
(Updated and expanded 12/17/2021)
I am teaching deep learning this week in Harvard’s CS 182 (Artificial Intelligence) course. As I’m preparing the back-propagation lecture, Preetum Nakkiran told me about Andrej Karpathy’s awesome micrograd package which implements automatic differentiation for scalar variables in very few lines of code.
I couldn’t resist using this to show how simple back-propagation and stochastic gradient descents are. To make sure we leave nothing “under the hood” we will not import anything from the package but rather only copy paste the few things we need. I hope that the text below is generally accessible to anyone familiar with partial derivatives. See this colab notebook for all the code in this tutorial. In particular, aside from libraries for plotting and copy pasting a few dozen lines from Karpathy, this code uses absolutely no libraries (no numpy, no pytorch, etc..) and can train (slowly..) neural networks using stochastic gradient descent. (This notebook builds the code more incrementally.)
Automatic differentiation is a mechanism that allows you to write a Python functions such as
def f(x,y): return (x+y)+x**3
and enables one to automatically obtain the partial derivatives 

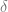

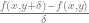
However, if we generalize this approach to 
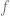
Backpropagation and the chain rule
Back-propagation is a direct implication of the multi-variate chain rule. Let’s illustrate this for the case of two variables. Suppose that 
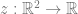

That is, we have the following situation:

where 

Then the chain rule states that
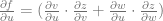
You can take this on faith, but it also has a simple proof. To see the intuition, note that for small 


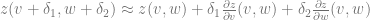
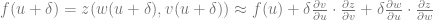
Meaning that 
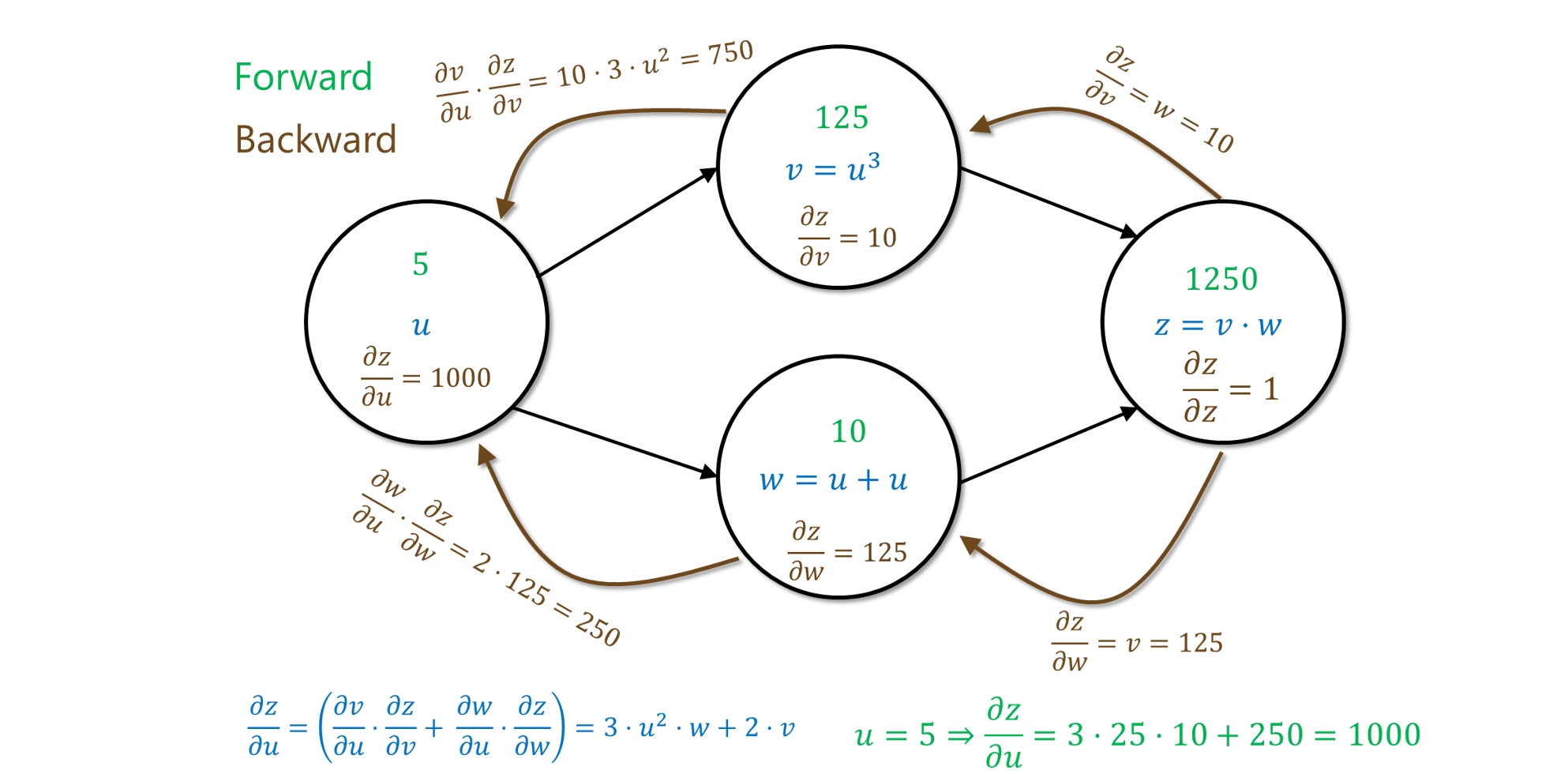
The chain rule generalizes naturally to the case that 





As a corollary, if you already managed to compute the values 
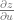
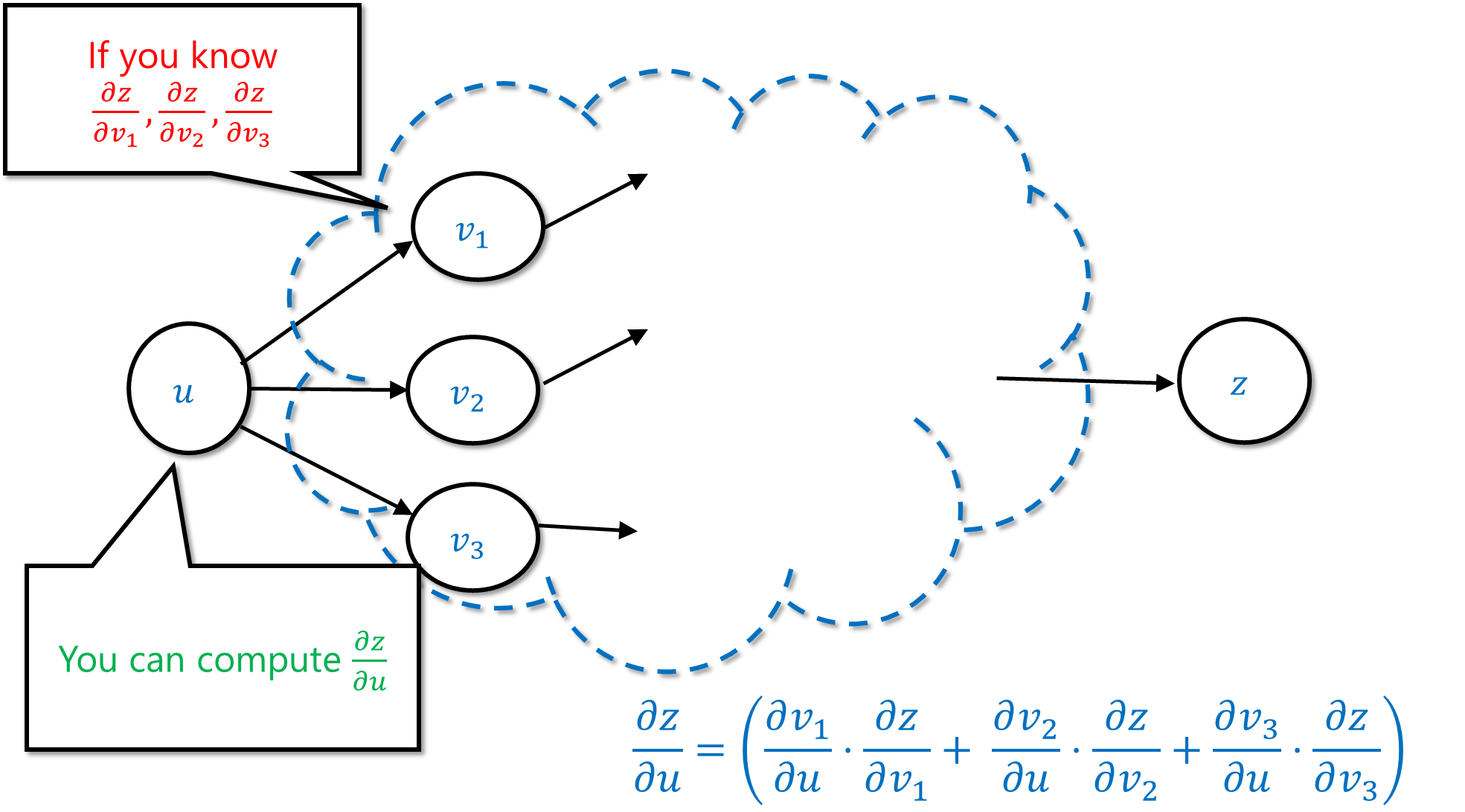
This suggests a simple recursive algorithm by which you compute the derivative of the final value 
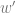
Automatic differentiation via backpropagation
As I describe in my introduction to theoretical computer science text, one can informally define an algorithm as a set of instructions for computing an output from an input by following a sequence of elementary steps. For example, Muhammad ibn Musa al-Khwarizmi (the 9th century Persian scholar on whose name the word “Algorithm” is based) described the algorithm to solve quadratic equations of the form 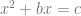

If were were to translate it into Python, al-Khwarizmi’s equation solving procedure is the following:
from math import sqrt
def solve_eq(b,c):
# return solution of x^2 + bx = c following Al Khwarizmi's instructions
# Al Kwarizmi demonstrates this for the case b=10 and c= 39
val1 = b / 2.0 # "halve the number of the roots"
val2 = val1 * val1 # "this you multiply by itself"
val3 = val2 + c # "Add this to thirty-nine"
val4 = sqrt(val3) # "take the root of this"
val5 = val4 - val1 # "subtract from it half the number of roots"
return val5 # "This is the root of the square which you sought for"
The point is that computation of the output from the input is obtained by repeatedly doing the following: compute intermediate values by applying a simple operation to the inputs or previously computed values. The computation graph is the directed acyclic graph with a directed edge from a value u and a value v if u was used in computing v.
The backpropagation algorithm is as follows:
Step 1: Forward Pass
Using the code of 
Step 2: Backward pass
If we let 


Suppose that we have already recursively computed the partial derivative 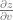
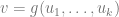
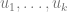
We know the values of 

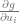
For example, if the function 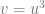
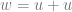


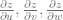 for the assignment using back propagation
for the assignment using back propagationIs Backpropagation “the same as” the chain rule?
The backpropagation algorithm is obtained by repeated applications of the chain rule, and so superficially it might seem that this is the same algorithm for computing derivatives you have learned in your high school or college calculus class. However, it is not the same, a point made by this blog post of Lunjia Hu and also here. The main point is the following.
The approach we have learned in school is to write down the computation 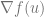

The efficiency gains of backpropagation are particularly dramatic for neural networks where we (1) are typically only interested in the derivative with respect to a single output (the loss) or just few numbers, (2) neurons of intermediate layers are used by many downstream neurons, and so the circuit size is dramatically smaller than the formula size, and (3) the number of inputs
Implementing automatic differentiation using back propagation in Python
We now describe how to do this in Python, following Karpathy’s code. The basic class we use is Value. Every member Value is a container that holds:
- The actual scalar (i.e., floating point) value that
data. - The gradient of
gradand it is initialized to zero. - Pointers to all the values that were used in the computation of
_prev - The method that adds (using the current value of
_backward. Specifically, at the time we call_backwardwe assume thatu.gradalready containsv.gradthe quantity. For the latter quantity we need to keep track of how
- If we call the method
backwards(without an underscore) on a variable_backwardto_backwardon each one and keeping track of the ones we visited (just like in the Depth First Search (DFS) algorithm).
Let’s now describe this in code. We start off with a simple version that only supports addition and multiplication. The constructor for the class is the following:
class Value:
""" stores a single scalar value v
and placeholder for derivative d output/ d v"""
def __init__(self, data, _children=()):
self.data = data
self.grad = 0
self._backward = lambda: None
self._prev = set(_children)
which fairly directly matches the description above. This constructor creates a value without using prior values, which is why the _backward function is empty.
However, we can also create values by adding or multiplying previously computing ones, by adding the following methods:
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data + other.data, (self, other))
def _backward():
self.grad += out.grad
other.grad += out.grad
out._backward = _backward
return out
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data * other.data, (self, other))
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
We can add or multiply a Value object with either another Value object, or a scalar (int or float). In the latter case, we first convert the scalar into a Value object. If we apply an operation op (e.g. addition or multiplication) to two Value objects self and other then the result is a Value object out such that (1) out.data contains op applied to self.data and other.data and (2) out._backward contains the code that will (after out.grad is computed) propagate backward to self.grad and out.grad the contributions of out to the partial derivatives of the final output with respect to self and other.
For example, if we create _backward function of w.grad (which equals 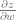
u.grad and v.grad.
If w.grad * v.data (in other words 
u.grad and similarly add w.grad * u.data (
v.grad.
Note that if w is computed as a function of u and v, then to compute the contribution of w to u.grad and w.grad we need to know (1) the partial derivative w.grad and (2) the values of u and v which are stored in u.data and v.data.
The backward function is obtained by setting the gradient of the current value to 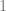
_backwards on all other values in reverse topological order:
def backward(self, visited= None): # slightly shorter code to fit in the blog
if visited is None:
visited= set([self])
self.grad = 1
self._backward()
for child in self._prev:
if not child in visited:
visited.add(child)
child.backward(visited)
For example, if we run the following code
a = Value(5)
def f(x): return (x+2)**2 + x**3
y = f(a)
y.backward()
print(y.data, a.grad)
then the values printed will be 174 and 89 since 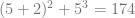

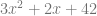
In the notebook you can see that we implement also the power function, and have some “convenience methods” (division etc..).
Linear regression using back propagation and stochastic gradient descent
In stochastic gradient descent we are given some data 
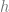



- Set
to be some small number (e.g.,
)
- For
(where
is the number of epochs):
- For
: (in random order)
- Let
- Let

If 
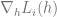
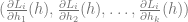
For example, if we want a linear model, we can use 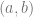
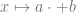
X,Y as follows:

Now we can define a linear model as follows:
class Linear:
def __init__(self):
self.a,self.b = Value(random.random()),Value(random.random())
def __call__(self,x): return self.a*x+self.b
def zero_grad(self):
self.a.grad, self.b.grad = 0,0
And train it directly by using SGD:
η = 0.03, epochs = 20
for t in range(epochs):
for x,y in zip(X,Y):
model.zero_grad()
loss = (model(x)-y)**2
loss.backward()
model.a , model.b = (model.a - η*model.a.grad , model.b - η*model.b.grad)
Which as you can see works very well:

From linear classifiers to Neural Networks.
The above was somewhat of an “overkill” for linear models, but the beauty of automatic differentiation is that we can easily use more complex computation.
We can follow Karpathy’s demo and us the same approach to train a neural network.
We will use a neural network that takes two inputs and has two hidden layers of width 16. A neuron that takes input 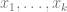



Value class, see the colab notebook. Also we won’t have a bias term in this example.)
The code for this Neural Network is as follows: (when Value() is called without a parameter the value is random number in ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=666666&s=0&c=20201002)
def neuron(weights,inputs, relu =True):
# Evaluate neuron with given weights on given inputs
v = sum(weights[i]*x for i,x in enumerate(inputs))
return v.relu() if relu else v
class Net:
# Depth 3 fully connected neural net with one two inputs and output
def __init__(self, N=16):
self.layer_1 = [[Value(),Value()] for i in range(N)]
self.layer_2 = [ [Value() for j in range(N)] for i in range(N)]
self.output = [ Value() for i in range(N)]
self.parameters = [v for L in [self.layer_1,self.layer_2,[self.output]] for w in L for v in w]
def __call__(self,x):
layer_1_vals = [neuron(w,x) for w in self.layer_1]
layer_2_vals = [neuron(w,layer_1_vals) for w in self.layer_2]
return neuron(self.output,layer_2_vals,relu=False)
# the last output does not have the ReLU on top
def zero_grad(self):
for p in self.parameters:
p.grad=0
We can train it in the same way as above.
We will follow Karpathy and train it to classify the following points:

The training code is very similar, with the following differences:
- Instead of the square loss, we use the function
which is
if
. This makes sense since our data labels will be
and we say we classify correctly if we get the same sign. We get zero loss if we classify correctly all samples with a margin of at least
- Instead of stochastic gradient descent we will do standard gradient descent, using all the datapoints before taking a gradient step. The optimal for neural networks is actually often something in the middle – batch gradient descent where we take a batch of samples and perform the gradient over them.
The resulting code is the following:
for t in range(epochs):
loss = sum([(1+ -y*model(x)).relu() for (x,y) in zip(X,Y)])/len(X)
model.zero_grad()
loss.backward()
for p in model.parameters:
p.data -= η*p.grad
If we use this, we get a decent approximation for this training set (see image below). As Karpathy shows, by adjusting the learning rate and using regularization, one can in fact get 100% accuracy.

Here is an animation demonstrating how training evolves for (a variant of) this net on a different dataset:

Update 11/30: Thanks to Gollamudi Tarakaram for pointing out a typo in a previous version. Update 12/17/21: Significantly extended, inspired by post of Lunjia Hu.

The magic of backpropragation is that it computes all partial derivatives in time proportional to the network size. This is much more efficient than computing derivatives in “forward mode”.
So backprop not only works in practice,it also works in theory! For a reason that I do not understand, researchers on neural networks overemphasized the first point (practical efficiency) to the detriment of the second…
Yes – as mentioned the back propagation algorithm requires only one network evaluation as opposed to n (where n is the number of weights which is basically the size of the network). When I teach introduction to theoretical computer science I often use this as an example of how the difference between an asympotatically quadratic and linear algorithm makes huge difference in practice.
Small remark: the neuron definition before the two moons dataset misses the bias term, this looks to be the reason that the result is not optimal (for the two moons dataset), and not the regularization or the variable step size present in Karpathy’s code.
I think you are right – thanks! I optimized for simplicity rather than expressivity / performance
Passing the set `visited` in recursive calls backwards up the computational graph confused me until I realized sets are passed by reference in python, and not merely copied.