(This post is based on part of a lecture delivered by Boriana Gjura and Prayaag Venkat. See also posts by Ben Edelman and Fred Zhang for more context on Quantum Hamiltonian Complexity.)
Introduction
In this post we present the Area Law conjecture and prove it rigorously,
emphasizing the emergence of approximate ground state projectors as a
useful and promising tool.
The difficulty of understanding many-body physics lies in this dichotomy
between the power of quantum on the one hand, and the fact that even
describing a quantum state requires exponential resources on the other.
A natural way to proceed is to ask if the special class of physically
relevant states admits succinct descriptions. As seen in a previous
post, the QMA-completenes of the 
that even ground states of local Hamiltonians do not admit such
descriptions. Looking at these ground states, the following questions
arise naturally.
When do the ground states of local Hamiltonians have a special
structure? When does that structure allow for a meaningful short
description? When does that structure allow us to compute properties
of them?
As stated informally, the answer to these questions is yes for (gapped)
1D systems, and it is an open problem to answer these in higher
dimensions.
The Area Law
The Area Law is inspired by the Holographic principle in Cosmology,
which informally states that the total information in a black hole
resides on the boundary. That is, the complexity of the system depends
on the size of its boundary, not its volume.
Preliminaries
For the sake of clarity, we assume that 
2-local Hamiltonian on qubits, each 
projection 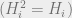
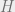

ground state 
These conditions simplify our proof. It will be easy to generalize to
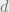
frustration-free: more work is necessary to make the proof work
otherwise.
To formalize our conjecture, we define a notion of von Neumman entropy
below.
Definition: Consider any state
lying in a bipartite Hilbert space
, and perform a Schmidt
decomposition to obtain
.
The Von Neumann entanglement entropy of
is defined as
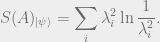
Why is this a good notion of entropy? If
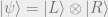
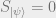
the other hand, the maximally entangled state
has entropy 

This is a
direct quantum generalization of the fact that a classical probability
distribution on 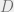

achieved by the uniform distribution.\
We can now state the Area Law.
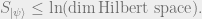
Conjecture: Let
Then for any region(i.e. a subset of qubits),
where
denotes the boundary of the region
through


This conjecture is illustrated by the following figure.

We prove the 1-D version of this conjecture. Note that for a 1D system
(i.e. qubits on a line with nearest neighbor interactions) it suffices
to consider bipartitions of the Hilbert space defined by a “cut” (see
the figure below). By a cut, we mean a partition of the qubits into two
sets consisting of all the qubits to the left and right, respectively,
of a fixed qubit 

Theorem: Let
,
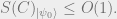
Approximate Ground State Projectors
In the case where all 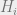

onto the ground state. Therefore, we can get a representation of the
ground state as a matrix product state (as we saw in a previous post on
tensor networks). Can we generalize this idea when the
necessarily commute?
A natural idea is to define an operator that approximately projects a
state onto the vector we want (the ground state), while shrinking it on
the other directions. We also want this operator to not increase
entanglement too much. The proof of the area law will involve
constructing a low-rank tensor approximate factorization of the ground
state by starting with a factorized state, which has a good overlap with
the ground state, and then repeatedly applying such an operator.
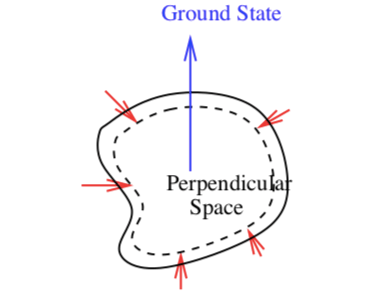
We first give a formal definition of an approximate ground state
projector. In the following, under the assumption of the existence of
such an object, we will prove the area law. At the end, we will show how
to construct it.
Definition:
is a
–approximate ground state projection (AGSP) if:
1.
2. For everysuch that
, then
.
3.
decomposition of the form,
whereand
act only on the particles to the left and
right of the cut, respectively.

The first step of the proof of the Area Law is to find a product state
that has a good overlap with the ground state. That is, it should have a
constant overlap that is not dependent on 
in the system.
Lemma 1: Suppose there exists a
-AGSP such that
. Fix a partition
of the space
on which the Hamiltonian acts. Then there exists a product state
such that

Proof:
Let 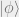

where the latter is some state orthogonal to the ground state. We apply
where 

the properties of the operator

inequality:


Therefore there exists a product state such that

which implies that 

Starting with a product state with a big enough overlap with the ground
state, the proof of the next lemma shows how we can repeatedly apply
AGSPs to bound the entropy across the cut.
Lemma 2: Suppose there exists a
. Then

But before we prove this, let’s state an intuitive result of Eckart and
Young, which provides an upper bound for the overlap of two states given
the Schmidt rank of one.
Lemma (Eckart-Young): Let
be a normalized
vector with Schmidt decomposition
, where
. Then for any normalized
it holds that

Using this result, we continue the proof.
Proof of Lemma 2:
Write the
denote by 
projections on the state, namely
By the way we’ve defined
increases by a power of 
the ground state, that is:

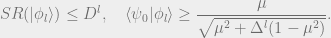
Let 
the Schmidt decomposition of the ground state relative to the cut
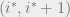
Eckart-Young theorem gives:
from which

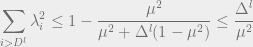
We choose

that 
worst case entropy accross the AGSP cut. The first 
coefficients account for an entropy of at most 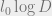
remaining coefficients, we group them in chunks of size
intervals ![[D^{kl_0} + 1, D^{(k+1)l_0}]](https://s0.wp.com/latex.php?latex=%5BD%5E%7Bkl_0%7D+%2B+1%2C+D%5E%7B%28k%2B1%29l_0%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
these intervals, the corresponding entropy can be upper bounded by
where here 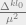
probability mass in the interval, and 
the size of any Schmidt coefficient (squared) in the interval. This
follows from the fact that they are organized in descending order and
must sum to 1.

Therefore, the total entropy is

This bound depends on 
Area Law because our AGSP constructions will have constant
AGSP Construction
In this section, our goal is to construct an AGSP with the correct
tradeoff in parameters. We briefly recall the intuition behind the
properties that an AGSP must satisfy. First, the AGSP should leave the
ground state untouched. Second, it shrinks states which are orthogonal
to the fround state. Third, it should not increase the entanglement
across the cut by too much (see the figure below).
A depiction of the third property in the AGSP definition for a 1D
system. The property that
which only act on one “side” of the
system.
![]()
We are interested in understanding a construction of an AGSP for three
reasons:
- As we saw before, we can prove a 1D area law assuming the existence
of an AGSP with good parameters. - AGSPs have been used a building block in an provably polynomial-time
algorithm for finding ground states of gapped 1D local Hamiltonians. - They appear to be a general purpose tool with potential applications
in other contexts.
Details of the construction
One way to think about the the first two properties in the AGSP
definition is in terms of the relationship of the eigenvalues of
the eigenvalues of
that the ground state of
eigenvalue 1. The second property says that all other eigenvectors of
In this plot, the horizontal axis represents the eigenvalues of
and the vertical axis represents the eigenvalues of
state of
upon applying
it.

In the following, we will aim to construct and AGSP whose tradeoff in
parameters allows us to achieve the following result.
Theorem:
.
Attempt 1
As a first attempt, we will evaluate the quality of the following
operator:
where
number that we will decide upon later. We now check the three properties
for this particular choice of

First, it is clear that
ground state is an eigenvector of
(frustration-free case). Second, because any other eigenvalue of
at least 

Third, for the time being, let us think of
to
Unfortunately, these values
achieve the desired tradeoff of
this is, observe that because we have 

to
corresponding increase in
The first attempt an AGSP corresponds to the polynomial is depicted in
blue. This polynomial does not decay at a fast enough rate, so the
second attempt will replace it with another polynomials, depicted in
red, which decays much
faster.
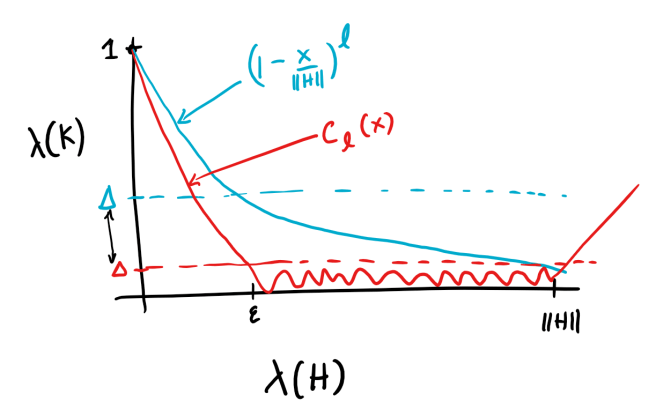
Attempt 2
In summary, the two weaknesses of the previous approach we need to
address are:
- The large
shinking effect of applying the AGSP. We will address this using the
technique of Hamiltonian truncation. - For a fixed
does not decay
fast enough after the point(which is the ground state
energy). We will address this using Chebyshev polynomials.
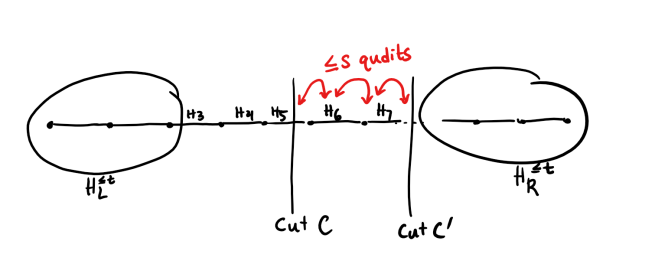
As discussed before, the
contribution from all
believe that only the local Hamiltonians near the site of the cut itself
should play a large role in the entanglement of the ground state across
the cut. Specifically, if we write
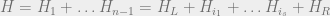


and 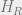
Hamiltonians to the left and right, respectively, of 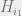

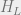
significantly to
characterize the ground state (see figure below).
We keep track of the local Hamiltonians corresponding to the
qudits directly surrounding the cut. The remaining local Hamiltonians
are aggregated into the Hamiltonians
will be truncated to define

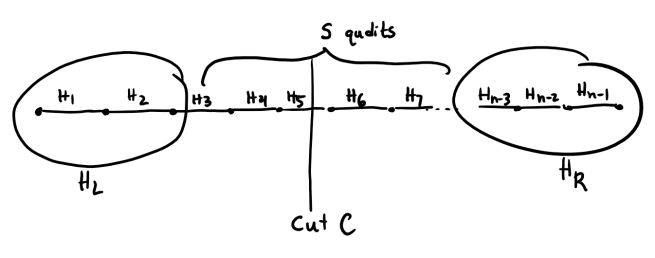
Mathematically, if we let


of 
Claim:
1.
2.
3.


It is straightforward to verify the two first two claims, We omit the
proof of the third claim. Intuitively, we have chosen
approximation of
Next, we come to the task of designing a degree-
decays faster than our first attempt
after the point 

![[\epsilon, \| H' \|]](https://s0.wp.com/latex.php?latex=%5B%5Cepsilon%2C+%5C%7C+H%27+%5C%7C%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
![[0,\Delta]](https://s0.wp.com/latex.php?latex=%5B0%2C%5CDelta%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
polynomial (of the first kind) is precisely the polynomial which has
this behavior (see the appendix for a review of Chebyshev polynomials).
Letting 
polynomial to be a scaled and shifted version of it:
Given this definition of


Claim:
1.
2.
3.

The first claim is straightforward to verify. The proof of the second
claim is ommitted; it involves calculations making use of standard
properties of Chebyshev polynomials. We remark that the dependence of
the exponent 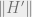
amount, compared with the first attempt at an AGSP. We now sketch the
main ideas behind the proof of the third claim. After that, we will
choose values of 
achieved.
We have defined
it as: 

whose particular values are not relevant to the analysis of the Schmidt
rank of
the Schmidt rank of
monomials 
Schmidt rank of the monomial of the largest degree, 
From our expression for
where the summation is over all products of
set 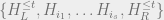
natural approach to proceed is to analyze the Schmidt rank of each term
in the summation, and then sum over all the terms. Unfortunately, this
approach will not work because there are exponentially many terms in the
summation, so our estimate of
issue, it is possible to collect terms cleverly so that the total number
of terms is small. However, we will not provide the details here; we
will just sketch how analyze the Schmidt rank of an individual term.
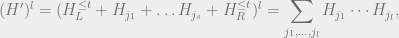
The term 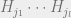
Hamiltonians. Since there are 
crossed by one of the 

crosses this average cut, the Schmidt rank will be multiplied by a
factor of 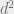

Schmidt rank is for an average cut 
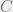
fixed in the beginning. The two cuts are separated by at most
qudits because
below), so one can relate the Schmidt rank across these two cuts. For
each Hamiltonian between the two cuts, the high-level idea is that the
entanglement rank is multiplied by at most a factor of
entanglement rank across
rank across 
The entanglement across cut
across a nearby cut
two.
Putting all the pieces together, we have that:
- By Hamiltonian truncation and the Chebyshev polynomial construction,
.
- By the entanglement rank analysis,
.
One can now check that if we set 
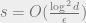
hidden inside the 
Towards an area law in high dimensions
One of the major open problems in this line of work is to prove an area
law for 2D systems. We now discuss one potential line of attack on this
problem, based on a reduction to the 1D area law we have proven using
AGSPs.
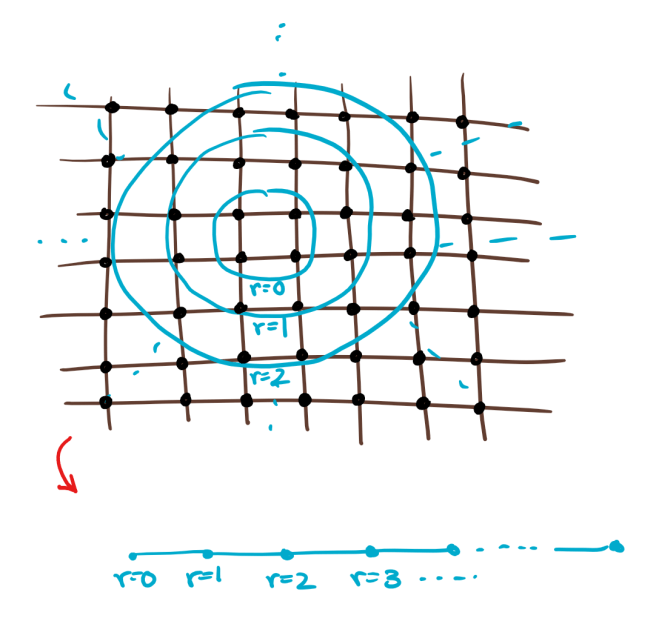
Consider a 2D system, as depicted in the figure below. We can form a
sequence of concentric shells of qudits of increasing radii and
“contract” each shell into a single qudit of higher dimension. That is,
if each of the original qudits have dimension
shell at radius 
contracted qudits is now a 1D system in the sense that the shell at
radius 

A 2D system can be reduced to a 1D system by decomposing it into a
sequence of concentric
“shells”.
Suppose that we were able to show an area law as discussed previously,
but with the following dependence on
If we replace
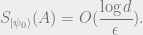
which is exactly an
area law in 2D (recalling that surface area of a circle is proportional
to its radius). In fact, even the weaker result of proving that

some 
breakthrough. This suggests that constructing AGSPs with better
parameters may be a plausible approach to proving an area law.

Future Directions
In addition to proving an area law in 2D, there are several interesting
questions raised by what we discussed here. See the survey of Gharibian
et al. for more details.
- Do area laws hold for gapless (i.e. non-constant gap, or “critical”)
systems? No, there are known counterexamples. - Do area laws hold for degenerate systems (where the ground state is
not unique)? Yes, the AGSP approach still works for systems with
groundspaces of constant dimension. It is unknown whether area laws
hold when the groundspace is of dimension polynomial in - Can one design practical algorithms for finding ground states of
gapped 1D local Hamiltonians? Yes, there is one approach based on
AGSPs. - Do area laws hold in general for systems where the interactions are
not necessarily described by a lattice? No, there are known
counterexamples to such a “generalized area law”?
Acknowledgements
We would like to thank Boaz Barak and Tselil Schramm for their guidance
in preparing the talk on which this post is based.
Most of this post (including some figures) draws heavily upon the
following resources: lecture notes from courses taught by Thomas Vidick and Umesh Vazirani,
repectively, and a survey by Gharibian et al.
In these notes, we have opted to illustrate the main ideas, while
glossing over technical details. Our goal with this approach is to
prepare the reader to more easily understand the original sources and
highlight the some of the key concepts.
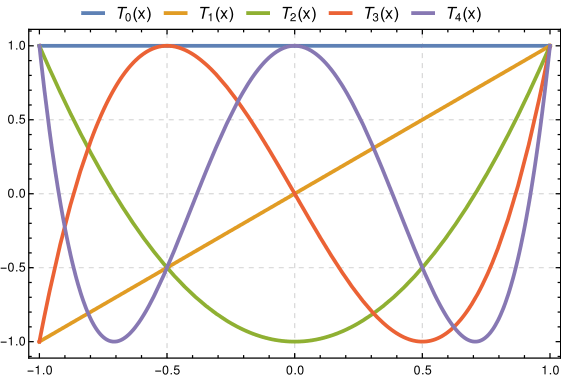
Appendix: Background on Chebyshev Polynomials
The Chebsyhev polynomials 
polynomials with many special properties. They are defined as


The first few polynomials are plotted below (Source:
<https://en.wikipedia.org/wiki/Chebyshev_polynomials>).

Below, we state a property (proof ommitted) which provides some
intuition as to why Chebyshev polynomials are the “correct” choice for
our construction. Intuitively, it says that among all degree-
polynomials which are trapped inside ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Claim: Let
be a degree-
such thatfor all
. Then for all
,
.
References
- Sevag Gharibian, Yichen Huang, Zeph Landau, Seung Woo Shin, et al. “Quantum Hamiltonian Complexity”. Foundations and Trends in Theoretical Computer Science, 10(3):159–282, 2015.
- Thomas Vidick. Lecture notes for CS286 seminar in computer science: “Around the quantum PCP conjecture”. http://users.cms.caltech.edu/~vidick/teaching/286_qPCP/index.html, Fall 2014.
- Umesh Vazirani. Lecture notes for CS294-4 “Quantum computation”. https://people.eecs.berkeley.edu/~vazirani/f16quantum.html, Fall 2016.

3 thoughts on “A 1D Area Law for Gapped Local Hamiltonians”