
One of the fascinating lines of research in recent years has been a convergence between the statistical physics and theoretical computer science points of view on optimization problems.
`
This blog post is mainly a note to myself (i.e., I’m the “dummy” 😃), trying to work out some basic facts in some of this line of work. it was inspired by this excellent talk of Eliran Subag, itself part of a great Simons institute workshop which I am still planning to watch the talks of. I am posting this in case it’s useful for others, but this is quite rough, missing many references, and I imagine I have both math mistakes as well as inaccuracies in how I refer to the literature – would be grateful for comments!

In computer science, optimization is the task of finding an assignment 
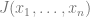


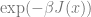
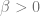
Two prototypical examples of such problems are:
- Random 3SAT – in this case
and
is the number of clauses violated by the assignment
- Sherrington-Kirpatrick model – in this case
and
where
are independent normal variables with variance
for
and variance
for
. (Another way to say it is that
is the matrix
where
‘s entries are chosen i.i.d from
.)
The physics and CS intuition is that these two problems have very different computational properties. For random 3SAT (of the appropriate density), it is believed that the set of solutions is “shattered” in the sense that it is partitioned to exponentially many clusters, separated from one another by large distance. It is conjectured that in this setting the problem will be computationally hard. Similarly from the statistical physics point of view, it is conjectured that if we were to start with the uniform distribution (i.e., a “hot” system) and “lower the temperature” (increase 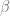
In contrast for the Sherrington-Kirpatrick (SK) model, the geometry is more subtle, but interestingly this enables better algorithms. The SK model is extermely widely studied, with hundreds of papers, and was the inspiration for the simulated annealing algorithm. If memory serves me right, Sherrington and Kirpatrick made the wrong conjecture on the energy of the ground state, and then Parisi came up in 1979 with a wonderful and hugely influential way to compute this value. Parisi’s calculation was heuristic, but about 30 years later, first Talagrand and later Panchenko proved rigorously many of Parisi’s conjectures. (See this survey of Panchenko.)
Recently Montanari gave a polynomial time algorithm to find a state with energy that is arbitrarily close to the ground state’s. The algorithm relies on Parisi’s framework and in particular on the fact that the solution space has a property known as “full replica symmetry breaking (RSB)” / “ultrametricity”. Parisi’s derivations (and hence also Montanari’s analysis) are highly elaborate and I admit that I have not yet been able to fully follow it. The nice thing is that (as we’ll see) it is possible to describe at least some of the algorithmic results without going into this theory. In the end of the post I will discuss a bit some of the relation to this theory, which is the underlying inspiration for Subag’s results described here.
Note: These papers and this blog post deal with the search problem of finding a solution that minimizes the objective. The refutation problem of certifying that this minimum is at least 




Analysis of a simpler setting
Luckily, there is a similar computational problem, for which the analysis of analogous algorithm, which was discovered by Subag and was the partial inspiration for Montanari’s work, is much simpler. Specifically, we consider the case where 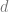







Depending on 


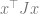



These calculations also give rise to the following theorem:
Theorem (Chen and Sen, Proposition 2): If 
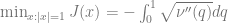

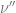
We will not discuss the proof of this theorem, but rather how, taking it as a black box, it leads to an algorithm for minimizing
It is a nice exercise to show that for every two vectors 
![\mathbb{E}_J [J(x)J(x')] = \nu(\langle x,x' \rangle)/n](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_J+%5BJ%28x%29J%28x%27%29%5D+%3D+%5Cnu%28%5Clangle+x%2Cx%27+%5Crangle%29%2Fn&bg=ffffff&fg=666666&s=0&c=20201002)



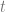
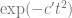

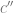
To get a better sense for the quantity 
- If
(i.e.,
for random matrix
) then
and
, meaning that
. This turns out to be the actual minimum value. Indeed in this case
. But the matrix
‘s non diagonal entries are distributed like
and the diagonal entries like
which means that
times a random matrix
from the Gaussian Orthogonal Ensemble (GOE) where
for off diagonal entries and
for diagonal entries. The minimum eigenvalue of such matrices is known to be
with high probability.
- If
(i.e.
for a random
) then
for large
with
While the particular form of the property 
![(0,1]](https://s0.wp.com/latex.php?latex=%280%2C1%5D&bg=ffffff&fg=666666&s=0&c=20201002)
It can be shown that this condition cannot be satisfied if 

The central result of Subag’s paper is the following:
Theorem: For every 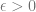

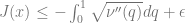
The algorithm itself, and the idea behind the analysis are quite simple. In some sense it’s the second algorithm you would think of (or at least the second algorithm according to some ordering).
The first algorithm one would think of is gradient descent. We start at some initial point 


The second algorithm one could think of would be to use the Hessian instead of the gradient. That is, repeat the transformation 


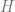

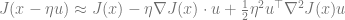

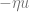
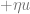
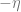
The above approach is promising, but we still need some control over the norm. The way that Subag handles this is that he starts with 

Algorithm:
Input: 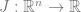
Goal: Find unit
- Initialize
- For
: i. Let
be a unit vector
and
. (Since the bottom eigenspace of
.) ii. Set
.
- Output


(The fact that the number of steps is 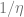
If we define 

Now due to rotation invariance, the distribution of 

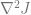


Since 

where 

Taking

and hence the result will be completed by showing that
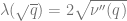
To do this, let’s recall the definition of
For simplicity, let’s assume that 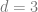
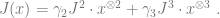
(The calculations in the general case are similar)
The 






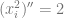
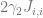

The contribution from the 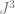



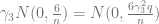

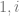


(More generally, for larger 


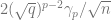
Since the sum of Gaussians is a Gaussian we get that 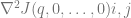


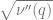


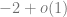
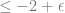

Full replica symmetry breaking and ultra-metricity
The point of this blog post is that at least in the “mixed
The key object studied in this line of work is the probability distribution 
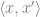
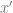
Intuitively, there are several ways this probability distribution can behave, depending on how the solution space is “clustered”:
- If all solutions are inside a single “cluster”, in the sense that they are all of the form
where
is the “center” of the cluster and
is some random vector, then
.
- If the solutions are inside a finite number
of clusters, with centers
, then the support of the distribution will be on the
points
.
- Suppose that the solutions are inside a hierarchy of clusters. That is, suppose we have some rooted tree
(e.g., think of a depth
with every vertex
of
for all vertices
and
will be
taken over all the common ancestors of
) that is known as full replica symmetry breaking. Because the dot product is determined by common ancestor, for every three vectors
in the support of the distribution
or
. It is this condition that known as ultra-metricity.
In Subag’s algorithm, as mentioned above, at any given step we could make an update of either 

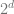
Acknowledgements: Thanks to Tselil Schramm for helpful comments.
