[Jelani Nelson is organizing a post-STOC workshop on Chaining Methods and their applications, and agreed to write a 2-post series about these methods here. –Boaz]
1. Workshop details
Assaf Naor and I (Jelani Nelson) are organizing a two-day workshop “Chaining Methods and their Applications to Computer Science (CMACS)” June 22–23, 2016, immediately after STOC 2016. It will be held on the Harvard campus. Registration for CMACS is free, and the link can be found on the workshop’s website. Thanks to the NSF, there is some funding to support postdoc and student attendance, so if you fall into one of these two categories then please check off the appropriate box during registration. Also see the instructions on the website for how to apply for this support.
2. What is chaining?
Consider the problem of bounding the maximum of a collection of random variables. That is, we have some collection 
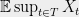

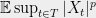
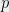
Such problems show up all the time in probabilistic analyses, including in computer science, and the most common approach is to combine tail bounds with union bounds. For example, to show that the maximum load when throwing 





Most succinctly, chaining methods leverage statistical dependencies between a (possibly infinite) collection of random variables in order to beat this naive union bound.
The origins of chaining began with Kolmogorov’s continuity theorem from the 1930s (see Section 2.2, Theorem 2.8 of [KS91]). The point of this theorem was to understand conditions under which a stochastic process is continuous. That is, consider a random function 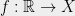

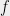


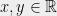


Since Kolmogorov’s work, the scope of applications of the chaining methodology has widened tremendously, due to contributions of many mathematicians, including Dudley, Fernique, and very notably Talagrand. See Talagrand’s treatise [Tal14] for a description of many impressive applications of chaining in mathematics. See also Talagrand’s STOC 2010 paper [Tal10]. Note that [Tal14] is not exhaustive, and additional applications are posted on the arxiv on a regular basis.
3. Applications in computer science
Several applications are given in Section 1.2.2 of [vH14]. I will repeat some of those here, as well as some other ones.
Random matrices and compressed sensing: Consider a random matrix 
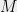



Understanding singular values of random matrices has been important in several areas of computer science. Close to my own heart are in compressed sensing and randomized linear algebra algorithms. For the latter, a relevant object is a subspace embedding; these are objects used in algorithms for fast regression, low-rank approximation, and a dozen other applications (see [Woo14]). Analyses then boil down to understanding the largest singular value of 


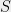
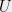
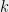
Empirical risk minimization: (Example taken from [vH14]). In machine learning one often is given some data, drawn from some unknown distribution, and a loss function 
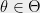


The expectation is taken over the distribution of 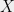

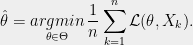
We would like to argue that 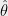


Dimensionality reduction: In Euclidean dimensionality reduction, such as in the Johnson-Lindenstrauss lemma, one is given a set of vectors 
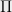
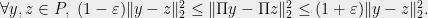
This is satisfied as long as 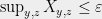

where 




Another application of chaining in the context dimensionality reduction was in regard to nearest neighbor (NN) preserving embeddings [IN07]. In this problem, one is given a database 
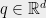



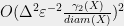
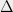
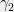

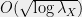

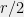
ball, over all 
Data structures and streaming algorithms: The potential example to data structures was already mentioned in the previous section. To make it more concrete, consider the following streaming data structural problem in which one sees a sequence 


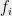
![{i\in[n]}](https://s0.wp.com/latex.php?latex=%7Bi%5Cin%5Bn%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
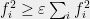


A recent work of [BCIW16] provides a new algorithm that solves the same problem using only 
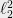
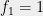
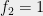


Random walks on graphs: Ding, Lee, and Peres [DLP12] a few years ago gave the first deterministic constant-factor approximation algorithm to the cover time of a random graph (see James Lee’s blog post). Their work showed that the cover time of any connected graph is, up to a constant, equal to the supremum of a certain collection of random variables depending on that graph, the gaussian free field. Essentially this is a collection of gaussian random variables whose covariance structure is given by the effective resistances between vertices in the graph. Work of Talagrand (the “majorizing measures theory”) and Fernique have provided us with tight, up to a constant factor, upper and lower bounds for the expected supremum of a collection of random variables. Furthermore, these bounds are constructive and efficient. See also the works [Mek12,Din14,Zha14] for more on this topic.
Dictionary learning: In dictionary learning one assumes that some data of 
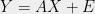



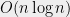
It was recently shown that their precise algorithm needs roughly 
Error-correcting codes: A 
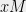





Recent work of Rudra and Wootters [RW14] showed, to quote them, that any random puncturing” means simply to randomly sample some number of columns of 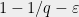

In the next post we’ll get more into how chaining works and also play with a toy example. In the meantime, you might also want to see these three blog posts by James Lee back in 2010 (or in pdf form).
Bibliography
[Ada16] Radosław Adamczak. A note on the sample complexity of the Er-SpUD algorithm by Spielman, Wang and Wright for exact recovery of sparsely used dictionaries. CoRR, abs/1601.02049, 2016.
[AL13] Nir Ailon and Edo Liberty. An almost optimal unrestricted fast Johnson-Lindenstrauss transform. ACM Transactions on Algorithms, 9(3):21, 2013.
[BCIW16] Vladimir Braverman, Stephen~R. Chestnut, Nikita Ivkin, and David~P. Woodruff. Beating CountSketch for Heavy Hitters in Insertion Streams. In Proceedings of the 48th Annual ACM Symposium on Theory of Computing (STOC), to appear, 2016. Full version at arXiv abs/1511.00661.
[BDN15] Jean Bourgain, Sjoerd Dirksen, and Jelani Nelson. Toward a unified theory of sparse dimensionality reduction in Euclidean space. Geometric and Functional Analysis (GAFA), 25(4):1009–1088, July 2015. Preliminary version in STOC 2015.
[BN16] Jarosław Błasiok and Jelani Nelson. An improved analysis of the ER-SpUD dictionary learning algorithm. CoRR, abs/1602.05719, 2016.
[Din14] Jian Ding. Asymptotics of cover times via Gaussian free fields: Bounded-degree graphs and general trees. Annals of Probability, 42(2):464–496, 2014.
[Dir15] Sjoerd Dirksen. Dimensionality reduction with subgaussian matrices: a unified theory. Found. Comp. Math., pages 1–30, 2015.
[DLP12] Jian Ding, James~R. Lee, and Yuval Peres. Cover times, blanket times, and majorizing measures. Annals of Mathematics, 175:1409–1471, 2012.
[Gor88] Yehoram Gordon. On Milman’s inequality and random subspaces which escape through a mesh in 
[IN07] Piotr Indyk and Assaf Naor. Nearest-neighbor-preserving embeddings. ACM Transactions on Algorithms, 3(3), 2007.
[KM05] Bo’az Klartag and Shahar Mendelson. Empirical processes and random projections. J. Funct. Anal., 225(1):229–245, 2005.
[LV15] Kyle Luh and Van Vu. Random matrices: 
[Mek12] Raghu Meka. A PTAS for computing the supremum of gaussian processes. In 53rd Annual IEEE Symposium on Foundations of Computer Science (FOCS), pages 217–222, 2012.
[MPTJ07] Shahar Mendelson, Alain Pajor, and Nicole Tomczak-Jaegermann. Reconstruction and subgaussian operators in asymptotic geometric analysis. Geometric and Functional Analysis, 17:1248–1282, 2007.
[ORS15] Samet Oymak, Benjamin Recht, and Mahdi Soltanolkotabi. Isometric sketching of any set via the restricted isometry property. CoRR, abs/1506.03521, 2015.
[RW14] Atri Rudra and Mary Wootters. Every list-decodable code for high noise has abundant near-optimal rate puncturings. In Proceedings of the 46th ACM Symposium on Theory of Computing (STOC), pages 764–773, 2014.
[SWW12] Daniel A. Spielman, Huan Wang, and John Wright. Exact recovery of sparsely-used dictionaries. In Proceedings of the 25th Annual Conference on Learning Theory (COLT), pages 37.1–37.18, 2012.
[Tal10] Michel Talagrand. Are many small sets explicitly small? In Proceedings of the 42nd ACM Symposium on Theory of Computing (STOC), pages 13–36, 2010.
[Tal14] Michel Talagrand. Upper and lower bounds for stochastic processes: modern methods and classical problems. Springer, 2014.
[vH14] Ramon van Handel. Probability in high dimensions. Manuscript, 2014. Available here. Version from June 30, 2014.
[Woo14] David P. Woodruff. Sketching as a tool for numerical linear algebra. Foundations and Trends in Theoretical Computer Science, 10(1-2):1–157, 2014.
[Zha14] Alex Zhai. Exponential concentration of cover times. CoRR, abs/1407.7617, 2014.

Note that your definition of “dictionary learning” involves a restricted version of the problem, whereas the one usually of interest in machine learning and neuroscience involves overcomplete bases. The number of vectors is more than the dimension. (You may be aware of this but your readers won’t be.)
This line of work can’t be generalized to that case.
“Note that your definition of …”
I think you misread what I wrote. In my definition I made no such assumption. In the next sentence I stated that under two restrictions (i.e. no noise and square A), these algorithms I cited get blah.
I agree the problem isn’t solved. There are several axes to measure progress on: handling noise or not, overcomplete A or not, sample complexity, running time, general A or not, how restrictive is the random model for X, etc. The line of work I cited does the best on sample complexity, but some of the other parameters are not so great. Your work and others handle noise and overcomplete A, but the sample complexity isn’t as good. The holy grail is to get everything to be awesome, which as I see it is an open problem. Anyway, we go into this in more detail in the intro in the paper I cited with Jarek.
Actually even for the overcomplete dictionaries it was already shown how to analyze the alternating minimization heuristic (under some probabilistic assumptions on the data) where the sample complexity is near-optimal. http://arxiv.org/pdf/1503.00778v1.pdf (COLT’14)
Oops; it was COLT’15, not COLT’14.
Thanks for the reference. But why do you label this as nearly optimal sample complexity? The sample complexity in the paper you linked is O~(mk), where k is the column sparsity of X (that is, you observe Y = AX + noise, and each column of X is k-sparse). Note in the complete case (m = n) with no noise, for k = sqrt(n) your bound is n^{3/2} samples. Meanwhile the right answer for noiseless/complete for k <= sqrt(n) is that you only need O~(n) samples. It seems to me that the sample complexity in the paper you linked is only nearly optimal for the very low sparsity regime.