by Fred Zhang
This is the second installment of a three-part series of posts on quantum Hamiltonian complexity based on lectures given by the authors in Boaz and Tselil’s seminar. For the basic definitions of local Hamiltonians, see Ben’s first post. Also check out Boriana and Prayaag’s followup note on area laws.
This post introduces tensor networks and matrix product states (MPS). These are useful linear-algebraic objects for describing quantum states of low entanglement.
We then discuss how to efficiently compute the ground states of the Hamiltonians of 
1. Introduction
We are interested in computing the ground state—the minimum eigenvector—of a quantum Hamiltonian, a 


Despite the hardness results, physicists have come up with a variety of heuristics for solving this problem. If quantum interactions occur locally, we would hope that its ground state has low entanglement and thus admits a succinct classical representation. Further, we hope to find such a representation efficiently, using classical computers.
In this note, we will see tensor networks and matrix product states that formalize the idea of succinctly representing quantum states of low entanglement. As a side remark for the theoretical computer scientists here, one motivation to study tensor network is that it provides a powerful visual tool for thinking about linear algebra. It turns indices into edges in a graph and summations over indices into contractions of edges. In particular, we will soon see that the most useful inequality in TCS and mathematics can be drawn as a cute tensor network.

In the end, we will discuss the density matrix renormalization group (DMRG), which has established itself as “the most powerful tool for treating 1D quantum systems” over the last decade [FSW07]. For many 1D systems that arise from practice, the heuristic efficiently finds an (approximate) ground state in its matrix product state, specified only by a small number of parameters.
2. Tensor Networks
Now let us discuss our first subject, tensor networks. If you have not seen tensors before, it is a generalization of matrices. In computer scientists’ language, a matrix is a two-dimensional array, and a tensor is a multi-dimensional array. In other words, if we think of a matrix as a square, then a 3 dimensional tensor looks like a cube. Formally, a (complex) n dimensional tensor 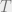
![\displaystyle T : [d_1] \times [d_2] \times \cdots \times [d_n] \rightarrow \mathbb{C}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+T+%3A+%5Bd_1%5D+%5Ctimes+%5Bd_2%5D+%5Ctimes+%5Ccdots+%5Ctimes+%5Bd_n%5D+%5Crightarrow+%5Cmathbb%7BC%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
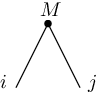
The simplest tensor network is a graphical notation for a tensor. For an 



 . The numbers are chosen arbitrarily.
. The numbers are chosen arbitrarily.Notice that the degree of the center is the number of indices. Hence, a tensor network of degree 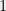
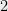


How is this related to quantum information? For the sake of genearlity we will deal with qudits in 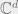
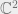
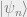


It is easy to see that all the information, namely, the amplitudes, is just the tensor 
So far our discussion is focused merely on these little pictures. The power of tensor networks come from its composition rules, which allow us to join two simple tensor networks together and impose rich internal structures.
2.1. Composition Rules
We introduce two ways of joining two simple tensor networks. Roughly speaking, they correspond to multiplication and summation, and I will give the definitions by showing examples, instead of stating them in the full formalism
Rule #1: Tensor Product. The product rule allows us to put two tensor networks together and view them as a whole. The resulting tensor is the tensor product of the two if we think of them as vectors. More concretely, consider the following picture.
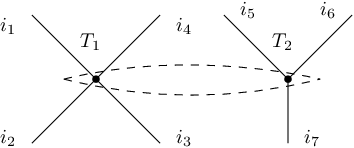 of 7 edges .
of 7 edges .The definition of this joint tensor
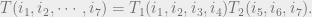
Rule #2: Edge Contractions. At this moment, we can only make up disconnected tensor networks. Edge contractions allow us to link two tensor networks. Suppose we have two 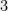



We name the contracted edge as 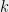

2.2. Useful Examples
Before we move on, let’s take some examples. Keep in mind that the degree of the vertex determines the number of indices (dimensions of this tensor).

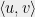

Here, one needs to remember that an edge between two tensor nodes is a summation over the index corresponding to the edge. For example, in the vector inner product picture, 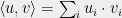
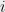
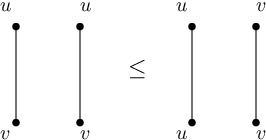
is the famous
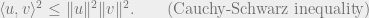
For us, the most important building block is matrix multiplication. Let 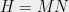

This is precisely encoded in the picture below.

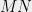 .
. We are ready to talk about matrix product states. In the language of tensor network, a matrix product state is the following picture.

As the degrees indicate, the two boundary vertices 
3. Matrix Product States
Before giving the definition, let’s talk about how matrix product state (MPS) naturally arises from the study of quantum states with low entanglement. Matrix product state can be viewed as a generalization of product state—(pure) quantum state with no entanglement. Let’s consider a simple product state 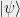

This state is described by 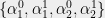
More formally, a matrix product state starts with the following setup. For an
- a qudit in
with
vectors
; and
- a qudit
with
.
Here, 
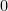

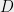
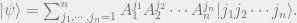
It is important to keep in mind that 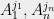
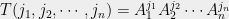
Now back to the picture,
notice that each amplitude 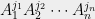

The complexity of the MPS is closely related to the bond dimension 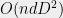


4. Density Matrix Renormalization Group
We are now ready to describe Density Matrix Renormalization Group, proposed originally in [Whi92, Whi93]. As mentioned earlier, it does not come with provable guarantees. In fact, one can construct artificial hard instances such that the algorithm get stuck at certain local minima [SCV08]. However, it has remained one of the most successful heuristics for
DMRG is a simple alternating minimization scheme for computing the ground state of a 
Formally, the Hamiltonian problem can be phrased as a eigenvalue problem given a Hermitian matrix 

Here, we assume that the input Hamiltonian is in the product form. In particular, it means that it can be written as a tensor network as
 D Hamiltonian is of the particular product form.
D Hamiltonian is of the particular product form.so the numerator of the optimization objective looks like

The DMRG works with the Langrangian of the objective. For some 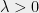
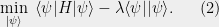
DMRG optimizes over the set of matrices associated with one qudit. Both terms in (2) are quadratic in this set of matrices.

 as a tensor network.
as a tensor network.Now to optimize over the set of parameters associated with one site, calculus tells you to set the (partial) derivative to
 and solve.
and solve.Notice that the unknown is still there, on the bottom side of each term. The trick of DMRG is to view the rest of the network as a linear map applied to the unknown.

Given 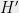
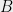

This is called a generalized eigenvalue problem, and it is well studied. Importantly, for
5. Concluding Remarks
Our presentation of tensor networks and MPS roughly follows [GHLS15], a nice introductory survey on quantum Hamiltonian complexity.
The notion of tensor networks extends well beyond 1D systems, and a generalization of MPS is called tensor product state. It leads to algorithms for higher dimensional quantum systems. One may read [CV09] for a comprehensive survey.
Tensor network has been interacting with other concepts. Within physics, it has been used in quantum error correction [FP14, PYHP15], conformal field theory [Orú14], and statistical mechanics [EV15]. In TCS , we have found its connections with Holographic algorithms [Val08, CGW16], arithmetic complexity [BH07, CDM16, AKK19], and spectral algorithms [MW18]. In machine learning, it has been applied to probabilistic graphical models [RS18], tensor decomposition [CLO16], and quantum machine learning [HPM18].
For DMRG, we have only given a rough outline, with many details omitted, such as how to set 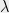
References
[AKK19] Per Austrin, Peeri Kaski, and Kaie Kubjas. Tensor network complexity of multilinear maps. In Proceedings of the 2019 Conference on Innovations in Theoretical Computer Science. ACM, 2019.
[BH07] Martin Beaudry and Markus Holzer. The complexity of tensor circuit evaluation. Computational Complexity, 16(1):60, 2007.
[CDM16] Florent Capelli, Arnaud Durand, and Stefan Mengel. e arithmetic complexity of tensor contraction. eory of Computing Systems, 58(4):506{527, 2016.
[CGW16] Jin-Yi Cai, Heng Guo, and Tyson Williams. A complete dichotomy rises from the capture of vanishing signatures. SIAM Journal on Computing, 45(5):1671{1728, 2016.
[CLO16] Andrzej Cichocki, Namgil Lee, Ivan V Oseledets, A-H Phan, Qibin Zhao, and D Mandic. Low-rank tensor networks for dimensionality reduction and large-scale optimization problems: Perspectives and challenges part 1. arXiv preprint arXiv:1609.00893, 2016.
[CV09] J Ignacio Cirac and Frank Verstraete. Renormalization and tensor product states in spin chains and laices. Journal of Physics A: Mathematical and Theoretical, 42(50):504004, 2009.
[Eis06] Jens Eisert. Computational difficulty of global variations in the density matrix renormalization group. Phys. Rev. Le., 97:260501, Dec 2006.
[EV15] G. Evenbly and G. Vidal. Tensor network renormalization. Phys. Rev. Le., 115:180405, Oct 2015.
[FP14] Andrew J Ferris and David Poulin. Tensor networks and quantum error correction. Phys. Rev. Le., 113(3):030501, 2014.
[FSW07] Holger Fehske, Ralf Schneider, and Alexander Weie. Computational Many-Particle Physics. Springer, 2007.
[GHLS15] Sevag Gharibian, Yichen Huang, Zeph Landau, and Seung Woo Shin. Quantum Hamiltonian complexity. Foundations and Trends in Theoretical Computer Science, 10(3):159, 2015.
[HPM18] William James Huggins, Piyush Patil, Bradley Mitchell, K Birgia Whaley, and Miles Stoudenmire. Towards quantum machine learning with tensor networks. Quantum Science and Technology, 2018.
[MW18] Ankur Moitra and Alexander S Wein. Spectral methods from tensor networks. arXiv preprint arXiv:1811.00944, 2018.
[Orú14] Román Orús. Advances on tensor network theory: symmetries, fermions, entanglement, and holography. e European Physical Journal B, 87(11):280, 2014.
[PYHP15] Fernando Pastawski, Beni Yoshida, Daniel Harlow, and John Preskill. Holographic quantum error-correcting codes: Toy models for the bulk/boundary correspondence. Journal of High Energy Physics, 2015(6):149, 2015.
[RS18] Elina Robeva and Anna Seigal. Duality of graphical models and tensor networks. Information and Inference: A Journal of the IMA, 2018.
[Sch05] Ulrich Schollwöck. The density-matrix renormalization group. Rev. Mod. Phys., 77(1):259, 2005.
[Sch11] Ulrich Schollwöck. The density-matrix renormalization group in the age of matrix product states. Annals of Physics, 326(1):96, 2011.
[SCV08] Norbert Schuch, Ignacio Cirac, and Frank Verstraete. Computational difficulty of finding matrix product ground states. Phys. Rev. Le., 100(25):250501, 2008.
[Val08] Leslie G Valiant. Holographic algorithms. SIAM Journal on Computing, 37(5):1565, 2008.
[Whi92] Steven R. White. Density matrix formulation for quantum renormalization groups. Phys. Rev. Le., 69:2863, Nov 1992.
[Whi93] Steven R. White. Density-matrix algorithms for quantum renormalization groups. Phys. Rev. B, 48:10345, Oct 1993.

.