Blog Post By: Patrick Guo, Vinh-Kha Le, Shyam Narayanan, and David Stoner
Methods in statistical physics are known to be extremely useful for understanding certain problems in theoretical computer science. Physical observations can motivate the underlying theoretical models, which in turn explain some of the physical phenomena.
This post is based on Professor Nike Sun’s guest lecture on the Ising Perceptron model and regular NAE-SAT for CS 229R: Physics and Computation. These are both examples of random constraint satisfaction problems, where we have  variables
variables  and certain relations, or constraints, between the
and certain relations, or constraints, between the 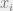 , and we wish to approximate the number of solutions or visualize the geometry of the solutions. For both problems, the problem instance can be random: for example, the linear constraints in the Ising perceptron model are random, and the clauses in the NAE-SAT instance are chosen at random. As in the previous blog posts, to understand the geometry of solutions, statistical physicists think of sampling random solutions from
, and we wish to approximate the number of solutions or visualize the geometry of the solutions. For both problems, the problem instance can be random: for example, the linear constraints in the Ising perceptron model are random, and the clauses in the NAE-SAT instance are chosen at random. As in the previous blog posts, to understand the geometry of solutions, statistical physicists think of sampling random solutions from 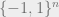 , which introduces a second type of randomness.
, which introduces a second type of randomness.
This post is meant to be expository. For interested readers, we point to useful references at the end for more rigorous treatments of these topics.
1. Perceptron Model
The Ising Perceptron under Gaussian disorder asks how many points in  survive
survive 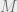 half-plane bisections (i.e. are satisfying assignments for constraints), where the planes’ coefficients are drawn from standard Gaussians. Like many problems in statistical physics, there is likely a critical capacity of constraints where having more constraints yields no survivors with high probability, and having fewer constraints yields survivors with high probability. This lecture gives an overview of a proof for one side of this physics prediction, i.e. the existence of a lower bound critical capacity, where having fewer constraints yields survivors with positive probability. Briefly, we use the Cavity method to approximate the distribution of the number of satisfying assignments, then attempt to use the second moment method on that distribution to get our lower bound. A direct application fails, however, due to the variance of the Gaussian constraints. The solution is to carefully choose exactly what to condition on without destroying the model. Specifically, we iteratively compute values related to the Gaussian disorder, after which we are able remove enough variance for the second moment method to work and thus establish the lower bound for the Ising Perceptron’s critical capacity. The result holds subject to an analytical condition which is detailed in the paper (Condition 1.2 in [6]) and which remains to be rigorously verified.
half-plane bisections (i.e. are satisfying assignments for constraints), where the planes’ coefficients are drawn from standard Gaussians. Like many problems in statistical physics, there is likely a critical capacity of constraints where having more constraints yields no survivors with high probability, and having fewer constraints yields survivors with high probability. This lecture gives an overview of a proof for one side of this physics prediction, i.e. the existence of a lower bound critical capacity, where having fewer constraints yields survivors with positive probability. Briefly, we use the Cavity method to approximate the distribution of the number of satisfying assignments, then attempt to use the second moment method on that distribution to get our lower bound. A direct application fails, however, due to the variance of the Gaussian constraints. The solution is to carefully choose exactly what to condition on without destroying the model. Specifically, we iteratively compute values related to the Gaussian disorder, after which we are able remove enough variance for the second moment method to work and thus establish the lower bound for the Ising Perceptron’s critical capacity. The result holds subject to an analytical condition which is detailed in the paper (Condition 1.2 in [6]) and which remains to be rigorously verified.
1.1. Problem
We pick a random direction in  , and delete all vertices in the hypercube which are in the half-space negatively correlated with that direction. We repeat this process of picking a random half space and deleting points times, and see if any points in the hypercube survive. Formally, we define the perceptron model as follows:
, and delete all vertices in the hypercube which are in the half-space negatively correlated with that direction. We repeat this process of picking a random half space and deleting points times, and see if any points in the hypercube survive. Formally, we define the perceptron model as follows:
Definition 1: Let 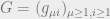 array of i.i.d. standard Gaussians. Let be the largest integer such that:
array of i.i.d. standard Gaussians. Let be the largest integer such that:
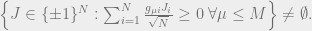
More compactly, is the largest integer such that

is nonempty, where the inequality is taken pointwise,  is an array of i.i.d. std. Gaussians, and
is an array of i.i.d. std. Gaussians, and  is treated as a vector in
is treated as a vector in  .
.
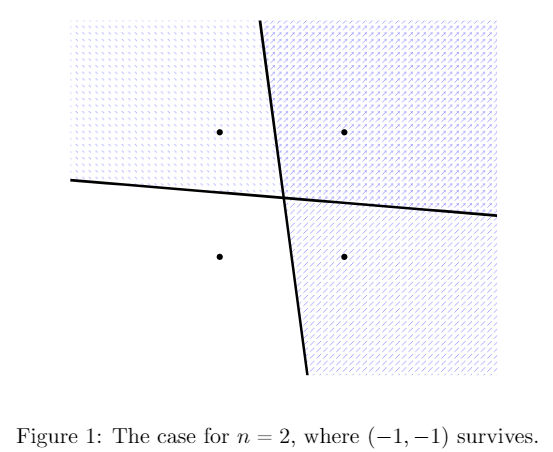
In the late 80’s, physicists conjectured that there is a critical capacity 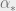 such that
such that  where is a function of
where is a function of 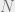 . The predicted critical capacity has been studied, for example in [7,9]. Our goal is to establish a lower bound on
. The predicted critical capacity has been studied, for example in [7,9]. Our goal is to establish a lower bound on  for the Ising Perceptron under Gaussian disorder. To do this, let
for the Ising Perceptron under Gaussian disorder. To do this, let  denote the random variable which measures how many choices of variables survive Gaussian constraints in
denote the random variable which measures how many choices of variables survive Gaussian constraints in 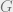 (this is the partition function). We want to show
(this is the partition function). We want to show 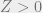 with high probability when there are
with high probability when there are  constraints. To this end, the second moment method seems promising:
constraints. To this end, the second moment method seems promising:
Second Moment Method: If  is a nonnegative random variable with finite variance, then
is a nonnegative random variable with finite variance, then
![P(Z > 0) \ge \frac{\left(\mathbb{E}[Z]\right)^2}{\mathbb{E}[Z^2]}](https://s0.wp.com/latex.php?latex=P%28Z+%3E+0%29+%5Cge+%5Cfrac%7B%5Cleft%28%5Cmathbb%7BE%7D%5BZ%5D%5Cright%29%5E2%7D%7B%5Cmathbb%7BE%7D%5BZ%5E2%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
However, this method actually fails due to various sources of variance in the perceptron model. We will briefly sketch the fix as given in [6].
Before we can start, however, what does the distribution of even look like? This is actually quite computationally intensive; we will use the cavity equations, a technique developed in [12,13], to approximate ‘s distribution.
1.2. Cavity Method
The goal of the cavity method is to see how the solution space changes as we remove a row or a column of the matrix with i.i.d. standard Gaussian entries, assuming that is fixed. Since our matrix is big and difficult to deal with, we try to see how the solution space changes as we add one row or one column at a time. Why is this valuable? We can think of the system of variables and constraints as an interaction between the rows (constraints) and columns (variables), so the number of solutions should behave proportionally to the product of the solutions attributed to each variable and each constraint. With this as motivation, define 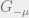 as the matrix obtained by removing row
as the matrix obtained by removing row  and
and  as the matrix obtained by removing column
as the matrix obtained by removing column  . We can approximate
. We can approximate

since we can think of the partition function as receiving a multiplicative factor from each addition of a row and each addition of a column. Thus, the cavity method seeks to compute 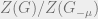 and
and 
1.2.1. Removing a constraint
Our goal in computing is to understand how the solution space  changes when we add in the constraint
changes when we add in the constraint  Recalling that
Recalling that  is our vector that is potentially in the solution space, if we define
is our vector that is potentially in the solution space, if we define

then adding the constraint is equivalent to forcing  We will try to understand the distribution of
We will try to understand the distribution of 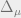 under the Gibbs measure
under the Gibbs measure  , which is the uniform measure on the solution space without the constraint . This way, we can determine the probability of
, which is the uniform measure on the solution space without the constraint . This way, we can determine the probability of 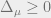 under the Gibbs measure, which will equal
under the Gibbs measure, which will equal  To do so, we will use the Replica Symmetric Cavity Assumption (which we will abbreviate as RS cavity assumption). The RS cavity assumption lets us assume that the
To do so, we will use the Replica Symmetric Cavity Assumption (which we will abbreviate as RS cavity assumption). The RS cavity assumption lets us assume that the 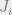 ‘s for
‘s for 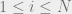 are independent under . As the ‘s are some discrete sample space that depend on our constraints, we do not actually have full independence, but the RS cavity assumption tells us there is very little dependence between the ‘s, so we pretend they are independent.
are independent under . As the ‘s are some discrete sample space that depend on our constraints, we do not actually have full independence, but the RS cavity assumption tells us there is very little dependence between the ‘s, so we pretend they are independent.
Note that should be approximately normally distributed, since it is the sum of many “independent” terms  by the RS Cavity assumption. Now, define
by the RS Cavity assumption. Now, define  as the expectation of under the Gibbs measure without the constraint , and
as the expectation of under the Gibbs measure without the constraint , and 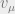 as the variance of under the Gibbs measure without the constraint . It will also turn out that the variance will concentrate around a constant
as the variance of under the Gibbs measure without the constraint . It will also turn out that the variance will concentrate around a constant  Thus,
Thus,

Here,  equals the probability that a random
equals the probability that a random 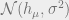 Gaussian distribution is positive, or equivalently, the probability that a standard Gaussian
Gaussian distribution is positive, or equivalently, the probability that a standard Gaussian  distribution is greater than
distribution is greater than 
1.2.2. Removing a spin
To calculate the cavity equation for removing one column, we think of removing a column as deleting one spin from . Define  as the vector resulting from removing spin from . We want to calculate Note that it is possible for
as the vector resulting from removing spin from . We want to calculate Note that it is possible for 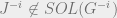 but
but  now, which complicates this calculation. It is possible to overcome this difficulty by passing to positive temperature, though this makes the calculations incredibly difficult. We do not worry about these issues here, and just briefly sketch how
now, which complicates this calculation. It is possible to overcome this difficulty by passing to positive temperature, though this makes the calculations incredibly difficult. We do not worry about these issues here, and just briefly sketch how 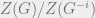 is computed.
is computed.
To compute , we will split the numerator into a sum of two terms based on the sign of 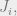 which will allow us to compute not only but also
which will allow us to compute not only but also 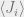 , which represents the magnetization at spin . A series of complicated calculations (see the lecture notes for the details) will give us
, which represents the magnetization at spin . A series of complicated calculations (see the lecture notes for the details) will give us

for some constant  , where
, where 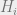 is a quantity that compares how much more correlated spin is to the constraints than all other spins. The
is a quantity that compares how much more correlated spin is to the constraints than all other spins. The 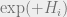 will come from the solutions for with
will come from the solutions for with  and the
and the 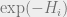 will come from the solutions with
will come from the solutions with 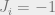 .
.
The above equations allow us to deduce that

1.3. The Randomness of G
In the previous section, we regarded as fixed. We now use the these results but allow for to be random again. Recall ‘s entries were i.i.d. Gaussians. We thus get that , as a linear combination of the  ‘s, is a Gaussian. We thus can write
‘s, is a Gaussian. We thus can write  Similarly, is a linear combination of the ‘s and must be Gaussian. We thus write
Similarly, is a linear combination of the ‘s and must be Gaussian. We thus write  .
.
With some calculations detailed in the lecture notes and [12], we get Gardner’s Formula:

where  is our capacity,
is our capacity,  . It turns out that
. It turns out that 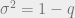 and
and 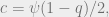 so the above equation only depends on two parameters,
so the above equation only depends on two parameters, 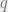 and
and  It will turn out that
It will turn out that 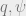 have relations dependent on each other based on our definitions of and , and these will give us a fixed point equation for
have relations dependent on each other based on our definitions of and , and these will give us a fixed point equation for  which has two solutions: one near
which has two solutions: one near  and one near
and one near  It is believed that the second point is correct, meaning that the critical capacity should equal
It is believed that the second point is correct, meaning that the critical capacity should equal 
1.4. Second Moment Method
Now that we have Gardner’s formula, solving for gives us an approximation for its distribution as

where  is Gardner’s formula, and the Gaussian noise
is Gardner’s formula, and the Gaussian noise  arises from the Gaussian distribution of the ‘s and ‘s. Again, we are interested in the probability that , but due to the approximate nature of the above equation, we cannot work with this distribution directly, and instead can try the second moment method. However, the exponentiated Gaussian makes
arises from the Gaussian distribution of the ‘s and ‘s. Again, we are interested in the probability that , but due to the approximate nature of the above equation, we cannot work with this distribution directly, and instead can try the second moment method. However, the exponentiated Gaussian makes ![\mathbb{E}[Z^2] \gg \mathbb{E}[Z]^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ%5E2%5D+%5Cgg+%5Cmathbb%7BE%7D%5BZ%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002) and the moment method just gives
and the moment method just gives 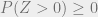 , whereas we need
, whereas we need  with high probability.
with high probability.
The fault here lies with Gaussian noise due to the ‘s and ‘s, so it is natural to consider what happens when we condition on them, getting rid of the noise. We denote

Then, we can compute that
![\frac{1}{N}\log \mathbb{E}[Z | \underline{H},\underline{h}] \to \mathcal{G}(\alpha)](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7BN%7D%5Clog+%5Cmathbb%7BE%7D%5BZ+%7C+%5Cunderline%7BH%7D%2C%5Cunderline%7Bh%7D%5D+%5Cto+%5Cmathcal%7BG%7D%28%5Calpha%29&bg=eeeeee&fg=666666&s=0&c=20201002)
in probability as  . (This is not an exact equality becacuse of the approximations made in the derivation of Gardner’s formula.) Moreover, we will have
. (This is not an exact equality becacuse of the approximations made in the derivation of Gardner’s formula.) Moreover, we will have ![\mathbb{E}[Z^2|\underline{H},\underline{h}] \approx \mathbb{E}[Z|\underline{H},\underline{h}]^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ%5E2%7C%5Cunderline%7BH%7D%2C%5Cunderline%7Bh%7D%5D+%5Capprox+%5Cmathbb%7BE%7D%5BZ%7C%5Cunderline%7BH%7D%2C%5Cunderline%7Bh%7D%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002) . The second moment method gives us the desired lower bound on . However, note that these
. The second moment method gives us the desired lower bound on . However, note that these  must satisfy the equations that defined them. In vector form, we have
must satisfy the equations that defined them. In vector form, we have


where  ,
, 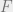 , and
, and  are constants and functions that appear in the rigorous definitions of
are constants and functions that appear in the rigorous definitions of 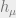 and .
and .
Here arises a problem, however. We cannot solve these equations easily, and furthermore when we condition on  and
and 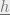 , the ‘s that satisfy the above are not necessarily representative of matrices of standard Gaussians. Hence, simply conditioning on knowing the values of
, the ‘s that satisfy the above are not necessarily representative of matrices of standard Gaussians. Hence, simply conditioning on knowing the values of  destroys the model and will not prove the lower bound on for Gaussian disorder.
destroys the model and will not prove the lower bound on for Gaussian disorder.
To solve this problem, we introduce iteration: first, initialize  and
and  (initialized to specific values detailed in [6]. Then, a simplified version of each time step’s update looks like
(initialized to specific values detailed in [6]. Then, a simplified version of each time step’s update looks like


It has been proven (see [2,4]) that  and
and 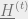 converge as
converge as  , and moreover the convergent values are distributed by what looks like a Gaussian at each time step. Since this sequence of converge (at a rate that is independent of ) and are representative of Gaussian , for a special kind of truncated partition function
, and moreover the convergent values are distributed by what looks like a Gaussian at each time step. Since this sequence of converge (at a rate that is independent of ) and are representative of Gaussian , for a special kind of truncated partition function  , conditioning on these iteration values allows the second moment method to work and gives
, conditioning on these iteration values allows the second moment method to work and gives
![\mathbb{E}[\tilde Z | \underline{h}^{(0)},\underline{H}^{(0)},\dots,\underline{h}^{(t)},\underline{H}^{(t)}]^2 \approx \mathbb{E}[\tilde Z^2 | \underline{h}^{(0)},\underline{H}^{(0)},\dots,\underline{h}^{(t)},\underline{H}^{(t)}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ctilde+Z+%7C+%5Cunderline%7Bh%7D%5E%7B%280%29%7D%2C%5Cunderline%7BH%7D%5E%7B%280%29%7D%2C%5Cdots%2C%5Cunderline%7Bh%7D%5E%7B%28t%29%7D%2C%5Cunderline%7BH%7D%5E%7B%28t%29%7D%5D%5E2+%5Capprox+%5Cmathbb%7BE%7D%5B%5Ctilde+Z%5E2+%7C+%5Cunderline%7Bh%7D%5E%7B%280%29%7D%2C%5Cunderline%7BH%7D%5E%7B%280%29%7D%2C%5Cdots%2C%5Cunderline%7Bh%7D%5E%7B%28t%29%7D%2C%5Cunderline%7BH%7D%5E%7B%28t%29%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
which is then enough to establish the lower bound for the non-truncated partition function (see [6] for details, see also [3] for closely related computations).
2.  -NAE-SAT
-NAE-SAT
This lecture also gave a brief overview of results in -NAESAT. In the -SAT problem, we ask whether a boolean formula in 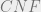 form, with each clause containing exactly literals, has a satisfying solution. For -NAESAT, we instead require that the satisfying solution is not uniform on any clause; equivalently, each clause must contain at least one true and at least one false value. Finally, we will restrict our set of possible boolean formulae to those for which every variable is contained in exactly
form, with each clause containing exactly literals, has a satisfying solution. For -NAESAT, we instead require that the satisfying solution is not uniform on any clause; equivalently, each clause must contain at least one true and at least one false value. Finally, we will restrict our set of possible boolean formulae to those for which every variable is contained in exactly 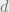 clauses; we call this model -regular -NAESAT. We briefly outline the critical capacities of clauses where the solution space changes. For more background on the -NAESAT probem and its variants, see [10].
clauses; we call this model -regular -NAESAT. We briefly outline the critical capacities of clauses where the solution space changes. For more background on the -NAESAT probem and its variants, see [10].
As with the perceptron model, we are concerned with the expected number of solutions of this system where the -regular formula is chosen uniformly at random. It turns out that for any fixed 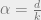 , the expected proportion of satisfiable solutions as
, the expected proportion of satisfiable solutions as  converges to some
converges to some 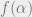 . More on this, the model in general and the critical constants mentioned below can be found in [15]. Via an application of Markov’s inequality and Jensen’s Inequality for the convex function
. More on this, the model in general and the critical constants mentioned below can be found in [15]. Via an application of Markov’s inequality and Jensen’s Inequality for the convex function 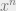 , may be bounded above by
, may be bounded above by 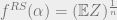 , shown graphically below.
, shown graphically below.

The diagram also shows the nature of the expected assortment of the solutions of a random  regular -NAESAT for ranges of values of . Namely, physics analysis suggests the following:
regular -NAESAT for ranges of values of . Namely, physics analysis suggests the following:
- For
 , w.h.p. the solutions are concentrated in a single large cluster.
, w.h.p. the solutions are concentrated in a single large cluster.
- For
 , w.h.p. the solutions are distributed among a large number of clusters.
, w.h.p. the solutions are distributed among a large number of clusters.
- For
 , the function breaks away from
, the function breaks away from 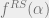 , and w.h.p. the solutions are concentrated in a small number of clusters.
, and w.h.p. the solutions are concentrated in a small number of clusters.
- For
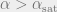 , w.h.p. there are no satisfiable solutions.
, w.h.p. there are no satisfiable solutions.
One final note for this model: the solutions to satisfiability problems tend to be more clumpy than in the perceptron model, so correlation decay methods won’t immediately work. See [15] for how this is handled.
References
- N. Bansal. Constructive algorithms for discrepancy minimization. In Proc. FOCS 2010, pages 3–10.
- M. Bayati and A. Montanari. The dynamics of message passing on dense graphs, with applications to compressed sensing. IEEE Trans. Inform. Theory, 57(2):764-785, 2011.
- Bolthausen, E., 2018. A Morita type proof of the replica-symmetric formula for SK. arXiv preprint arXiv:1809.07972.
- E. Bolthausen. An iterative construction of solutions of the TAP equations for the Sherrington-Kirkpatrick model. Commun. Math. Phys., 325(1):333-366, 2014.
- T. Cover. Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. IEEE Trans. Electron. Comput. 14(3):326-334.
- J. Ding and N. Sun. Capacity lower bound for the Ising perceptron. https://arxiv.org/pdf/1809.07742.pdf
- E. Gardner and B. Derrida. Optimal storage properties of neural network models. J. Phys. A., 21(1): 271–284, 1988.
- J. H. Kim and J. R. Roche. Covering cubes by random half cubes, with applications to binary neural networks. J. Comput. Syst. Sci., 56(2):223–252, 1998
- W. Krauth and M. Mézard. Storage capacity of memory networks with binary couplings. J. Phy. 50(20): 3057-3066, 1989.
- F. Krzakala et al. “Gibbs states and the set of solutions of random constraint satisfaction problems.” Proc. Natl. Acad. Sci. 104.25 (2007): 10318-10323.
- S. Lovett and R. Meka. Constructive discrepancy minimization by walking on the edges. SIAM J. Comput., 44(5):1573-1582.
- M. Mézard. The space of interactions in neural networks: Gardner’s computation with the cavity method. J. Phys. A., 22(12):2181, 1989
- M. Mézard and G. Parisi and M. Virasoro. SK Model: The Replica Solution without Replicas. Europhys. Lett., 1(2): 77-82, 1986.
- M. Shcherbina and B. Tirozzi. Rigorous solution of the Gardner problem. Commun. Math. Phys., 234(3):383-422, 2003.
- A. Sly and N. Sun and Y. Zhang. The Number of Solutions for Random Regular NAE-SAT. In Proc. FOCS 2016, pages 724-731.
- J. Spencer. Six standard deviations suffice. Trans. Amer. Math. Soc. 289 (1985), 679-706
- M. Talagrand. Intersecting random half cubes. Random Struct. Algor., 15(3-4):436–449, 1999.
