we make so that we’re able to also correct

and satisfying
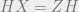
Note in particular that, because


or equivalently,

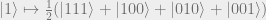
Now we can concatenate our bit flip code with our phase flip code to take care of both errors. This gives us the 9-qubit code, also known as the Shor code.
3.3. 9-Qubit Code
In the previous section, we went through the process of constructing the 9-qubit Shor code by considering how to correct both bit flip errors and phase flip errors. Explicitly, the 9-qubit Shor code is given by the following mapping:

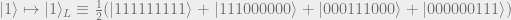
Here 

Note that by construction this code can correct 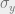






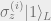
Now we have a 1-error quantum code. We claim that such a code can in fact correct any error operation, and that this is a property of all 1-error quantum codes:
Theorem: Given any possible unitary, measurement, or quantum operation on a one-error quantum code, the code can correct it.
Proof: 






Example: Phase Error Next we’ll do an example where we consider how we might correct an arbitrary phase error applied to the

Note that this can be rewritten in the

Now, applying this error to

After performing a projective measurement, we get state 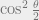


3.4. 7-Qubit Code
Now that we’ve constructed the 9-qubit code and shown that quantum error correction is possible, we might wonder whether it’s possible to do better. For example, we’d like a code that requires fewer qubits. We’ll construct a 7-qubit code that corrects 1 error, defining a mapping to
For this we will need to go back to the example we used to illustration classical error correction. Recall that in classical error correction, we have an encoding matrix 

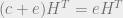
Now we will use the encoding matrix from our classical error correction example, and we will divide our codewords into two sets, 


and

Similar to how we approached the 9-qubit case, we will start by defining our code as follows:


Note that this corrects bit flip errors by construction. How can we ensure that we are also able to correct phase errors? For this we again turn to the Hadamard matrix, which allows us to toggle between bit and phase errors. We claim that

Proof: We will show that
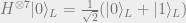
noting that the argument for

To see that this fact is true, note that
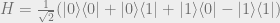
and that 



Note that for 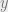


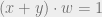

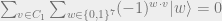


as the sum in 
Thus we have constructed a 7-qubit quantum code that corrects 1 error, and moreover we see that for both the 9-qubit and 7-qubit codes, both of which are 1-error quantum codes, the fact that they can correct 1-error comes directly from the fact that the original classical codes we used to construct them can themselves correct 1 error. This suggests that we should be able to come up with a more general procedure for constructing quantum codes from classical codes.
3.5. CSS Codes
CSS (Calderbank-Shor-Steane) codes generalize the process by which we constructed the 9-qubit and 7-qubit codes, and they give us a general framework for constructing quantum codes from classical codes. In a CSS code, we require groups 

Then we can define codewords to correspond to cosets of 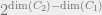


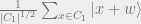
and under the Hadamard transformation applied to each qubit this state is in turn mapped to the state

That is to say, the Hadamard “dualizes” our original code, toggling bit errors to phase errors and vice versa. (This can be seen by direct calculation, as in the case of the 7-qubit code, where we used the fact that 

Note also that this code can correct a number of bit errors equal to the minimum weight of 
With the CSS construction we have thus reduced the problem of finding a quantum error correcting code to the problem of finding appropriate 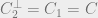

and are also well studied classically.
3.6. Gilbert-Varshamov Bound
In the previous section we introduced CSS codes and demonstrated that the problem of constructing a quantum code could be reduced to the problem of finding two groups

The next natural question is to ask whether such groups can in fact be found.
The Gilbert-Varshamov bound answers this question in the affirmative, ensuring that there do exist good CSS codes (the bound applies to both quantum and classical codes). It can be stated in the following way:
Theorem (Gilbert-Varshamov Bound): There exist CSS codes with rate 

where 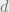
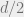
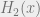

Proof: Note that we can always take a code, apply a random linear transformation to it, and get another code. Thus each vector is equally likely to appear in a random code. Given this fact, we can estimate the probability that a code of dimension 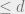
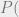
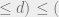


For this to be a valid probability we need to have

We can calculate rate by noting that for a CSS code, given by 
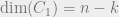


Combining this with the bound we obtained by considering probabilities, we get that
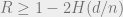
Thus there exist good CSS codes.
3.7. Stabilizer Codes
Having discussed and constructed some examples of CSS codes, we will now discuss the stabilizer formalism. Note that this formalism allows us to construct codes without having to work directly with the states representing
To see how working directly with states can get unwieldy, we can consider the 5-qubit code. We can define it the way we defined the 9-qubit and 7-qubit codes, by directly defining the basis vectors


with 
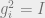

For example, for the 5-qubit code, the particular choice of generators we would need is given by
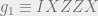

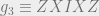

Now we consider states 


Note that the eigenvalues of 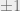
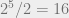
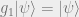


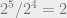
Next we will consider all elements in the Pauli group that commute with all elements in our stabilizer group 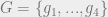

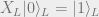



These will be our logical operators

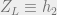
so that
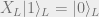
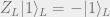
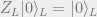
Note that this code has distance 3 and corrects 1 error because 3 is the minimum Hamming weight in the group 

Why is Hamming weight 2 not enough to correct one error? If we had, for example, 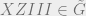

for 
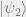
Note that, in general, when 


Note also that in the examples we’ve been dealing with so far, where we have a commuting subgroup of the Pauli group, our codes correspond to classical, additive, weakly self-dual codes over 






satisfying


We have now concluded our discussion of quantum error-correcting codes. In the next section we will shift gears and look at quantum channels and channel capacities.
4. Quantum Channels
In this final section we will look at quantum channels and channel capacities.
4.1. Definition and Examples
4.1.1. Definition
We know that we want to define a quantum channel to take a quantum state as input. What should the output be? As a first attempt we might imagine having the output be a probability distribution 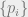

Recall that a density matrix takes the form

representing a probability distribution over pure states 
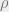
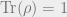

Now we may define a quantum channel as the map 

where
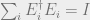
To see that the output is in fact a density matrix, note that the output expression is clearly Hermitian and can be shown to have unit trace using the cyclical property of traces. Note also that the decomposition into 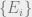
4.1.2. Example Quantum Channels
Next we give a few examples of quantum channels. The dephasing channel is given by the map

It maps

so it multiplies off-diagonal elements by a factor that is less than 1. Note that when 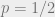
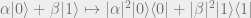
which means that it turns superpositions into classical mixtures (hence the name “dephasing”).
Another example is the amplitude damping channel, which models an excited state decaying to a ground state. It is given by

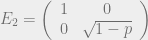
Here we let the vector 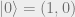
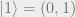





4.2 Quantum Channel Capacities
Now we consider the capacity of quantum channels, where the capacity quantifies how much information can make it through the channel. We consider classical channels, classical information sent over quantum channels, and quantum information sent over quantum channels. First we start off with the example of the quantum erasure channel to demonstrate that quantum channels behave differently from classical channels, and then we give the actual expressions for the channel capacities before revisiting the example of the quantum erasure channel.
4.2.1 Example: Quantum Erasure Channel
First we start with the example of the quantum erasure channel, which given a state 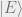
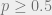
To see why this is the case, assume the contrary, that there do exist encoding and decoding protocols that send quantum information through quantum erasure channels with erasure rate 
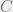
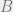

It turns out that the rate of quantum information sent over the erasure channel, as a function of

while the rate of classical information sent over the erasure channel, as a function of
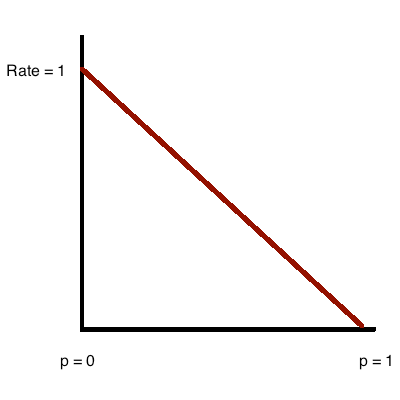
Next we will formally state the definition of channel capacity, and then we will return to the quantum erasure channel example and derive the curve that plots rate against
4.2.2. Definition of Channel Capacities
Channel capacity is defined as the maximum rate at which information can be communicated over many independent uses of a channel from sender to receiver. Here we list the expressions for channel capacity for classical channels, classical information over a quantum channel, and quantum information over a quantum channel.
Classical Channel Capacity For a classical channel this expression is just the maximum mutual information over all input-output pairs,

where 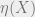
Classical Information Over a Quantum Channel The capacity for classical information sent over a quantum channel is given by

up to regularization, where 
Note that we would regularize this by using 
![\lim_{n\rightarrow\infty}\max_{\{p_i,\rho_i\}} [H(\eta(\rho)^{\otimes n})-\sum_i p_i H(\eta(\rho_i)^{\otimes n})]/n](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5Cmax_%7B%5C%7Bp_i%2C%5Crho_i%5C%7D%7D+%5BH%28%5Ceta%28%5Crho%29%5E%7B%5Cotimes+n%7D%29-%5Csum_i+p_i+H%28%5Ceta%28%5Crho_i%29%5E%7B%5Cotimes+n%7D%29%5D%2Fn&bg=eeeeee&fg=666666&s=0&c=20201002)
Quantum Information The capacity for quantum information is given by the expression

also up to regularization. Here 
![\lim_{n\rightarrow\infty}\max_\rho [H(\eta(\rho)^{\otimes n})-H((\eta\otimes I)(\Phi_\rho)^{\otimes n})]/n](https://s0.wp.com/latex.php?latex=%C2%A0%5Clim_%7Bn%5Crightarrow%5Cinfty%7D%5Cmax_%5Crho+%5BH%28%5Ceta%28%5Crho%29%5E%7B%5Cotimes+n%7D%29-H%28%28%5Ceta%5Cotimes+I%29%28%5CPhi_%5Crho%29%5E%7B%5Cotimes+n%7D%29%5D%2Fn&bg=eeeeee&fg=666666&s=0&c=20201002)
Now that we have the exact expression that allows us to calculate the quantum channel capacity, we will revisit our example of the quantum erasure channel and reproduce the plot of channel rate vs erasure probability.
4.2.3. Example Revisited: Quantum Erasure Channel
Recall that, up to regularization, the capacity of a quantum channel is given by
We will directly calculate this expression for the example of the quantum erasure channel. Let the input

so that the purification of
Recall that the erasure channel replaces our state with 
while in the basis 

We can directly calculate that


Then, subtracting the two entropies, we can calculate the rate to be
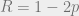
which corresponds exactly to the line we saw on the diagram that plotted rate as a function of
References
- Bennett, C. H., DiVencenzo, D. P., and Smolin, J. A. Capacities of quantum erasure channels. Phys. Rev. Lett., 78:3217-3220 (1997). quant-ph/9701015.
- Bennett, C. H., DiVencenzo, D. P., Smolin, J. A., and Wootters, W. K. Mixed state entanglement and quantum error correction. Phys. Rev. A, 54:3824 (1996). quant-ph/9604024.
- Calderbank, A. R. and Shor, P. W. Good quantum error-correcting codes exist. Phys. Rev. A, 54:1098 (1996). quant-ph/9512032.
- Devetak, I. The Private Classical Capacity and Quantum Capacity of a Quantum Channel. IEEE Trans. Inf. Theor., 51:44-45 (2005). quant-ph/0304127
- Devetak, I. and Winter, A. Classical data compression with quantum side information. Phys. Rev. A, 68(4):042301 (2003).
- Gottesman, D. Class of quantum error-correcting codes saturating the quantum Hamming bound. Phys. Rev. A, 54:1862 (1996).
- Laflamme, R., Miquel, C., Paz, J.-P., and Zurek, W. H. Perfect quantum error correction code. Phys. Rev. Lett., 77:198 (1996). quant-ph/9602019.
- Lloyd, S. Capacity of the noisy quantum channel. Phys. Rev. A., 55:3 (1997). quant-ph/9604015.
- Nielsen, M. A. and Chuang, I. L. Quantum Computation and Quantum Information., Cambridge University Press, New York (2011).
- Shor, P. W. Scheme for reducing decoherence in quantum computer memory. Phys. Rev. A., 52:2493 (1995).
- Shor, P. W. The quantum channel capacity and coherent information. MSRI Workshop on Quantum Computation (2002).
- Steane, A. M. Error correcting codes in quantum theory. Phys. Rev. Lett., 77:793 (1996).
- Steane, A. M. Multiple particle interference and quantum error correction. Proc. R. Soc. London A, 452:2551-76 (1996).
