Statistical physics has deep connections to many computational problems, including statistical inference, counting and sampling, and optimization. Perhaps especially compelling are the field’s insights and intuitions regarding “average-case complexity” and information-computation gaps. These are topics for which the traditional theoretical CS approaches seem ill-suited, while on the other hand statistical physics has supplied a rich (albeit not always mathematically rigorous) theory.
Statistical physics is the first topic in the seminar course I am co-teaching with Boaz this fall, and one of our primary goals is to explore this theory. This blog post is a re-working of a lecture I gave in class this past Friday. It is meant to serve as an introduction to statistical physics, and is composed of two parts: in the first part, I introduce the basic concepts from statistical physics in a hands-on manner, by demonstrating a phase transition for the Ising model on the complete graph. In the second part, I introduce random k-SAT and the satisfiability conjecture, and give some moment-method based proofs of bounds on the satisfiability threshold.
Update on September 16, 3:48pm: the first version of this post contained an incorrect plot of the energy density of the Ising model on the complete graph, which I have amended below.
I. From particle interactions to macroscopic behaviors
In statistical physics, the goal is to understand how materials behave on a macroscopic scale based on a simple model of particle-particle interactions.
For example, consider a block of iron. In a block of iron, we have many iron particles, and each has a net  -polarization or “spin” which is induced by the quantum spins of its unpaired electrons. On the microscopic scale, nearby iron atoms “want” to have the same spin. From what I was able to gather on Wikipedia, this is because the unpaired electrons in the distinct iron atoms repel each other, and if two nearby iron atoms have the same spins, then this allows them to be in a physical configuration where the atoms are further apart in space, which results in a lower energy state (because of the repulsion between electrons).
-polarization or “spin” which is induced by the quantum spins of its unpaired electrons. On the microscopic scale, nearby iron atoms “want” to have the same spin. From what I was able to gather on Wikipedia, this is because the unpaired electrons in the distinct iron atoms repel each other, and if two nearby iron atoms have the same spins, then this allows them to be in a physical configuration where the atoms are further apart in space, which results in a lower energy state (because of the repulsion between electrons).
When most of the particles in a block of iron have correlated spins, then on a macroscopic scale we observe this correlation as the phenomenon of magnetism (or ferromagnetism if we want to be technically correct).
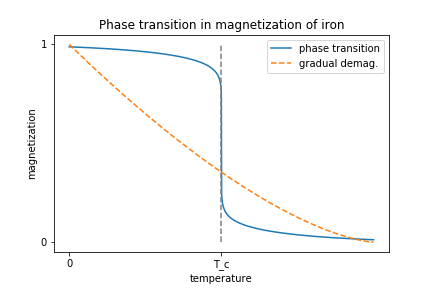
In the 1890’s, Pierre Curie showed that if you heat up a block of iron (introducing energy into the system), it eventually loses its magnetization. In fact, magnetization exhibits a phase transition: there is a critical temperature, 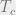 , below which a block of iron will act as a magnet, and above which it will suddenly lose its magnetism. This is called the “Curie temperature”. This phase transition is in contrast to the alternative, in which the iron would gradually lose its magnetization as it is heated.
, below which a block of iron will act as a magnet, and above which it will suddenly lose its magnetism. This is called the “Curie temperature”. This phase transition is in contrast to the alternative, in which the iron would gradually lose its magnetization as it is heated.
The Ising Model
We’ll now set up a simple model of the microscopic particle-particle interactions, and see how the global phenomenon of the magnetization phase transition emerges. This is called the Ising model, and it is one of the more canonical models in statistical physics.
Suppse that we have  iron atoms, and that their interactions are described by the (for simplicity unweighted) graph
iron atoms, and that their interactions are described by the (for simplicity unweighted) graph 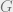 with adjacency matrix
with adjacency matrix  . For example, we may think of the atoms as being arranged in a 3D cubic lattice, and then would be the 3D cubic lattice graph. We give each atom a label in
. For example, we may think of the atoms as being arranged in a 3D cubic lattice, and then would be the 3D cubic lattice graph. We give each atom a label in ![[n] = \{1,\ldots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3D+%5C%7B1%2C%5Cldots%2Cn%5C%7D&bg=eeeeee&fg=666666&s=0&c=20201002) , and we associate with each atom
, and we associate with each atom ![i \in [n]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002) a spin
a spin  .
.
For each choice of spins or state  we associate the total energy
we associate the total energy
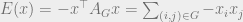 .
.
If two interacting particles have the same spin, then they are in a “lower energy” configuration, and then they contribute 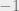 to the total energy. If two neighboring particles have opposite spins, then they are in a “higher energy” configuration, and they contribute
to the total energy. If two neighboring particles have opposite spins, then they are in a “higher energy” configuration, and they contribute 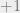 to the total energy.
to the total energy.
We also introduce a temperature parameter  . At each , we want to describe what a “typical” configuration for our block of iron looks like. When
. At each , we want to describe what a “typical” configuration for our block of iron looks like. When 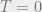 , there is no kinetic energy in the system, so we expect the system to be in the lowest-energy state, i.e. all atoms have the same spin. As the temperature increases, the kinetic energy also increases, and we will begin to see more anomalies.
, there is no kinetic energy in the system, so we expect the system to be in the lowest-energy state, i.e. all atoms have the same spin. As the temperature increases, the kinetic energy also increases, and we will begin to see more anomalies.
In statistical physics, the “description” takes the form of a probability distribution over states  . To this end we define the Boltzmann distribution, with density function
. To this end we define the Boltzmann distribution, with density function 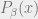 :
:
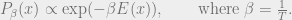
As  ,
,  , becomes supported entirely on the that minimize
, becomes supported entirely on the that minimize  ; we call these the ground states (for connected these are exactly
; we call these the ground states (for connected these are exactly  ). On the other hand as
). On the other hand as  , all are weighted equally according to
, all are weighted equally according to 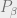 .
.
Above we have defined the Boltzmann distribution to be proportional to  . To spell it out,
. To spell it out,

The normalizing quantity  is referred to as the partition function, and is interesting in its own right. For example, from we can compute the free energy
is referred to as the partition function, and is interesting in its own right. For example, from we can compute the free energy 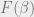 of the system, as well as the internal energy
of the system, as well as the internal energy  and the entropy
and the entropy  :
:

Using some straightforward calculus, we can then see that is the Shannon entropy,

that is the average energy in the system,

and that the free energy is the difference of the internal energy and the product of the temperature  and the entropy,
and the entropy,

just like the classical thermodynamic definitons!
Why these functions?
The free energy, internal energy, and entropy encode information about the typical behavior of the system at temperature 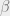 . We can get some intuition by considering the extremes,
. We can get some intuition by considering the extremes,  and
and 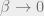 .
.
In cold systems with , if we let  be the energy of the ground state,
be the energy of the ground state,  be the number of ground state configurations, and
be the number of ground state configurations, and 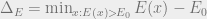 be the energy gap, then
be the energy gap, then

where the  notation hides factors that do not depend on . From this it isn’t hard to work out that
notation hides factors that do not depend on . From this it isn’t hard to work out that

We can see that the behavior of the system is dominated by the few ground states. As , all of the free energy can be attributed to the internal energy term.
On the other hand, as ,

and the behavior of the system is chaotic, with the free energy dominated by the entropy term.
Phase transition at the critical temperature.
We say that the system undergoes a phase transition at  if the energy density
if the energy density  is not analytic at
is not analytic at  . Often, this comes from a shift in the relative contributions of the internal energy and entropy terms to . Phase transitions are often associated as well with a qualitative change in system behavior.
. Often, this comes from a shift in the relative contributions of the internal energy and entropy terms to . Phase transitions are often associated as well with a qualitative change in system behavior.
For example, we’ll now show that for the Ising model with  the complete graph with self loops, the system has a phase transition at
the complete graph with self loops, the system has a phase transition at  (the self-loops don’t make much physical sense, but are convenient to work with). Furthermore, we’ll show that this phase transition corresponds to a qualitative change in the system, i.e. the loss of magnetism.
(the self-loops don’t make much physical sense, but are convenient to work with). Furthermore, we’ll show that this phase transition corresponds to a qualitative change in the system, i.e. the loss of magnetism.
Define the magnetization of the system with spins to be 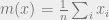 . If
. If  , then we say the system is magnetized.
, then we say the system is magnetized.
In the complete graph, normalized so that the total interaction of each particle is  , there is a direct relationship between the energy and the magnetization:
, there is a direct relationship between the energy and the magnetization:
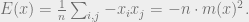
Computing the energy density.
The magnetization takes values  for
for 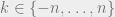 . So, letting
. So, letting 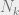 be the number of states with magnetization
be the number of states with magnetization  , we have that
, we have that

Now, is just the number of strings with Hamming weight  , so
, so  . By Stirling’s approximation
. By Stirling’s approximation  , where
, where 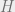 is the entropy function, so up to lower-order terms
is the entropy function, so up to lower-order terms
![Z(\beta) \approx \sum_{\substack{k\in [\pm n]\\ k+n \equiv_2 0}} \exp\left( \beta n \left(\frac{k}{n}\right)^2 + H\left(\frac{1 + \frac{k}{n}}{2}\right) n\right).](https://s0.wp.com/latex.php?latex=Z%28%5Cbeta%29+%5Capprox+%5Csum_%7B%5Csubstack%7Bk%5Cin+%5B%5Cpm+n%5D%5C%5C+k%2Bn+%5Cequiv_2+0%7D%7D+%5Cexp%5Cleft%28+%5Cbeta+n+%5Cleft%28%5Cfrac%7Bk%7D%7Bn%7D%5Cright%29%5E2+%2B+H%5Cleft%28%5Cfrac%7B1+%2B+%5Cfrac%7Bk%7D%7Bn%7D%7D%7B2%7D%5Cright%29+n%5Cright%29.&bg=eeeeee&fg=666666&s=0&c=20201002)
Now we apply the following simplification: for 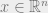 ,
,  , and then
, and then  . Treating our summands as the entries of the vector , from this we have,
. Treating our summands as the entries of the vector , from this we have,
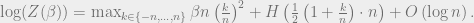
By definition of the energy density,

and since  independently of , we also have
independently of , we also have
![f(\beta) = -\left(\max_{\delta \in [-1,1]} \delta^2 + \frac{1}{\beta}H\left(\frac{1+\delta}{2}\right)\right),](https://s0.wp.com/latex.php?latex=f%28%5Cbeta%29+%3D+-%5Cleft%28%5Cmax_%7B%5Cdelta+%5Cin+%5B-1%2C1%5D%7D+%5Cdelta%5E2+%2B+%5Cfrac%7B1%7D%7B%5Cbeta%7DH%5Cleft%28%5Cfrac%7B1%2B%5Cdelta%7D%7B2%7D%5Cright%29%5Cright%29%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
because the error from rounding ![\delta \in [-1,1]](https://s0.wp.com/latex.php?latex=%5Cdelta+%5Cin+%5B-1%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002) to the nearest factor of
to the nearest factor of 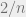 is
is  .
.
We can see that the first term in the expression for  corresponds to the square of the magnetization (and therefore the energy); the more magnetized the system is, the larger the contribution from the first term. The second term corresponds to the entropy, or the number of configurations in the support; the larger the support, the larger the contribution of the second term. As
corresponds to the square of the magnetization (and therefore the energy); the more magnetized the system is, the larger the contribution from the first term. The second term corresponds to the entropy, or the number of configurations in the support; the larger the support, the larger the contribution of the second term. As  , the contribution of the entropy term overwhelms the contribution of the energy term; this is consistent with our physical intuition.
, the contribution of the entropy term overwhelms the contribution of the energy term; this is consistent with our physical intuition.
A phase transition.
We’ll now demonstrate that there is indeed a phase transition in . To do so, we solve for this maximum. Taking the derivative with respect to  , we have that
, we have that

so the derivative is 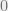 whenever
whenever  . From this, we can check the maxima. When
. From this, we can check the maxima. When 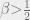 , there are two maxima equidistant from the origin, corresponding to negatively or positively-magnetized states. When
, there are two maxima equidistant from the origin, corresponding to negatively or positively-magnetized states. When 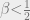 , the maximizer is , corresponding to an unmagnetized state.
, the maximizer is , corresponding to an unmagnetized state.

Given the maximizers, we now have the energy density. When we plot the energy density, the phase transition at  is subtle (an earlier version of this post contained a mistaken plot):
is subtle (an earlier version of this post contained a mistaken plot):
But when we plot the derivative, we can see that it is not smooth at :
And with some calculus it is possible to show that the second derivative is indeed not continuous at .
Qualitatively, it is convincing that this phase transition in the energy density is related to a transition in the magnetization (because the maximizing corresponds to the typical magnetization). One can make this formal by performing a similar calculation to show that the internal energy undergoes a phase transition, which in this case is proportional to the expected squared magnetization, ![\mathbb{E}_{P_\beta}[-n \cdot m(x)^2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BP_%5Cbeta%7D%5B-n+%5Ccdot+m%28x%29%5E2%5D&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
Beyond the complete graph
The Ising model on the complete graph  (also called the Curie-Weiss model) is perhaps not a very convincing model for a physical block of iron; we expect that locality should govern the strength of the interactions. But because the energy and the magnetization are related so simply, it is easy to solve.
(also called the Curie-Weiss model) is perhaps not a very convincing model for a physical block of iron; we expect that locality should govern the strength of the interactions. But because the energy and the magnetization are related so simply, it is easy to solve.
Solutions are also known for the 1D and 2D grids; solving it on higher-dimensional lattices, as well as in many other interesting settings, remains open. Interestingly, the conformal bootstrap method that Boaz mentioned has been used towards solving the Ising model on higher-dimensional grids.
II. Constraint Satisfaction Problems
For those familiar with constraint satisfaction problems (CSPs), it may have already been clear that the Ising model is a CSP. The spins are Boolean variables, and the energy function is an objective function corresponding to the EQUALITY CSP on (a pretty boring CSP, when taken without negations). The Boltzmann distribution gives a probability distribution over assignments to the variables , and the temperature determines the objective value of a typical  .
.
We can similarly define the energy, Boltzmann distribution, and free energy/entropy for any CSP (and even to continuous domains such as ). Especially popular with statistical physicists are:
- CSPs (such as the Ising model) over grids and other lattices.
- Gaussian spin glasses: CSPs over or where the energy function is proportional to
 , where
, where  is an order-
is an order- symmetric tensor with entries sampled i.i.d. from
symmetric tensor with entries sampled i.i.d. from 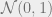 . The Ising model on a graph with random Gaussian weights is an example for
. The Ising model on a graph with random Gaussian weights is an example for  .
.
- Random instances of -SAT: Of the
 possible clauses (with negations) on variables,
possible clauses (with negations) on variables,  clauses
clauses  are sampled uniformly at random, and the energy function is the number of satisfied clauses,
are sampled uniformly at random, and the energy function is the number of satisfied clauses, ![E(x) = |\{ i \in [m] : C_i(x) = 1\}|](https://s0.wp.com/latex.php?latex=E%28x%29+%3D+%7C%5C%7B+i+%5Cin+%5Bm%5D+%3A+C_i%28x%29+%3D+1%5C%7D%7C&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
- Random instances of other Boolean and larger-alphabet CSPs.
In some cases, these CSPs are reasonable models for physical systems; in
other cases, they are primarily of theoretical interest.
Algorithmic questions
As theoretical computer scientists, we are used to seeing CSPs in the contex of optimization. In statistical physics, the goal is to understand the qualitative behavior of the system as described by the Boltzmann distribution. They ask algorithmic questions such as:
- Can we estimate the free energy ? The partition function ? And, relatedly,
- Can we sample from ?
But these tasks are not so different from optimization. For example, if our system is an instance of 3SAT, when , the Boltzmann distribution is the uniform distribution over maximally satisfying assignments, and so estimating 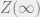 is equivalent to deciding the SAT formula, and sampling from
is equivalent to deciding the SAT formula, and sampling from  is equivalent to solving the SAT formula. As increases, sampling from corresponds to sampling an approximate solution.
is equivalent to solving the SAT formula. As increases, sampling from corresponds to sampling an approximate solution.
Clearly in the worst case, these tasks are NP-Hard (and even #P-hard). But even for random instances these algorithmic questions are interesting.
Phase transitions in satisfiability
In random -SAT, the system is controlled not only by the temperature but also by the clause density  . For the remainder of the post, we will focus on the zero-temperature regime
. For the remainder of the post, we will focus on the zero-temperature regime  , and we will see that -SAT exhibits phase transitions in
, and we will see that -SAT exhibits phase transitions in  as well.
as well.
The most natural “physical” trait to track in a -SAT formula is whether or not it is satisfiable. When 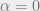 , -SAT instances are clearly satisfiable, because they have no constraints. Similarly when
, -SAT instances are clearly satisfiable, because they have no constraints. Similarly when  , random -SAT instances cannot be satisfiable, because for any set of variables they will contain all
, random -SAT instances cannot be satisfiable, because for any set of variables they will contain all  possible -SAT constraints (clearly unsatisfiable). It is natural to ask: is there a satisfiability phase transition in ?
possible -SAT constraints (clearly unsatisfiable). It is natural to ask: is there a satisfiability phase transition in ?
For , one can show that the answer is yes. For  , numerical evidence strongly points to this being the case; further, the following theorem of Friedgut gives a partial answer:
, numerical evidence strongly points to this being the case; further, the following theorem of Friedgut gives a partial answer:
Theorem:
For there exists a function  such that for any
such that for any 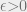 , if
, if 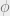 is a random -SAT formula on variables with
is a random -SAT formula on variables with 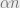 clauses, then
clauses, then
![\lim_{n \to \infty} \Pr[\phi \text{ is satisfiable}] = \begin{cases} 1 & \text{ if } \alpha \textless (1-\epsilon) \alpha_c(n)\\ 0 & \text{ if } \alpha \textgreater (1+\epsilon) \alpha_c(n) \end{cases}.](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5CPr%5B%5Cphi+%5Ctext%7B+is+satisfiable%7D%5D+%3D+%5Cbegin%7Bcases%7D+1+%26+%5Ctext%7B+if+%7D+%5Calpha+%5Ctextless+%281-%5Cepsilon%29+%5Calpha_c%28n%29%5C%5C+0+%26+%5Ctext%7B+if+%7D+%5Calpha+%5Ctextgreater+%281%2B%5Cepsilon%29+%5Calpha_c%28n%29+%5Cend%7Bcases%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
However, this theorem allows for the possibility that the threshold depends on . From a statistical physics standpoint, this would be ridiculous, as it suggests that the behavior of the system depends on the number of particles that participate in it. We state the commonly held stronger conjecture:
Conjecture:
for all , there exists a constant  depending only on such that if is a random -SAT instance in variables and clauses, then
depending only on such that if is a random -SAT instance in variables and clauses, then
![\lim_{n \to \infty} \Pr[\phi \text{ is satisfiable}] = \begin{cases} 1 & \text{ if } \alpha \textless \alpha_c \\ 1 & \text{ if } \alpha \textgreater \alpha_c \end{cases}](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5CPr%5B%5Cphi+%5Ctext%7B+is+satisfiable%7D%5D+%3D+%5Cbegin%7Bcases%7D+1+%26+%5Ctext%7B+if+%7D+%5Calpha+%5Ctextless+%5Calpha_c+%5C%5C+1+%26+%5Ctext%7B+if+%7D+%5Calpha+%5Ctextgreater+%5Calpha_c+%5Cend%7Bcases%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
In 2015, Jian Ding, Allan Sly, and Nike Sun established the -SAT conjecture all larger than some fixed constant  , and we will be hearing about the proof from Nike later on in the course.
, and we will be hearing about the proof from Nike later on in the course.
Bounds on via the method of moments
Let us move to a simpler model of random -SAT formulas, which is a bit easier to work with and is a close approximation to our original model. Instead of sampling -SAT clauses without replacement, we will sample them with replacement and also allow variables to appear multiple times in the same clause (so each literal is chosen uniformly at random). The independence of the clauses makes computations in this model simpler.
We’ll prove the following bounds. The upper bound is a fairly straightforward computation, and the lower bound is given by an elegant argument due to Achlioptas and Peres.
Theorem:
For every ,  .
.
Let be a random -SAT formula with  clauses, . For an assignment , let
clauses, . For an assignment , let 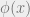 be the
be the 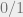 indicator that satisfies . Finally, let
indicator that satisfies . Finally, let  be the number of satisfying assignments of .
be the number of satisfying assignments of .
Upper bound via the first moment method.
We have by Markov’s inequality that
![\Pr[Z_{\alpha} \ge 1] \le \mathbb{E}[Z_{\alpha}] = \sum_{x} \Pr[\phi(x)].](https://s0.wp.com/latex.php?latex=%5CPr%5BZ_%7B%5Calpha%7D+%5Cge+1%5D+%5Cle+%5Cmathbb%7BE%7D%5BZ_%7B%5Calpha%7D%5D+%3D+%5Csum_%7Bx%7D+%5CPr%5B%5Cphi%28x%29%5D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Fix an assignment . Then by the independence of the clauses,
![\Pr[\phi(x)] = \prod_{j \in [m]} \Pr[C_j(x) = 1] = \left(1 - \frac{1}{2^k}\right)^m,](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Cphi%28x%29%5D+%3D+%5Cprod_%7Bj+%5Cin+%5Bm%5D%7D+%5CPr%5BC_j%28x%29+%3D+1%5D+%3D+%5Cleft%281+-+%5Cfrac%7B1%7D%7B2%5Ek%7D%5Cright%29%5Em%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
since each clause has  satisfying assignments. Summing over all
satisfying assignments. Summing over all
,
![\mathbb{E}[Z_{\alpha}] = 2^n \left(1 - \frac{1}{2^k}\right)^{\alpha n}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ_%7B%5Calpha%7D%5D+%3D+2%5En+%5Cleft%281+-+%5Cfrac%7B1%7D%7B2%5Ek%7D%5Cright%29%5E%7B%5Calpha+n%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
We can see that if  , this quantity will go to with . So we have:
, this quantity will go to with . So we have:

Lower bound via the second moment method.
To lower bound , we can use the second moment method. We’ll
calculate the second moment of  . An easy use of Cauchy-Schwarz (for non-negative
. An easy use of Cauchy-Schwarz (for non-negative  ,
, ![\mathbb{E}[X] \le \sqrt{\mathbb{E}[X^2]\mathbb{E}[I[X \textgreater 0]]}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D+%5Cle+%5Csqrt%7B%5Cmathbb%7BE%7D%5BX%5E2%5D%5Cmathbb%7BE%7D%5BI%5BX+%5Ctextgreater+0%5D%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002) ) implies that if there is a constant
) implies that if there is a constant  such that
such that
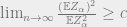 ,
,
then with at least constant probability  , and then Friedgut’s theorem implies that
, and then Friedgut’s theorem implies that 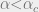 . From above we have an expression for the numerator, so we now set out to bound the second moment of . We have that
. From above we have an expression for the numerator, so we now set out to bound the second moment of . We have that
![\mathbb{E} Z_{\alpha}^2 = \mathbb{E}\left[\left(\sum_{x}I[\phi(x)]\right)^2\right] = \sum_{x,y} \Pr\left[\phi(x)\wedge \phi(y)\right],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+Z_%7B%5Calpha%7D%5E2+%3D+%5Cmathbb%7BE%7D%5Cleft%5B%5Cleft%28%5Csum_%7Bx%7DI%5B%5Cphi%28x%29%5D%5Cright%29%5E2%5Cright%5D+%3D+%5Csum_%7Bx%2Cy%7D+%5CPr%5Cleft%5B%5Cphi%28x%29%5Cwedge+%5Cphi%28y%29%5Cright%5D%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
and by the independence of the clauses,
![\Pr\left[\phi(x)\wedge \phi(y)\right] = \prod_{j \in [m]} \Pr[C_j(x) = 1 \wedge C_j(y) = 1] = \left(\Pr[C(x) = 1 \wedge C(y) = 1]\right)^m,](https://s0.wp.com/latex.php?latex=%5CPr%5Cleft%5B%5Cphi%28x%29%5Cwedge+%5Cphi%28y%29%5Cright%5D+%3D+%5Cprod_%7Bj+%5Cin+%5Bm%5D%7D+%5CPr%5BC_j%28x%29+%3D+1+%5Cwedge+C_j%28y%29+%3D+1%5D+%3D+%5Cleft%28%5CPr%5BC%28x%29+%3D+1+%5Cwedge+C%28y%29+%3D+1%5D%5Cright%29%5Em%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
for a single random -SAT clause  . But, for
. But, for  , the events
, the events  and
and  are not independent. This is easier to see if we apply inclusion-exclusion,
are not independent. This is easier to see if we apply inclusion-exclusion,
![\Pr[C(x) = 1 \wedge C(y) = 1] = 1 - \Pr[C(x) = 0] - \Pr[C(y) = 0] + \Pr[C(x) = C(y) = 0],](https://s0.wp.com/latex.php?latex=%5CPr%5BC%28x%29+%3D+1+%5Cwedge+C%28y%29+%3D+1%5D+%3D+1+-+%5CPr%5BC%28x%29+%3D+0%5D+-+%5CPr%5BC%28y%29+%3D+0%5D+%2B+%5CPr%5BC%28x%29+%3D+C%28y%29+%3D+0%5D%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
The event that both  when is a -SAT clause occurs only when and
when is a -SAT clause occurs only when and 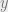 agree exactly on the assignments to the variables of , since otherwise at least one of or must be satisfied (because each literal in
agree exactly on the assignments to the variables of , since otherwise at least one of or must be satisfied (because each literal in  is negated for
is negated for  ). Thus, this probability depends on the Hamming distance between and .
). Thus, this probability depends on the Hamming distance between and .

For 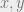 with
with  , the probability that ‘s variables are all in the subset on which agree is
, the probability that ‘s variables are all in the subset on which agree is 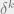 (up to lower order terms). So, we have
(up to lower order terms). So, we have
![\Pr[C(x) = C(y) = 0] = \delta^k \cdot \frac{1}{2^k},](https://s0.wp.com/latex.php?latex=%5CPr%5BC%28x%29+%3D+C%28y%29+%3D+0%5D+%3D+%5Cdelta%5Ek+%5Ccdot+%5Cfrac%7B1%7D%7B2%5Ek%7D%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
and then for with  ,
,
![\Pr[C(x) = 1 \wedge C(y) = 1] = 1 - 2\cdot \frac{1}{2^k} + \left(\frac{\ell}{2n}\right)^k.](https://s0.wp.com/latex.php?latex=%5CPr%5BC%28x%29+%3D+1+%5Cwedge+C%28y%29+%3D+1%5D+%3D+1+-+2%5Ccdot+%5Cfrac%7B1%7D%7B2%5Ek%7D+%2B+%5Cleft%28%5Cfrac%7B%5Cell%7D%7B2n%7D%5Cright%29%5Ek.&bg=eeeeee&fg=666666&s=0&c=20201002)
Because there are 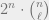 pairs at distance ,
pairs at distance ,
![\mathbb{E}\left[Z_{\alpha}^2\right] = \sum_{\ell = 0}^{n} 2^n \cdot \binom{n}{\ell} \cdot \left(1 - \frac{1}{2^{k-1}} + \left(\frac{\ell}{2n}\right)^k\right)^m,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BZ_%7B%5Calpha%7D%5E2%5Cright%5D+%3D+%5Csum_%7B%5Cell+%3D+0%7D%5E%7Bn%7D+2%5En+%5Ccdot+%5Cbinom%7Bn%7D%7B%5Cell%7D+%5Ccdot+%5Cleft%281+-+%5Cfrac%7B1%7D%7B2%5E%7Bk-1%7D%7D+%2B+%5Cleft%28%5Cfrac%7B%5Cell%7D%7B2n%7D%5Cright%29%5Ek%5Cright%29%5Em%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
and using the Stirling bound  ,
,

Using Laplace’s method, we can show that this sum will be dominated by the  terms around the maximizing summand; so defining
terms around the maximizing summand; so defining  ,
,
![\mathbb{E}[Z_{\alpha}^2] = O(1) \cdot \exp( n \cdot \max_{\delta \in [0,1]} \psi(\delta)).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ_%7B%5Calpha%7D%5E2%5D+%3D+O%281%29+%5Ccdot+%5Cexp%28+n+%5Ccdot+%5Cmax_%7B%5Cdelta+%5Cin+%5B0%2C1%5D%7D+%5Cpsi%28%5Cdelta%29%29.&bg=eeeeee&fg=666666&s=0&c=20201002)
If we want that ![\mathbb{E}[Z^2] \le c \cdot \mathbb{E}[Z]^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ%5E2%5D+%5Cle+c+%5Ccdot+%5Cmathbb%7BE%7D%5BZ%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002) , then we require that
, then we require that
![\max_{\delta \in [0,1]} \psi(\delta) \le \frac{1}{n}\ln(\mathbb{E}[Z]^2) = 2\ln 2 + 2\alpha \ln (1-2^{-k}).](https://s0.wp.com/latex.php?latex=%5Cmax_%7B%5Cdelta+%5Cin+%5B0%2C1%5D%7D+%5Cpsi%28%5Cdelta%29+%5Cle+%5Cfrac%7B1%7D%7Bn%7D%5Cln%28%5Cmathbb%7BE%7D%5BZ%5D%5E2%29+%3D+2%5Cln+2+%2B+2%5Calpha+%5Cln+%281-2%5E%7B-k%7D%29.&bg=eeeeee&fg=666666&s=0&c=20201002)
However, we can see (using calculus) that this inequality does not hold whenever 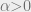 . In the plot below one can also see this, though the values are very close when is close to :
. In the plot below one can also see this, though the values are very close when is close to :
So the naive second moment method fails to establish any lower bound on . The problem here is that the second moment is dominated by the large correlations of close strings; whenever , the sum is dominated by pairs of strings which are closer than  in Hamming distance, which is atypical. For strings at Hamming distance , what is relevant is
in Hamming distance, which is atypical. For strings at Hamming distance , what is relevant is  , which is always
, which is always
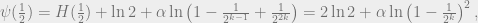
which is equal to ![\frac{1}{n}\ln\mathbb{E}[Z_{\alpha}]^2](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7Bn%7D%5Cln%5Cmathbb%7BE%7D%5BZ_%7B%5Calpha%7D%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002) . At distance , the value of on pairs is essentially uncorrelated (one can think of drawing a uniformly random given ), so such pairs are representative of
. At distance , the value of on pairs is essentially uncorrelated (one can think of drawing a uniformly random given ), so such pairs are representative of ![\mathbb{E}[Z]^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
A more delicate approach.
To get a good bound, we have to perform a fancier second moment method calculation, due to Achlioptas and Peres. We will re-weight the terms so that more typical pairs, at distance , are dominant. Rather than computing , we compute  , where
, where
![X_{\alpha} = \sum_{x} \prod_{j \in [m]} w_j(x),](https://s0.wp.com/latex.php?latex=X_%7B%5Calpha%7D+%3D+%5Csum_%7Bx%7D+%5Cprod_%7Bj+%5Cin+%5Bm%5D%7D+w_j%28x%29%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
where  if
if  , and
, and  if
if  is satisfied by
is satisfied by  variables. Since
variables. Since  only if has satisfying assignments, the goal is to still bound
only if has satisfying assignments, the goal is to still bound ![\mathbb{E}[X_{\alpha}^2] \le c\cdot \mathbb{E}[X_{\alpha}]^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7B%5Calpha%7D%5E2%5D+%5Cle+c%5Ccdot+%5Cmathbb%7BE%7D%5BX_%7B%5Calpha%7D%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002) . Again using the independence of the clauses, we have that
. Again using the independence of the clauses, we have that
![\begin{aligned} \mathbb{E}[X_{\alpha}] = 2^n \cdot \mathbb{E}[w_j(x)]^m = 2^n \left(2^{-k}\sum_{t = 1}^k \binom{k}{t} \eta^t \right)^m = 2^n \left(\left(\frac{1+\eta}{2}\right)^k-2^{-k}\right)^m.\label{eq:expect}\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5BX_%7B%5Calpha%7D%5D+%3D+2%5En+%5Ccdot+%5Cmathbb%7BE%7D%5Bw_j%28x%29%5D%5Em+%3D+2%5En+%5Cleft%282%5E%7B-k%7D%5Csum_%7Bt+%3D+1%7D%5Ek+%5Cbinom%7Bk%7D%7Bt%7D+%5Ceta%5Et+%5Cright%29%5Em+%3D+2%5En+%5Cleft%28%5Cleft%28%5Cfrac%7B1%2B%5Ceta%7D%7B2%7D%5Cright%29%5Ek-2%5E%7B-k%7D%5Cright%29%5Em.%5Clabel%7Beq%3Aexpect%7D%5Cend%7Baligned%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
And calculating again the second moment,
![\mathbb{E}[X_{\alpha}^2] = \sum_{x,y} \prod_{j \in [m]} \mathbb{E}[w_j(x)\cdot w_j(y)].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_%7B%5Calpha%7D%5E2%5D+%3D+%5Csum_%7Bx%2Cy%7D+%5Cprod_%7Bj+%5Cin+%5Bm%5D%7D+%5Cmathbb%7BE%7D%5Bw_j%28x%29%5Ccdot+w_j%28y%29%5D.&bg=eeeeee&fg=666666&s=0&c=20201002)
For a fixed clause 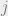 , we can partition the variables in its scope into 4 sets, according to whether agree on the variable, and whether the variable does or does not satisfy the literals of the clause. Suppose that
, we can partition the variables in its scope into 4 sets, according to whether agree on the variable, and whether the variable does or does not satisfy the literals of the clause. Suppose that 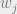 has
has  variables on which agree, and that of these are satisfying for and
variables on which agree, and that of these are satisfying for and  are not.
are not.
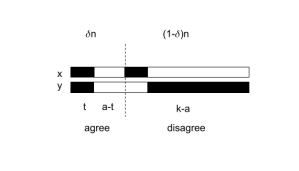
Then, has  variables on which disagree, and any variable which does not satisfy for must satisfy it for . For a
variables on which disagree, and any variable which does not satisfy for must satisfy it for . For a  to be nonzero, either there must be at least one literal in the variables on which agree which agrees with , or otherwise there must be at least one literal in the variables on which disagree which agrees with each string. Therefore, if agree on a -fraction of variables,
to be nonzero, either there must be at least one literal in the variables on which agree which agrees with , or otherwise there must be at least one literal in the variables on which disagree which agrees with each string. Therefore, if agree on a -fraction of variables,
![\begin{aligned} \mathbb{E}[w_j(x) \cdot w_j(y)] &= \sum_{a = 1}^k \sum_{t=1}^a \eta^{2t + k - a} \cdot \Pr[w_j \text{ has } a \text{ variables in } x \cap y,\ t \in x \cap y \text{ satisfy }w, \ w_j(x),w_j(y) \textgreater 0]\\ &= \left(\sum_{a = 0}^k\sum_{t=0}^a \eta^{k - a + 2t} \cdot \binom{k}{a}\delta^{a}\left(1 - \delta\right)^{k-a} 2^{-a} \binom{a}{t}\right) - \left(\sum_{a=0}^k \eta^{k-a} \binom{k}{a} \delta^a(1-\delta)^{k-a} 2^{-k+1}\right) + \delta^k2^{-k},\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5Bw_j%28x%29+%5Ccdot+w_j%28y%29%5D+%26%3D+%5Csum_%7Ba+%3D+1%7D%5Ek+%5Csum_%7Bt%3D1%7D%5Ea+%5Ceta%5E%7B2t+%2B+k+-+a%7D+%5Ccdot+%5CPr%5Bw_j+%5Ctext%7B+has+%7D+a+%5Ctext%7B+variables+in+%7D+x+%5Ccap+y%2C%5C+t+%5Cin+x+%5Ccap+y+%5Ctext%7B+satisfy+%7Dw%2C+%5C+w_j%28x%29%2Cw_j%28y%29+%5Ctextgreater+0%5D%5C%5C+%26%3D+%5Cleft%28%5Csum_%7Ba+%3D+0%7D%5Ek%5Csum_%7Bt%3D0%7D%5Ea+%5Ceta%5E%7Bk+-+a+%2B+2t%7D+%5Ccdot+%5Cbinom%7Bk%7D%7Ba%7D%5Cdelta%5E%7Ba%7D%5Cleft%281+-+%5Cdelta%5Cright%29%5E%7Bk-a%7D+2%5E%7B-a%7D+%5Cbinom%7Ba%7D%7Bt%7D%5Cright%29+-+%5Cleft%28%5Csum_%7Ba%3D0%7D%5Ek+%5Ceta%5E%7Bk-a%7D+%5Cbinom%7Bk%7D%7Ba%7D+%5Cdelta%5Ea%281-%5Cdelta%29%5E%7Bk-a%7D+2%5E%7B-k%2B1%7D%5Cright%29+%2B+%5Cdelta%5Ek2%5E%7B-k%7D%2C%5Cend%7Baligned%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
where the first sum ignores the cases when or  , the second sum subtracts for the cases when
, the second sum subtracts for the cases when  the contribution of the terms where all the literals agree with either or , and the final term accounts for the fact that the term
the contribution of the terms where all the literals agree with either or , and the final term accounts for the fact that the term  is subtracted
is subtracted
twice. Simplifying,
![\mathbb{E}[w_j(x) \cdot w_j(y)] = \left(\frac{(1+\eta^2)}{2}\delta + \eta(1-\delta)\right)^k - 2^{1-k} \left(\eta(1-\delta) + \delta\right)^k + \left(\frac{\delta}{2}\right)^k.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bw_j%28x%29+%5Ccdot+w_j%28y%29%5D+%3D+%5Cleft%28%5Cfrac%7B%281%2B%5Ceta%5E2%29%7D%7B2%7D%5Cdelta+%2B+%5Ceta%281-%5Cdelta%29%5Cright%29%5Ek+-+2%5E%7B1-k%7D+%5Cleft%28%5Ceta%281-%5Cdelta%29+%2B+%5Cdelta%5Cright%29%5Ek+%2B+%5Cleft%28%5Cfrac%7B%5Cdelta%7D%7B2%7D%5Cright%29%5Ek.&bg=eeeeee&fg=666666&s=0&c=20201002)
Define
 .
.
So we have (using Laplace’s method again)
![\mathbb{E}[X^2] = 2^n \sum_{\ell = 0}^n \binom{n}{\ell} q_\eta\left(\frac{\ell}{n}\right)^{\alpha n} \approx O(1) \cdot \exp(\max_{\delta \in [0,1]} \psi_\eta (\delta) \cdot n),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5E2%5D+%3D+2%5En+%5Csum_%7B%5Cell+%3D+0%7D%5En+%5Cbinom%7Bn%7D%7B%5Cell%7D+q_%5Ceta%5Cleft%28%5Cfrac%7B%5Cell%7D%7Bn%7D%5Cright%29%5E%7B%5Calpha+n%7D+%5Capprox+O%281%29+%5Ccdot+%5Cexp%28%5Cmax_%7B%5Cdelta+%5Cin+%5B0%2C1%5D%7D+%5Cpsi_%5Ceta+%28%5Cdelta%29+%5Ccdot+n%29%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
For
When  ,
,

which is equal to the log of the square of the expectation, so again for the second moment method to succeed, must be the global maximum.
Guided by this consideration, we can set  so that the derivative
so that the derivative 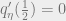 , so that
, so that  achieves a local maximum at . The choice for this (after doing some calculus) turns out to be the positive, real solution to the equation
achieves a local maximum at . The choice for this (after doing some calculus) turns out to be the positive, real solution to the equation 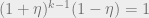 . With this choice, one can show that the global maximum is indeed achieved at as long as
. With this choice, one can show that the global maximum is indeed achieved at as long as 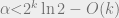 . Below, we plot
. Below, we plot  with this optimal choice of for several values of at
with this optimal choice of for several values of at  :
:
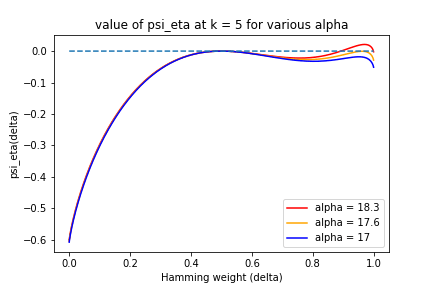
So we have bounded 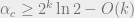 .
.
Another phase transition
What is the correct answer for ? We now have it in a window of size  . Experimental data and heuristic predictions indicate that it is closer to
. Experimental data and heuristic predictions indicate that it is closer to  (and in fact for large , Ding, Sly and Sun showed that is a specific constant in the interval
(and in fact for large , Ding, Sly and Sun showed that is a specific constant in the interval ![[2^k \ln 2 -2, 2^k \ln 2]](https://s0.wp.com/latex.php?latex=%5B2%5Ek+%5Cln+2+-2%2C+2%5Ek+%5Cln+2%5D&bg=eeeeee&fg=666666&s=0&c=20201002) ). So why can’t we push the second moment method further?
). So why can’t we push the second moment method further?
It turns out that there is a good reason for this, having to do with another phase transition. In fact, we know that -SAT has not only satisfiable and unsatisfiable phases, but also clustering and condensation phases:

In the clustering phase, there are exponentially many clusters of solutions, each containing exponentially many solutions, and each at hamming distance  from each other. In the condensation phase, there are even fewer clusters, but solutions still exist. We can see evidence of this already in the way that the second moment method failed us. When
from each other. In the condensation phase, there are even fewer clusters, but solutions still exist. We can see evidence of this already in the way that the second moment method failed us. When  , we see that the global maximum of the exponent is actually attained close to
, we see that the global maximum of the exponent is actually attained close to  . This is because solutions with large overlap come to dominate the set of satisfying assignments.
. This is because solutions with large overlap come to dominate the set of satisfying assignments.
One can also establish the existence of clusters using the method of moments. The trick is to compute the probability that two solutions, and with overlap 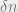 , are both satisfying for . In fact, we have already done this. From above,
, are both satisfying for . In fact, we have already done this. From above,
![\Pr\left[\phi(x) \wedge \phi(y) ~\mid~ \frac{1}{2}\|x - y\|_1 = (1-\delta)n\right] = \left(1 - 2\cdot \frac{1}{2^k} + 2^{-k}\delta^k\right)^{\alpha n}.](https://s0.wp.com/latex.php?latex=%5CPr%5Cleft%5B%5Cphi%28x%29+%5Cwedge+%5Cphi%28y%29+%7E%5Cmid%7E+%5Cfrac%7B1%7D%7B2%7D%5C%7Cx+-+y%5C%7C_1+%3D+%281-%5Cdelta%29n%5Cright%5D+%3D+%5Cleft%281+-+2%5Ccdot+%5Cfrac%7B1%7D%7B2%5Ek%7D+%2B+2%5E%7B-k%7D%5Cdelta%5Ek%5Cright%29%5E%7B%5Calpha+n%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Now, by a union bound, an upper bound on the probability that there exists a pair of solutions with overlap for any ![\delta \in [\delta_1,\delta_2]](https://s0.wp.com/latex.php?latex=%5Cdelta+%5Cin+%5B%5Cdelta_1%2C%5Cdelta_2%5D&bg=eeeeee&fg=666666&s=0&c=20201002) is at most
is at most
![\Pr[\exists x,y \ s.t. \ \phi(x) \wedge \phi(y), \ \frac{1}{2}\|x-y\|_1 = (1-\delta)n \text{ for } \delta \in [\delta_1,\delta_2]] \le \sum_{\ell = \delta_1 n}^{\delta_2 n} \binom{n}{\ell} \left(1 - 2^{1-k} + \left(\frac{\ell}{2n}\right)^k\right)^{\alpha n}](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Cexists+x%2Cy+%5C+s.t.+%5C+%5Cphi%28x%29+%5Cwedge+%5Cphi%28y%29%2C+%5C+%5Cfrac%7B1%7D%7B2%7D%5C%7Cx-y%5C%7C_1+%3D+%281-%5Cdelta%29n+%5Ctext%7B+for+%7D+%5Cdelta+%5Cin+%5B%5Cdelta_1%2C%5Cdelta_2%5D%5D+%5Cle+%5Csum_%7B%5Cell+%3D+%5Cdelta_1+n%7D%5E%7B%5Cdelta_2+n%7D+%5Cbinom%7Bn%7D%7B%5Cell%7D+%5Cleft%281+-+2%5E%7B1-k%7D+%2B+%5Cleft%28%5Cfrac%7B%5Cell%7D%7B2n%7D%5Cright%29%5Ek%5Cright%29%5E%7B%5Calpha+n%7D&bg=eeeeee&fg=666666&s=0&c=20201002)

and if the function 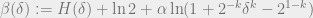 is such that
is such that  for all , then we conclude that the probability that there is a pair of satisfying assignments at distance between
for all , then we conclude that the probability that there is a pair of satisfying assignments at distance between 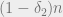 and
and  is
is  .
.
Achlioptas and Ricci-Tersenghi showed that for  ,
,  , and
, and  a fixed constant, the above function is less than . Rather than doing the tedious calculus, we can verify by plotting for
a fixed constant, the above function is less than . Rather than doing the tedious calculus, we can verify by plotting for  (with
(with  ):
):
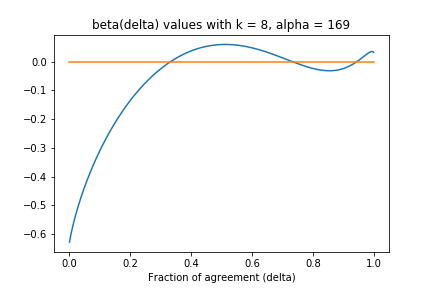
They also use the second moment method to show the clusters are non-empty, that there are exponentially many of them, each containing exponentially many solutions. This gives a proof of the existence of a clustering regime.
Solution geometry and algorithms
This study of the space of solutions is referred to as solution geometry, and understanding solution geometry turns out to be essential in proving better bounds on the critical density.
Solution geometry is also intimately related to the success of local search algorithms such as belief propagation, and to heuristics for predicting phase transitions such as replica symmetry breaking.
These topics and more to follow, in the coming weeks.
Resources
In preparing this blog post/lecture I leaned heavily on Chapters 2 and 10 of Marc Mézard and Andrea Montanari’s “Information, Physics, and Computation”, on Chapters 12,13,&14 of Cris Moore and Stephan Mertens’ “The nature of Computation,” and on Dimitris Achlioptas and Federico Ricci-Tersenghi’s manuscript “On the Solution-Space Geometry of Random CSPs”. I also consulted Wikipedia for some physics basics.







Congratulations for the first and very nice blog post, Tselil.