[Guest post by Thomas Orton who presented a lecture on this in our physics and computation seminar –Boaz]
Introduction
This blog post is a continuation of the CS229R lecture series. Last week, we saw how certain computational problems like 3SAT exhibit a thresholding behavior, similar to a phase transition in a physical system. In this post, we’ll continue to look at this phenomenon by exploring a heuristic method, belief propagation (and the cavity method), which has been used to make hardness conjectures, and also has thresholding properties. In particular, we’ll start by looking at belief propagation for approximate inference on sparse graphs as a purely computational problem. After doing this, we’ll switch perspectives and see belief propagation motivated in terms of Gibbs free energy minimization for physical systems. With these two perspectives in mind, we’ll then try to use belief propagation to do inference on the the stochastic block model. We’ll see some heuristic techniques for determining when BP succeeds and fails in inference, as well as some numerical simulation results of belief propagation for this problem. Lastly, we’ll talk about where this all fits into what is currently known about efficient algorithms and information theoretic barriers for the stochastic block model.
(1) Graphical Models and Belief Propagation
(1.0) Motivation
Suppose someone gives you a probabilistic model on 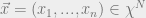 (think of
(think of 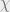 as a discrete set) which can be decomposed in a special way, say
as a discrete set) which can be decomposed in a special way, say
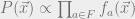
where each 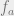 only depends on the variables
only depends on the variables 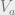 . Recall from last week that we can express constraint satisfaction problems in these kinds of models, where each is associated with a particular constraint. For example, given a 3SAT formula
. Recall from last week that we can express constraint satisfaction problems in these kinds of models, where each is associated with a particular constraint. For example, given a 3SAT formula 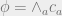 , we can let
, we can let 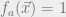 if
if 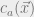 is satisfied, and 0 otherwise. Then each only depends on 3 variables, and
is satisfied, and 0 otherwise. Then each only depends on 3 variables, and 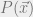 only has support on satisfying assignments of
only has support on satisfying assignments of 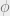 .
.
A central problem in computer science is trying to find satisfying assignments to constraint satisfaction problems, i.e. finding values 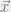 in the support of . Suppose that we knew that the value of
in the support of . Suppose that we knew that the value of 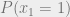 were
were  . Then we would know that there exists some satisfying assignment where
. Then we would know that there exists some satisfying assignment where 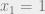 . Using this knowledge, we could recursively try to find ‘s in the support of
. Using this knowledge, we could recursively try to find ‘s in the support of  , and iteratively come up with a satisfying assignment to our constraint satisfaction problem. In fact, we could even sample uniformally from the distribution as follows: randomly assign
, and iteratively come up with a satisfying assignment to our constraint satisfaction problem. In fact, we could even sample uniformally from the distribution as follows: randomly assign  to
to  with probability , and assign it to
with probability , and assign it to 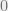 otherwise. Now iteratively sample from
otherwise. Now iteratively sample from 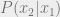 for the model where is fixed to the value we assigned to it, and repeat until we’ve assigned values to all of the
for the model where is fixed to the value we assigned to it, and repeat until we’ve assigned values to all of the  . A natural question is therefore the following: When can we try to efficiently compute the marginals
. A natural question is therefore the following: When can we try to efficiently compute the marginals

for each  ?
?
A well known efficient algorithm for this problem exists when the corresponding graphical model of (more in this in the next section) is a tree. Even though belief propagation is only guaranteed to work exactly for trees, we might hope that if our factor graph is “tree like”, then BP will still give a useful answer. We might even go further than this, and try to analyze exactly when BP fails for a random constraint satisfaction problem. For example, you can do this for k-SAT when  is large, and then learn something about the solution threshold for k-SAT. It therefore might be natural to try and study when BP succeeds and fails for different kinds of problems.
is large, and then learn something about the solution threshold for k-SAT. It therefore might be natural to try and study when BP succeeds and fails for different kinds of problems.
(1.1) Deriving BP
We will start by making two simplifying assumptions on our model .
First, we will assume that can be written in the form ![P(\vec{x})\propto \prod_{(i,j) \in E} f_{i,j}(x_i,x_j) \prod_{i \in [n]} f_i(x_i)](https://s0.wp.com/latex.php?latex=P%28%5Cvec%7Bx%7D%29%5Cpropto+%5Cprod_%7B%28i%2Cj%29+%5Cin+E%7D+f_%7Bi%2Cj%7D%28x_i%2Cx_j%29+%5Cprod_%7Bi+%5Cin+%5Bn%5D%7D+f_i%28x_i%29&bg=eeeeee&fg=666666&s=0&c=20201002) for some functions
for some functions 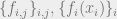 and some “edge set”
and some “edge set” 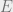 (where the edges are undirected). In other words, we will only consider pairwise constraints. We will see later that this naturally corresponds to a physical interpretation, where each of the “particles”
(where the edges are undirected). In other words, we will only consider pairwise constraints. We will see later that this naturally corresponds to a physical interpretation, where each of the “particles” 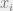 interact with each other via pairwise forces. Belief propagation actually still works without this assumption (which is why we can use it to analyze -SAT for
interact with each other via pairwise forces. Belief propagation actually still works without this assumption (which is why we can use it to analyze -SAT for 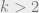 ), but the pairwise case is all we need for the stochastic block model.
), but the pairwise case is all we need for the stochastic block model.
For the second assumption, notice that there is a natural correspondence between and the graphical model  on
on  vertices, where
vertices, where 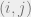 forms an edge in iff
forms an edge in iff 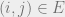 . In order words, edges in correspond to factors of the form
. In order words, edges in correspond to factors of the form  in , and vertices in correspond to variables in . Our second assumption is that the graphical model is a tree.
in , and vertices in correspond to variables in . Our second assumption is that the graphical model is a tree.
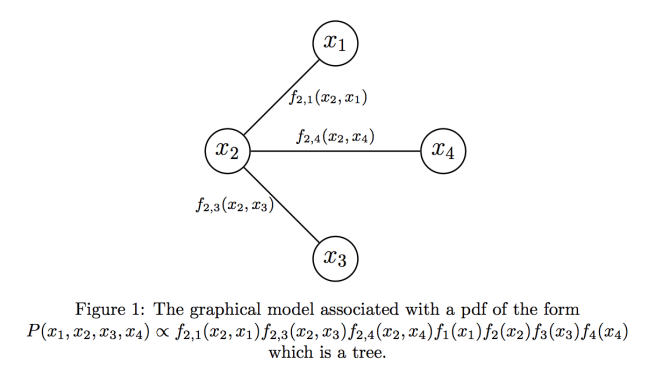
Now, suppose we’re given such a tree which represents our probabilistic model. How to we compute the marginals? Generally speaking, when computer scientists see trees, they begin to get very excited [reference]. “I know! Let’s use recursion!” shouts the student in CS124, their heart rate noticeably rising. Imagine that we arbitrarily rooted our tree at vertex . Perhaps, if we could somehow compute the marginals of the children of , we could somehow stitch them together to compute the marginal . In order words, we should think about computing the marginals of roots of subtrees in our graphical model. A quick check shows that the base case is easy: suppose we’re given a graphical model which is a tree consisting of a single node . This corresponds to some PDF  . So to compute
. So to compute  , all we have to do is compute the marginalizing constant
, all we have to do is compute the marginalizing constant 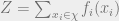 , and then we have
, and then we have  . With the base case out of the way, let’s try to solve the induction step: given a graphical model which is a tree rooted at , and where we’re given the marginals of the subtrees rooted at the children of , how do we compute the marginal of the tree rooted at ? Take a look at figure 2 to see what this looks like graphically. To formalize the induction step, we’ll define some notation that will also be useful to us later on. The main pieces of notation are
. With the base case out of the way, let’s try to solve the induction step: given a graphical model which is a tree rooted at , and where we’re given the marginals of the subtrees rooted at the children of , how do we compute the marginal of the tree rooted at ? Take a look at figure 2 to see what this looks like graphically. To formalize the induction step, we’ll define some notation that will also be useful to us later on. The main pieces of notation are  , which is the subtree rooted at with parent
, which is the subtree rooted at with parent 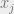 , and the “messages”
, and the “messages”  , which can be thought of as information which is passed from the child subtrees of to the vertex in order to compute the marginals correctly.
, which can be thought of as information which is passed from the child subtrees of to the vertex in order to compute the marginals correctly.
- We let
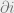 denote the neighbours of vertex in . In general, I’ll interchangeably switch between vertex and the variable represented by vertex .
denote the neighbours of vertex in . In general, I’ll interchangeably switch between vertex and the variable represented by vertex .
- We define to be the subtree of rooted at , where ‘s parent is
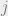 . We need to specify ‘s parent in order to give an orientation to our tree (so that we know in which direction we need to do recursion down the tree). Likewise, we let
. We need to specify ‘s parent in order to give an orientation to our tree (so that we know in which direction we need to do recursion down the tree). Likewise, we let  be the set of vertices/variables which occur in subtree .
be the set of vertices/variables which occur in subtree .
- We define the function
 , which is a function of the variables in , to be equal to the product of ‘s edges and vertices. Specifically,
, which is a function of the variables in , to be equal to the product of ‘s edges and vertices. Specifically, 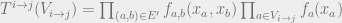 , where
, where 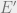 is the set of edges which occur in subtree . We can think of as being the pdf (up to normalizing constant) of the “model” of the subtree .
is the set of edges which occur in subtree . We can think of as being the pdf (up to normalizing constant) of the “model” of the subtree .
- Lastly, we define
 , where
, where 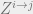 is a normalizing constant chosen such that
is a normalizing constant chosen such that  . In particular,
. In particular,  is a function defined for each possible value of
is a function defined for each possible value of 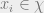 . We can interpret
. We can interpret 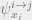 in two ways: firstly, it is the marginal of the root of the subtree . Secondly, we can think of it as a “message” from vertex to vertex . We’ll see why this is a valid interpretation shortly.
in two ways: firstly, it is the marginal of the root of the subtree . Secondly, we can think of it as a “message” from vertex to vertex . We’ll see why this is a valid interpretation shortly.

Phew! That was a lot of notation. Now that we have that out of the way, let’s see how we can express the marginal of the root of a tree as a function of the marginals of its subtrees. Suppose we’re considering the subtree , so that vertex has children 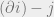 . Then we can compute the marginal
. Then we can compute the marginal 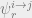 directly:
directly:

The non-obvious step in the above is that we’re able to switch around summations and products: we’re able to do this because each of the trees are functions on disjoint sets of variables. So we’re able to express as a function of the children values  . Looking at the update formula we have derived, we can now see why the are called “messages” to vertex : they send information about the child subtrees to their parent .
. Looking at the update formula we have derived, we can now see why the are called “messages” to vertex : they send information about the child subtrees to their parent .
The above discussion is a purely algebraic way of deriving belief propagation. A more intuitive way to get this result is as follows: imagine fixing the value of 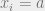 in the the subtree , and then drawing from each of the marginals of the children of conditioned on the value . We can consider the marginals of each of the children independently, because the children are independent of each other when conditioned on the value of . Converting words to equations, this means that if has children
in the the subtree , and then drawing from each of the marginals of the children of conditioned on the value . We can consider the marginals of each of the children independently, because the children are independent of each other when conditioned on the value of . Converting words to equations, this means that if has children 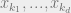 , then the marginal probability of
, then the marginal probability of 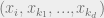 in the subtree is proportional to
in the subtree is proportional to 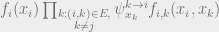 . We can then write
. We can then write
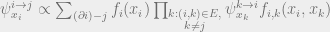
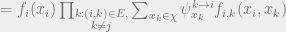
And we get back what we had before. We’ll call this last equation our “update” or “message passing” equation. The key assumption we used was that if we condition on , then the children of are independent. It’s useful to keep this assumption in mind when thinking about how BP behaves on more general graphs.
A similar calculation yields that we can calculate the marginal of our original probability distribution  as the marginal of the subtree with no parent, i.e.
as the marginal of the subtree with no parent, i.e.

Great! So now we have an algorithm for computing marginals: recursively compute for each in a dynamic programming fashion with the “message passing” equations we have just derived. Then, compute 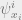 for each
for each ![i \in [n]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . If the diameter of our tree is
. If the diameter of our tree is 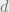 , then the recursion depth of our algorithm is at most .
, then the recursion depth of our algorithm is at most .
However, instead of computing every neatly with recursion, we might try something else: let’s instead randomly initialize each  with anything we want. Then, let’s update each in parallel with our update equations. We will keep doing this in successive steps until each has converged to a fixed value. By looking at belief propagation as a recursive algorithm, it’s easy to see that all of the ‘s will have their correct values after at most steps. This is because (after arbitrarily rooting our tree at any vertex) the leaves of our recursion will initialize to the correct value after 1 step. After two steps, the parents of the leaves will be updated correctly as functions of the leaves, and so they will have the correct values as well. Specifically:
with anything we want. Then, let’s update each in parallel with our update equations. We will keep doing this in successive steps until each has converged to a fixed value. By looking at belief propagation as a recursive algorithm, it’s easy to see that all of the ‘s will have their correct values after at most steps. This is because (after arbitrarily rooting our tree at any vertex) the leaves of our recursion will initialize to the correct value after 1 step. After two steps, the parents of the leaves will be updated correctly as functions of the leaves, and so they will have the correct values as well. Specifically:
Proposition: Suppose we initialize messages 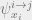 arbitrarily, and update them in parallel according to our update equations. If has diameter , then after steps each
arbitrarily, and update them in parallel according to our update equations. If has diameter , then after steps each 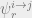 converges, and we recover the correct marginals.
converges, and we recover the correct marginals.
Why would anyone want to do things in this way? In particular, by computing everything in parallel in steps instead of recursively, we’re computing a lot of “garbage” updates which we never use. However, the advantage of doing things in this way is that this procedure is now well defined for general graphs. In particular, suppose violated assumption (2), so that the corresponding graph were not a tree. Then we could still try to compute the messages with parallel updates. We are also able to do this in a local “message passing” kind of way, which some people may find physically intuitive. Maybe if we’re lucky, the messages will converge after a reasonable amount of iterations. Maybe if we’re even luckier, they will converge to something which gives us information about the marginals  . In fact, we’ll see that just such a thing happens in the stochastic block model. More on that later. For now, let’s shift gears and look at belief propagation from a physics perspective.
. In fact, we’ll see that just such a thing happens in the stochastic block model. More on that later. For now, let’s shift gears and look at belief propagation from a physics perspective.
(2) Free Energy Minimization
(2.0) Potts model (Refresh of last week)
We’ve just seen a statistical/algorithmic view of how to compute marginals in a graphical model. It turns out that there’s also a physical way to think about this, which leads to a qualitatively similar algorithm. Recall from last week that another interpretation of a pairwise factor-able PDF is that of particles interacting with each other via pairwise forces. In particular, we can imagine each particle interacting with via a force of strength

and in addition, interacting with an external field
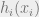
We imagine that each of our particles take values from a discrete set . When 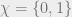 , we recover the Ising model, and in general we have a Potts model. The energy function of this system is then
, we recover the Ising model, and in general we have a Potts model. The energy function of this system is then
![E[\vec{x}]=-\sum_{(i,j)}J_{(i,j)}(x_i,x_j)-\sum_{i}h_{i}(x)](https://s0.wp.com/latex.php?latex=E%5B%5Cvec%7Bx%7D%5D%3D-%5Csum_%7B%28i%2Cj%29%7DJ_%7B%28i%2Cj%29%7D%28x_i%2Cx_j%29-%5Csum_%7Bi%7Dh_%7Bi%7D%28x%29&bg=eeeeee&fg=666666&s=0&c=20201002)
with probability distribution given by
![P(\vec{x})=\frac{1}{Z} e^{-E[\vec{x}]/T}](https://s0.wp.com/latex.php?latex=P%28%5Cvec%7Bx%7D%29%3D%5Cfrac%7B1%7D%7BZ%7D+e%5E%7B-E%5B%5Cvec%7Bx%7D%5D%2FT%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Now, for , computing the marginals corresponds to the equivalent physical problem of computing the “magnetizations”  .
.
How does this setup relate to the previous section, where we thought about constraint satisfaction problems and probability distributions? If we could set 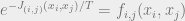 and
and  , we would recover exactly the probability distribution
, we would recover exactly the probability distribution 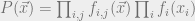 from the previous section. From a constraint satisfaction perspective, if we set
from the previous section. From a constraint satisfaction perspective, if we set 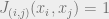 if constraint is satisfied and otherwise, then as
if constraint is satisfied and otherwise, then as  (our system becomes colder), ‘s probability mass becomes concentrated only on the satisfying assignments of the constraint satisfaction problem.
(our system becomes colder), ‘s probability mass becomes concentrated only on the satisfying assignments of the constraint satisfaction problem.
(2.1) Free energy minimization
We’re now going to try a different approach to computing the marginals: let’s define a distribution 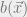 , which we will hope to be a good approximation to . If you like, you can think about the marginal
, which we will hope to be a good approximation to . If you like, you can think about the marginal  as being the “belief” about the state of variable . We can measure the “distance” between
as being the “belief” about the state of variable . We can measure the “distance” between 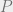 and
and 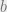 by the KL divergence
by the KL divergence
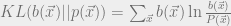

which equals 0 iff the two distributions are equal. Let’s define the Gibbs free energy as
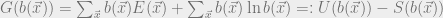
So the minimum value of 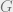 is
is 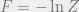 which is called the Helmholz free energy,
which is called the Helmholz free energy,  is the “average energy” and
is the “average energy” and  is the “entropy”.
is the “entropy”.
Now for the “free energy minimization part”. We want to choose to minimize , so that we can have that is a good approximation of . If this happens, then maybe we can hope to “read out” the marginals of directly. How do we do this in a way which makes it easy to “read out” the marginals? Here’s one idea: let’s try to write as a function of only the marginals 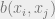 and of . If we could do this, then maybe we could try to minimize by only optimizing over values for “variables”
and of . If we could do this, then maybe we could try to minimize by only optimizing over values for “variables”  and
and  . However, we need to remember that and are actually meant to represent marginals for some real probability distribution . So at the very least, we should add the consistency constraints
. However, we need to remember that and are actually meant to represent marginals for some real probability distribution . So at the very least, we should add the consistency constraints  and
and  to our optimization problem. We can then think of and as “pseudo-marginals” which obey degree-2 Sherali-Adams constraints.
to our optimization problem. We can then think of and as “pseudo-marginals” which obey degree-2 Sherali-Adams constraints.
Recall that we’ve written as a sum of both the average energy and the entropy . It turns out that we can actually write as only a function of the pariwise marginals of :

which follows just because the sums marginalize out the variables which don’t form part of the pairwise interactions:
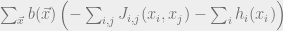
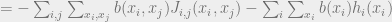
This is good news: since only depends on pairwise interactions, the average energy component of only depends on and . However, it is not so clear how to express the entropy as a function of one node and two node beliefs. However, maybe we can try to pretend that our model is really a “tree”. In this case, the following is true:
Claim: If our model is a tree, and and are the associated marginals of our probabilistic model , then we have
![b(\vec{x})=\frac{\prod_{(i,j) \in E}b(x_i,x_j)}{\prod_{i \in [n]} b(x_i)^{q_i-1}}](https://s0.wp.com/latex.php?latex=b%28%5Cvec%7Bx%7D%29%3D%5Cfrac%7B%5Cprod_%7B%28i%2Cj%29+%5Cin+E%7Db%28x_i%2Cx_j%29%7D%7B%5Cprod_%7Bi+%5Cin+%5Bn%5D%7D+b%28x_i%29%5E%7Bq_i-1%7D%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
where  is the degree of vertex in the tree.
is the degree of vertex in the tree.
It’s not too difficult to see why this is the case: imagine a tree rooted at , with children . We can think of sampling from this tree as first sampling from via its marginal , and then by recursively sampling the children conditioned on . Associate with  the subtrees of the children of , i.e.
the subtrees of the children of , i.e.  is equal to the probability of the occurrence
is equal to the probability of the occurrence  on the probabilistic model of the tree rooted at vertex . Then we have
on the probabilistic model of the tree rooted at vertex . Then we have
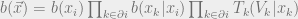
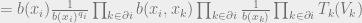
![=\frac{\prod_{(i,j) \in E}b(x_i,x_j)}{\prod_{i \in [N]}b(x_i)^{q_i-1}}](https://s0.wp.com/latex.php?latex=%3D%5Cfrac%7B%5Cprod_%7B%28i%2Cj%29+%5Cin+E%7Db%28x_i%2Cx_j%29%7D%7B%5Cprod_%7Bi+%5Cin+%5BN%5D%7Db%28x_i%29%5E%7Bq_i-1%7D%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
where the last line follows inductively, since each 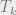 only sees
only sees  edges of
edges of 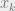 .
.
If we make the assumption that our model is a tree, then we can write the Bethe approximation entropy as
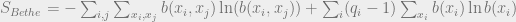
Where the  ‘s are the degrees of the variables in the graphical model defined by . We then define the Bethe free energy as
‘s are the degrees of the variables in the graphical model defined by . We then define the Bethe free energy as 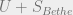 . The Bethe free energy is in general not an upper bound on the true free energy. Note that if we make the assignments
. The Bethe free energy is in general not an upper bound on the true free energy. Note that if we make the assignments 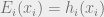 ,
, 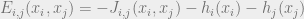 , then we can rewrite as
, then we can rewrite as

which is similar in form to the Bethe approximation entropy. In general, we have
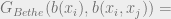
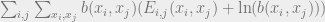

which is exactly the Gibbs free energy for a probabilistic model whose associated graph is a tree. Since BP gives the correct marginals on trees, we can say that the BP beliefs are the global minima of the Bethe free energy. However, the following is also true:
Proposition: A set of beliefs gives a BP fixed point in any graph (not necessarily a tree) iff they correspond to local stationary points of the Bethe free energy.
(For a proof, see e.g. page 20 of [4])
So trying to minimize the Bethe free energy is in some sense the same thing as doing belief propagation. Apparently, one typically finds that when belief propagation fails to converge on a graph, the optimization program which is trying to minimize  also runs into problems in similar parameter regions, and vice versa.
also runs into problems in similar parameter regions, and vice versa.
(3) The Block Model
(3.0) Definitions
Now that we’ve seen Belief Propagation from two different perspectives, let’s try to apply this technique of computing marginals to analyzing the behavior of the stochastic block model. This section will heavily follow the paper [2].
The stochastic block model is designed to capture a variety of interesting problems, depending on its settings of parameters. The question we’ll be looking at is the following: suppose we generate a random graph, where each vertex of the graph comes from one of 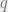 groups each with probability
groups each with probability 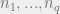 . We add an edge between vertices in groups
. We add an edge between vertices in groups 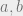 resp. with probability
resp. with probability  . For sparse graphs, we define
. For sparse graphs, we define 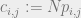 , where we think of
, where we think of 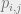 as
as 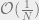 . The problem is the following: given such a random graph, can you label the vertices so that, up to permutation, the labels you choose have high correlation to the true hidden labels which were used to generate the graph? Here are some typical settings of parameters which represent different problems:
. The problem is the following: given such a random graph, can you label the vertices so that, up to permutation, the labels you choose have high correlation to the true hidden labels which were used to generate the graph? Here are some typical settings of parameters which represent different problems:
- Community detection, where we have groups. We set
 , and
, and  if
if 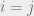 and
and 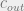 otherwise, with
otherwise, with  (assortative structure).
(assortative structure).
- Planted graph partitioning, where may not necessarily be .
- Planted graph colouring, where
 ,
,  and
and 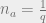 for all groups. We know how to efficiently find a planted coloring which is strongly correlated with the true coloring when the average degree
for all groups. We know how to efficiently find a planted coloring which is strongly correlated with the true coloring when the average degree 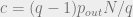 is greater than
is greater than  .
.
We’ll concern ourselves with the case where our graph is sparse, and we need to try and come up with an assignment for the vertices such that we have high correlation with the true labeling of vertices. How might we measure how well we solve this task? Ideally, a labeling which is identical to the true labeling (up to permutation) should get a score of 1. Conversely, a labeling which naively guesses that every vertex comes from the largest group ![\arg \max_{i \in [q]} n_{i}](https://s0.wp.com/latex.php?latex=%5Carg+%5Cmax_%7Bi+%5Cin+%5Bq%5D%7D+n_%7Bi%7D&bg=eeeeee&fg=666666&s=0&c=20201002) should get a score of 0. Here’s one metric which satisfies these properties: if we come up with a labeling
should get a score of 0. Here’s one metric which satisfies these properties: if we come up with a labeling 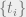 , and the true labeling is
, and the true labeling is  , then we’ll measure our performance by
, then we’ll measure our performance by
![Q(\{t_{i}\},\{q_{i}\}):=\max_{\pi \in S_q} \frac{\frac{1}{N}\sum_{i \in [N]} \delta_{t_i,\pi(q_i)}-max_{a \in [q]} n_a}{1-\max_{a \in [q]} n_a}](https://s0.wp.com/latex.php?latex=Q%28%5C%7Bt_%7Bi%7D%5C%7D%2C%5C%7Bq_%7Bi%7D%5C%7D%29%3A%3D%5Cmax_%7B%5Cpi+%5Cin+S_q%7D+%5Cfrac%7B%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi+%5Cin+%5BN%5D%7D+%5Cdelta_%7Bt_i%2C%5Cpi%28q_i%29%7D-max_%7Ba+%5Cin+%5Bq%5D%7D+n_a%7D%7B1-%5Cmax_%7Ba+%5Cin+%5Bq%5D%7D+n_a%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
where we maximize over all permutations  . When we choose a labeling which (up to permutation) agrees with the true labeling, then the numerator of
. When we choose a labeling which (up to permutation) agrees with the true labeling, then the numerator of  will equal the denominator, and
will equal the denominator, and  . Likewise, when we trivially guess that every vertex belongs to the largest group, then the numerator of is and
. Likewise, when we trivially guess that every vertex belongs to the largest group, then the numerator of is and 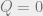 .
.
Given 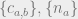 and a set of observed edges , we can write down the probability of a labeling as
and a set of observed edges , we can write down the probability of a labeling as
![P(\{q_i\}_{i})=\prod_{\substack{(i,j) \not \in E \\ i \not = j}}(1-p_{q_{i},q_{j}})\prod_{\substack{(i,j) \in E }}p_{q_{i},q_{j}} \prod_{i \in [q]}n_{q_i}](https://s0.wp.com/latex.php?latex=P%28%5C%7Bq_i%5C%7D_%7Bi%7D%29%3D%5Cprod_%7B%5Csubstack%7B%28i%2Cj%29+%5Cnot+%5Cin+E+%5C%5C+i+%5Cnot+%3D+j%7D%7D%281-p_%7Bq_%7Bi%7D%2Cq_%7Bj%7D%7D%29%5Cprod_%7B%5Csubstack%7B%28i%2Cj%29+%5Cin+E+%7D%7Dp_%7Bq_%7Bi%7D%2Cq_%7Bj%7D%7D+%5Cprod_%7Bi+%5Cin+%5Bq%5D%7Dn_%7Bq_i%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
How might we try to infer such that we have maximum correlation (up to permutation) with the true labeling? It turns out that the answer is to use the maximum likelihood estimator of the marginal distribution of each , up to a caveat. In particular, we should label with the ![r \in [q]](https://s0.wp.com/latex.php?latex=r+%5Cin+%5Bq%5D&bg=eeeeee&fg=666666&s=0&c=20201002) such that
such that  is maximized. The caveat comes in when
is maximized. The caveat comes in when 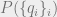 is invariant under permutations of the labelings , so that each marginal
is invariant under permutations of the labelings , so that each marginal 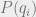 is actually the uniform distribution. For example, this happens in community detection, when all the group sizes are equal. In this case, the correct thing to do is to still use the marginals, but only after we have “broken the symmetry” of the problem by randomly fixing certain values of the vertices to have particular labels. There’s actually a way belief propagation does this implicitly: recall that we start belief propagation by randomly initializing the messages. This random initialization can be interpreted as “symmetry breaking” of the problem, in a way that we’ll see shortly.
is actually the uniform distribution. For example, this happens in community detection, when all the group sizes are equal. In this case, the correct thing to do is to still use the marginals, but only after we have “broken the symmetry” of the problem by randomly fixing certain values of the vertices to have particular labels. There’s actually a way belief propagation does this implicitly: recall that we start belief propagation by randomly initializing the messages. This random initialization can be interpreted as “symmetry breaking” of the problem, in a way that we’ll see shortly.
(3.1) Belief Propagation
We’ve just seen from the previous section that in order to maximize the correlation of the labeling we come up with, we should pick the labelings which maximize the marginals of . So we have some marginals that we want to compute. Let’s proceed by applying BP to this problem in the “sparse” regime where  (other algorithms, like approximate message passing, can be used for “dense” graph problems). Suppose we’re given a random graph with edge list . What does does graph associated with our probabilistic model look like? Well, in this case, every variable is actually connected to every other variable because includes a factor
(other algorithms, like approximate message passing, can be used for “dense” graph problems). Suppose we’re given a random graph with edge list . What does does graph associated with our probabilistic model look like? Well, in this case, every variable is actually connected to every other variable because includes a factor 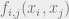 for every
for every ![(i,j) \in [n] \times [n]](https://s0.wp.com/latex.php?latex=%28i%2Cj%29+%5Cin+%5Bn%5D+%5Ctimes+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , so we actually have a complete graph. However, some of the connections between variables are much weaker than others. In full, our BP update equations are
, so we actually have a complete graph. However, some of the connections between variables are much weaker than others. In full, our BP update equations are
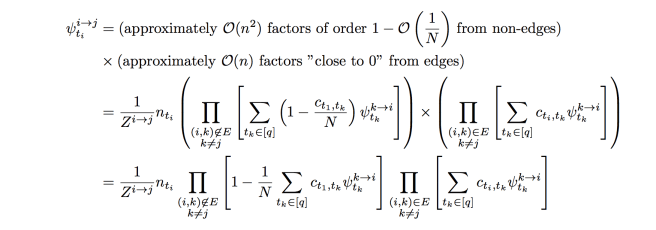
Likewise
![\psi^{i}_{t_{i}}=\frac{1}{Z^{i}} n_{t_{i}} \prod_{\substack{(i,k) \not \in E}}\left[ 1-\frac{1}{N}\sum_{t_k \in [q]}c_{t_1,t_k}\psi^{k \rightarrow i}_{t_k} \right]\prod_{\substack{(i,k) \in E}}\left[\sum_{t_k \in [q]}c_{t_i,t_k} \psi^{k \rightarrow i}_{t_k} \right]](https://s0.wp.com/latex.php?latex=%5Cpsi%5E%7Bi%7D_%7Bt_%7Bi%7D%7D%3D%5Cfrac%7B1%7D%7BZ%5E%7Bi%7D%7D+n_%7Bt_%7Bi%7D%7D+%5Cprod_%7B%5Csubstack%7B%28i%2Ck%29+%5Cnot+%5Cin+E%7D%7D%5Cleft%5B+1-%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bt_k+%5Cin+%5Bq%5D%7Dc_%7Bt_1%2Ct_k%7D%5Cpsi%5E%7Bk+%5Crightarrow+i%7D_%7Bt_k%7D+%5Cright%5D%5Cprod_%7B%5Csubstack%7B%28i%2Ck%29+%5Cin+E%7D%7D%5Cleft%5B%5Csum_%7Bt_k+%5Cin+%5Bq%5D%7Dc_%7Bt_i%2Ct_k%7D+%5Cpsi%5E%7Bk+%5Crightarrow+i%7D_%7Bt_k%7D+%5Cright%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
what we want to do is approximate these equations so that we only have to pass messages along the edges , instead of the complete graph. This will make our analysis simpler, and also allow the belief propagation algorithm to run more efficiently. The first observation is the following: Suppose we have two nodes ![j,j' \in [N]](https://s0.wp.com/latex.php?latex=j%2Cj%27+%5Cin+%5BN%5D&bg=eeeeee&fg=666666&s=0&c=20201002) such that
such that 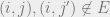 . Then we see that
. Then we see that  , since the only difference between these two variables are two factors of order
, since the only difference between these two variables are two factors of order 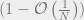 which appear in the first product of the BP equations. Thus, we send essentially the same messages to non-neighbours of in our random graph. In general though, we have:
which appear in the first product of the BP equations. Thus, we send essentially the same messages to non-neighbours of in our random graph. In general though, we have:
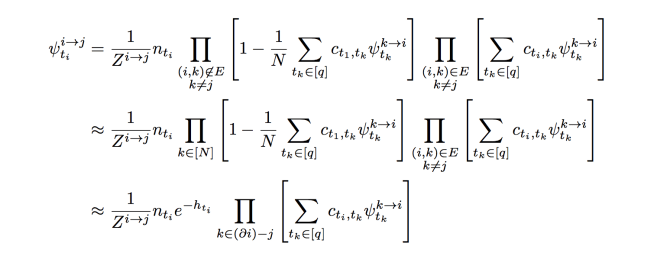
The first approximation comes from dropping non-edge constraints on the first product, and is reasonable because we expect the number of neighbours of to be constant. We’ve also defined a variable
![h_{t_i}:=\frac{1}{N}\sum_{k \in [N]}\sum_{t_k \in [q]}c_{t_i,t_k} \psi^{k \rightarrow i}_{t_k}](https://s0.wp.com/latex.php?latex=h_%7Bt_i%7D%3A%3D%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bk+%5Cin+%5BN%5D%7D%5Csum_%7Bt_k+%5Cin+%5Bq%5D%7Dc_%7Bt_i%2Ct_k%7D+%5Cpsi%5E%7Bk+%5Crightarrow+i%7D_%7Bt_k%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
and we’ve used the approximation  for small
for small  . We think of the term
. We think of the term  as defining an “auxiliary external field”. We’ll use this approximate BP equation to find solutions for our problem. This has the advantage that the computation time is
as defining an “auxiliary external field”. We’ll use this approximate BP equation to find solutions for our problem. This has the advantage that the computation time is  instead of
instead of 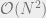 , so we can deal with large sparse graphs computationally. It also allows us to see how a large dense graphical model with only sparse strong connections still behaves like a sparse tree-like graphical model from the perspective of Belief Propagation. In particular, we might have reason to hope that the BP equations will actually converge and give us good approximations to the marginals.
, so we can deal with large sparse graphs computationally. It also allows us to see how a large dense graphical model with only sparse strong connections still behaves like a sparse tree-like graphical model from the perspective of Belief Propagation. In particular, we might have reason to hope that the BP equations will actually converge and give us good approximations to the marginals.
From now on, we’ll only consider factored block models, which in some sense represent a “hard” setting of parameters. These are models which satisfy the condition that each group has the same average degree  . In particular, we require
. In particular, we require

An important observation for this setting of parameters is that
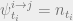
is always a fixed point of our BP equations, which is known as a factored fixed point (this can be seen by inspection by plugging the fixed point conditions into the belief propagation equations we derived). When BP ever reaches such a fixed point, we get that and the algorithm fails. However, we might hope that if we randomly initialize 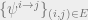 , then BP might converge to some non-trivial fixed point which gives us some information about the original labeling of the vertices.
, then BP might converge to some non-trivial fixed point which gives us some information about the original labeling of the vertices.
(3.2) Numerical Results
Now that we have our BP equations, we can run numerical simulations to try and get a feel of when BP works. Let’s consider the problem of community detection. In particular, we’ll set our parameters with all group sizes  being equal, and with
being equal, and with  for
for 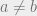 and vary the ratio
and vary the ratio 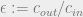 , and see when BP finds solutions which are correlated “better than guessing” to the original labeling used to generate the graph. When we do this, we get images which look like this:
, and see when BP finds solutions which are correlated “better than guessing” to the original labeling used to generate the graph. When we do this, we get images which look like this:
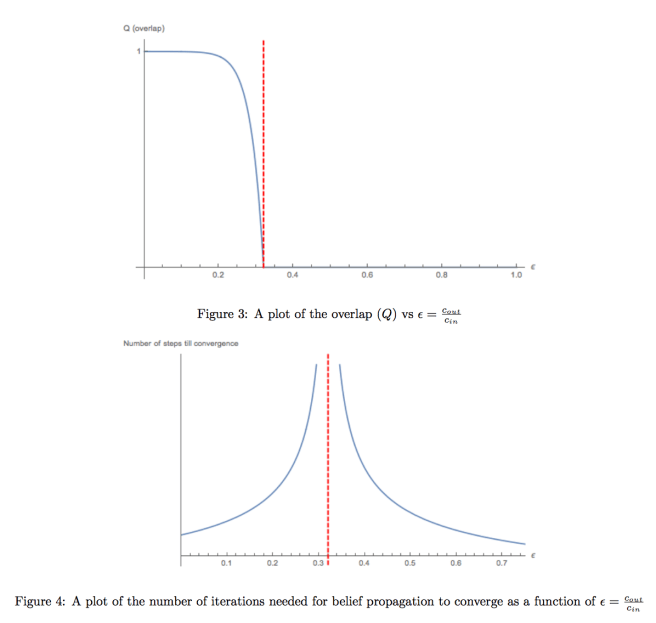
It should be mentioned that the point at which the dashed red line occurs depends on the parameters of the stochastic block model. We get a few interesting observations from numerical experiments:
- The point at which BP fails () happens at a certain value of
 independent of
independent of 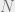 . In particular, when gets too large, BP converges to the trivial factored fixed point. We’ll see in the next section that this is a “stable” fixed point for certain settings of parameters.
. In particular, when gets too large, BP converges to the trivial factored fixed point. We’ll see in the next section that this is a “stable” fixed point for certain settings of parameters.
- Using the approximate BP equations gives the same performance as using the exact BP equations. This numerically justifies the approximations we made.
- If we try to estimate the marginals with other tools from our statistical inference toolbox, we find (perhaps surprisingly) that Markov Chain Monte Carlo methods give the same performance as Belief Propagation, even though they take significantly longer to run and have strong asymptotic guarantees on their correctness (if you run MCMC long enough, you will eventually get the correct marginals, but this may take exponential time). This naturally suggests the conjecture that belief propagation is optimal for this task.
- As we get closer to the region where BP fails and converges to the trivial fixed point, the number of iterations required for BP to converge increases significantly, and diverges at the critical point
 where BP fails and converges to the factored fixed point. The same kind of behavior is seen when using Gibbs sampling.
where BP fails and converges to the factored fixed point. The same kind of behavior is seen when using Gibbs sampling.
(3.3) Heuristic Stability Calculations
How might we analytically try to determine when BP fails for certain settings of and 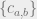 ? One way we might heuristically try to do this, is to calculate the stability of the factored fixed point. If the fixed point is stable, this suggests that BP will converge to a factored point. If however it is unstable, then we might hope that BP converges to something informative. In particular, suppose we run BP, and we converge to a factored fixed point, so we have that for all our messages
? One way we might heuristically try to do this, is to calculate the stability of the factored fixed point. If the fixed point is stable, this suggests that BP will converge to a factored point. If however it is unstable, then we might hope that BP converges to something informative. In particular, suppose we run BP, and we converge to a factored fixed point, so we have that for all our messages  . Suppose we now add a small amount of noise to some of the
. Suppose we now add a small amount of noise to some of the  ‘s (maybe think of this as injecting a small amount of additional information about the true marginals). We (heuristically) claim that if we now continue to run more steps of BP, either the messages will converge back to the fixed point , or they will diverge to something else, and whether or not this happens depends on the eigenvalue of some matrix of partial derivatives.
‘s (maybe think of this as injecting a small amount of additional information about the true marginals). We (heuristically) claim that if we now continue to run more steps of BP, either the messages will converge back to the fixed point , or they will diverge to something else, and whether or not this happens depends on the eigenvalue of some matrix of partial derivatives.
Following this idea, here’s a heuristic way of calculating the stability of the factored fixed point. Let’s pretend that our BP equations occur on a tree, which is a reasonable approximation in the sparse graph case. Let our tree be rooted at node  and have depth . Let’s try to approximately calculate the influence on of perturbing a leaf
and have depth . Let’s try to approximately calculate the influence on of perturbing a leaf 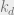 from its factored fixed point. In particular, let the path from the leaf to the root be
from its factored fixed point. In particular, let the path from the leaf to the root be 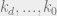 . We’re going to apply a perturbation
. We’re going to apply a perturbation 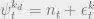 for each
for each ![t \in [q]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5Bq%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . In vector notation, this looks like
. In vector notation, this looks like  , where
, where 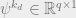 is a column vector. The next thing we’ll do is define the matrix of partial derivatives
is a column vector. The next thing we’ll do is define the matrix of partial derivatives
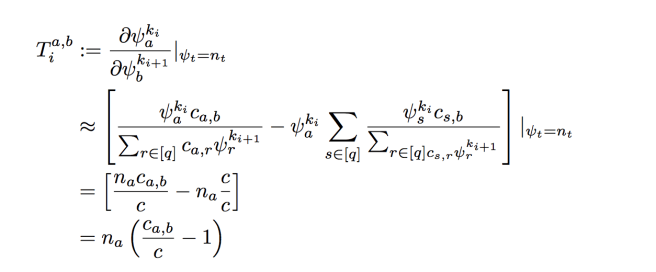
Up to first order (and ignoring normalizing constants), the perturbation effect on 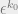 is then (by chain rule)
is then (by chain rule) ![\epsilon^{k_0} = \left[\prod_{i=0}^{d-1} T_{i} \right]\epsilon^{k_d}](https://s0.wp.com/latex.php?latex=%5Cepsilon%5E%7Bk_0%7D+%3D+%5Cleft%5B%5Cprod_%7Bi%3D0%7D%5E%7Bd-1%7D+T_%7Bi%7D+%5Cright%5D%5Cepsilon%5E%7Bk_d%7D&bg=eeeeee&fg=666666&s=0&c=20201002) . Since
. Since 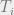 does not depend on , we can write this as
does not depend on , we can write this as 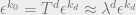 , where
, where  is the largest eigenvalue of . Now, on a random tree, we have approximately
is the largest eigenvalue of . Now, on a random tree, we have approximately 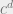 leaves. If we assume that the perturbation effect from each leaf is independent, and that
leaves. If we assume that the perturbation effect from each leaf is independent, and that 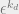 has 0 mean, then the net mean perturbation from all the leaves will be 0. The variance will be
has 0 mean, then the net mean perturbation from all the leaves will be 0. The variance will be

if we assume that the cross terms vanish in expectation.
(Aside: You might want to ask: why are we assuming that  has mean zero, and that (say) the noise at each of the leaves are independent, so that the cross terms vanish? If we want to maximize the variance, then maybe choosing the ‘s to be correlated or have non-zero mean would give us a better bound. The problem is that we’re neglecting the effects of normalizing constants in this analysis: if we perturbed all the
has mean zero, and that (say) the noise at each of the leaves are independent, so that the cross terms vanish? If we want to maximize the variance, then maybe choosing the ‘s to be correlated or have non-zero mean would give us a better bound. The problem is that we’re neglecting the effects of normalizing constants in this analysis: if we perturbed all the 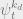 in the same direction (e.g. non-zero mean), our normalization conditions would cancel out our perturbations.)
in the same direction (e.g. non-zero mean), our normalization conditions would cancel out our perturbations.)
We Therefore end up with the stability condition 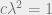 . When
. When 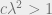 , a small perturbation will be magnified as we move up the tree, leading to the messages moving away from the factored fixed point after successive iterations of BP (the fixed point is unstable). If
, a small perturbation will be magnified as we move up the tree, leading to the messages moving away from the factored fixed point after successive iterations of BP (the fixed point is unstable). If  , the effect of a small perturbation will vanish as we move up the tree, we expect the factored fixed point to be stable. If we restrict our attention to graphs of the form
, the effect of a small perturbation will vanish as we move up the tree, we expect the factored fixed point to be stable. If we restrict our attention to graphs of the form 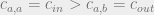 for , and have all our groups with size , then is known to have eigenvalues
for , and have all our groups with size , then is known to have eigenvalues  with eigenvector
with eigenvector  , and
, and 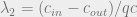 . The stability threshold then becomes
. The stability threshold then becomes  . This condition is known as the Almeida-Thouless local stability condition for spin glasses, and the Kesten-Stigum bound on reconstruction on trees. It is also observed empirically that BP and MCMC succeed above this threshold, and converge to factored fixed points below this threshold. The eigenvalues of are related to the belief propagation equations and the backtracking matrix. For more details, see [3]
. This condition is known as the Almeida-Thouless local stability condition for spin glasses, and the Kesten-Stigum bound on reconstruction on trees. It is also observed empirically that BP and MCMC succeed above this threshold, and converge to factored fixed points below this threshold. The eigenvalues of are related to the belief propagation equations and the backtracking matrix. For more details, see [3]
(3.4) Information Theoretic Results, and what we know algorithmically
We’ve just seen a threshold for when BP is able to solve the community detection problem. Specifically, when  , BP doesn’t do better than chance. It’s natural to ask whether this is because BP is not powerful enough, or whether there really isn’t enough information in the random graph to recover the true labeling. For example, if is very close to
, BP doesn’t do better than chance. It’s natural to ask whether this is because BP is not powerful enough, or whether there really isn’t enough information in the random graph to recover the true labeling. For example, if is very close to 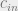 , it might be impossible to distinguish between group boundaries up to random fluctuations in the edges.
, it might be impossible to distinguish between group boundaries up to random fluctuations in the edges.
It turns out that for 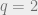 , there is not enough information below the threshold to find a labeling which is correlated with the true labeling [3]. However, it can be shown information-theoretically [1] that the threshold at which one can find a correlated labeling is
, there is not enough information below the threshold to find a labeling which is correlated with the true labeling [3]. However, it can be shown information-theoretically [1] that the threshold at which one can find a correlated labeling is 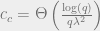 . In particular, when
. In particular, when 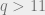 , there exists exponential time algorithms which recover a correlated labeling below the Kesten-Stigum threshold. This is interesting, because it suggests an information-computational gap: we observe empirically that heuristic belief propagation seems to perform as well as any other inference algorithm at finding a correlated labeling for the stochastic block model. However, belief propagation fails at a “computational” threshold below the information theoretic threshold for this problem. We’ll talk more about these kinds of information-computation gaps in the coming weeks.
, there exists exponential time algorithms which recover a correlated labeling below the Kesten-Stigum threshold. This is interesting, because it suggests an information-computational gap: we observe empirically that heuristic belief propagation seems to perform as well as any other inference algorithm at finding a correlated labeling for the stochastic block model. However, belief propagation fails at a “computational” threshold below the information theoretic threshold for this problem. We’ll talk more about these kinds of information-computation gaps in the coming weeks.
References
[1] Jess Banks, Cristopher Moore, Joe Neeman, Praneeth Netrapalli,
Information-theoretic thresholds for community detection in sparse
networks. AJMLR: Workshop and Conference Proceedings vol 49:1–34, 2016.
Link
[2] Aurelien Decelle, Florent Krzakala, Cristopher Moore, Lenka Zdeborová,
Asymptotic analysis of the stochastic block model for modular networks and its
algorithmic applications. 2013.
Link
[3] Cristopher Moore, The Computer Science and Physics
of Community Detection: Landscapes, Phase Transitions, and Hardness. 2017.
Link
[4] Jonathan Yedidia, William Freeman, Yair Weiss, Understanding Belief Propogation and its Generalizations
Link
[5] Afonso Banderia, Amelia Perry, Alexander Wein, Notes on computational-to-statistical gaps: predictions using statistical physics. 2018.
Link
[6] Stephan Mertens, Marc Mézard, Riccardo Zecchina, Threshold Values of Random K-SAT from the Cavity Method. 2005.
Link
[7] Andrea Montanari, Federico Ricci-Tersenghi, Guilhem Semerjian, Clusters of solutions and replica symmetry breaking in random k-satisfiability. 2008.
Link
A big thanks to Tselil for all the proof reading and recommendations, and to both Boaz and Tselil for their really detailed post-presentation feedback.

Thanks for the very interesting exposition.
Some comments:
1. There’s no link to the previous lecture though you refer to it.
2. The first displayed equation is unclear to me. You say you want to “decompose” the probabilistic model. What does a decomposition mean? I understood that it means that the probability P(x) of getting x, is defined to be as the right hand side of the equation. But then the example seems to say that for every satisfying assignment x, it’s probability is 1. Which doesn’t make sense. Where did I get it wrong?
Thanks for reading it!
1. You’re right. The previous lecture is Tselil’s blog post; I’ll add a link to it shortly. Thanks for pointing that out.
2. Almost: the probability is defined to be proportional (not equal to) the right hand side. So in the example, the probability distribution is uniform over every satisfying assignment. It’s probably worth mentioning that this scenario is very typical of inference tasks: we can easily write down the pdf of a model, but only up to normalizing constant, and the normalizing constant often gives us useful information about the entire distribution. Moreover, calculating the normalizing constant can be computationally hard (in the example for 3SAT, it would be #P complete), and is often a computational problem of interest in many fields (e.g. sampling methods in statistics, models of physical systems, bayesian inference, and computational problems).