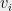In the previous posts we talked about various discrepancy questions and saw a proof of the six standard deviations suffice result. Besides being of interest in combinatorics, discrepancy theory has several remarkable applications in algorithms. Check this excellent book for a taste of these results. Here I will briefly discuss two (one old and one new) such results:
- Rounding linear programs by discrepancy theory: specifically, the beautiful argument of Lovasz, Spencer and Vesztergombi (LSV) on bounding linear discrepancy in terms of hereditary discrepancy. LSV is also an excellent place to look if you are running short on beautiful, innocent-in-appearance, time-sinking combinatorial conjectures.
Unfortunately, to keep the post short (-er), I will not discuss the recent breakthrough result of Rothvoss on bin-packing which uses discrepancy theory (in a much more sophisticated) for rounding a well-studied linear program (the “Gilmore-Gomory” LP). I highly recommend reading the paper.
- A recent algorithmic proof of Spencer/Gluskin theorem due to Shachar Lovett and myself.
Rounding Linear Programs One of the most basic techniques for combinatorial optimization is linear programming relaxation. Let us phrase this in a language suitable for the present context (which is in fact fairly generic). We have a constraint matrix 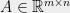

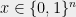

![\displaystyle \min_{y \in [0,1]^n} \|Ay - b\|_\infty \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cmin_%7By+%5Cin+%5B0%2C1%5D%5En%7D+%5C%7CAy+-+b%5C%7C_%5Cinfty+%5C+%5C+%5C+%5C+%5C+%281%29&bg=eeeeee&fg=000000&s=0&c=20201002)
(which can be done efficiently). The next step, and often the most challenging one, is to round the fractional solution ![{y \in [0,1]^n}](https://s0.wp.com/latex.php?latex=%7By+%5Cin+%5B0%2C1%5D%5En%7D&bg=eeeeee&fg=000000&s=0&c=20201002)


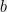
![\displaystyle lindisc(A) = \max_{y \in [0,1]^n} \min_{x \in \{0,1\}^n} \|Ax - Ay\|_\infty. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++lindisc%28A%29+%3D+%5Cmax_%7By+%5Cin+%5B0%2C1%5D%5En%7D+%5Cmin_%7Bx+%5Cin+%5C%7B0%2C1%5C%7D%5En%7D+%5C%7CAx+-+Ay%5C%7C_%5Cinfty.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=eeeeee&fg=000000&s=0&c=20201002)
LSV introduced the above notion originally as a generalization of discrepancy which can be formulated in our current context as follows:

This corresponds exactly to the notion of discrepancy we studied in the last two posts. On the other hand, we can also write 

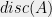
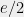
The remarkable result of LSV is that while the above definition seems to be much weaker than 

![{S \subseteq [n]}](https://s0.wp.com/latex.php?latex=%7BS+%5Csubseteq+%5Bn%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
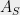

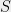
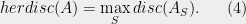
Hereditary discrepancy is a natural and more “robust” version of discrepancy. As LSV phrase it, discrepancy can be small by accident, whereas hereditary discrepancy seems to carry more structural information. For example, let 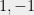
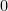
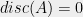
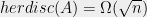
It is also worth noting that several notable results in discrepancy theory which bound the discrepancy in fact also bound hereditary discrepancy. For example, Spencer’s original proof as well as Gluskin’s argument from last post (with a little bit more work) in fact show the following:
![{A \in [-1,1]^{n \times n}}](https://s0.wp.com/latex.php?latex=%7BA+%5Cin+%5B-1%2C1%5D%5E%7Bn+%5Ctimes+n%7D%7D&bg=eeeeee&fg=000000&s=0&c=20201002) ,
,  .
. LSV show the following connection between linear and hereditary discrepancies:
Theorem 2 For any matrix
.
In other words, any fractional solution for a linear program of the form Equation 1 can be rounded to a integer solution with an additive error of at most 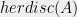
Let me now describe the cute proof which can be explained in a few lines. Suppose you have a fractional solution 

![{i \in [n]}](https://s0.wp.com/latex.php?latex=%7Bi+%5Cin+%5Bn%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)

We will build a sequence of solutions 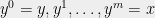
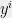

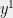
Let ![{S = \{i \in [n] : y_{im} = 1\}}](https://s0.wp.com/latex.php?latex=%7BS+%3D+%5C%7Bi+%5Cin+%5Bn%5D+%3A+y_%7Bim%7D+%3D+1%5C%7D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)







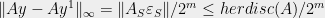

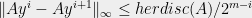

Constructive Discrepancy Minimization by Walking on the Edges We just saw a way to round linear programs as in Equation 1 with error bounded by their discrepancy. As appealing as this is, it comes with one important caveat. The original motivation for looking at LP relaxations was that we can solve them efficiently. For this to make sense, we need the rounding procedure to be efficient as well. In our present case, to make the rounding efficient, we need to find a small discrepancy solution efficiently (find 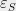
However, what about specific bounds like in Theorem 1? Spencer’s original proof as well as Gluskin’s proof do not give an efficient algorithm for finding a good coloring. This is fundamentally inherent with the two arguments: they rely (directly or indirectly via Minkowski’s theorem) on the pigeon-hole principle (with exponentially many “holes”) which is quite non-algorithmic. In fact, Alon and Spencer conjectured (in `the’ book) several years ago that finding a coloring with discrepancy 
Fortunately for us, like all good conjectures, this was proven to be false by a breakthrough result of Nikhil Bansal. Nikhil’s argument studies a carefully constructed semi-definite programming relaxation of the problem and then gives a new and amazing rounding algorithm for the SDP.
Here I will briefly discuss a different proof of Theorem 1 due to Lovett and myself which will also lead to an efficient algorithm for finding a coloring as required.
Let us first revisit Beck’s partial-coloring approach described in last post which says that to prove the theorem, it suffices to show the following.
Lemma 3 For vectors
, there exists
such that for every
,
and
.
As in the last post, let us also rephrase the problem in a geometric language. Let 



![\displaystyle \mathcal{K} = \{\;x\,:\, |\langle a^j,x\rangle| \leq \Delta, \forall j \in [n] \;\;\;\;\;\;\;\;\text{ (call these \emph{discrepancy} constraints)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathcal%7BK%7D+%3D+%5C%7B%5C%3Bx%5C%2C%3A%5C%2C+%7C%5Clangle+a%5Ej%2Cx%5Crangle%7C+%5Cleq+%5CDelta%2C+%5Cforall+j+%5Cin+%5Bn%5D+%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5Ctext%7B+%28call+these+%5Cemph%7Bdiscrepancy%7D+constraints%29%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \;\;\;\;\;\;\;\;\; |x_i| \leq 1, \forall i \in [n]\;\} \;\;\;\;\;\;\;\;\text{ (call these \emph{coloring} constraints)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B+%7Cx_i%7C+%5Cleq+1%2C+%5Cforall+i+%5Cin+%5Bn%5D%5C%3B%5C%7D+%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5Ctext%7B+%28call+these+%5Cemph%7Bcoloring%7D+constraints%29%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
The partial coloring lemma is equivalent to showing that 


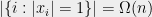 .
.
The above is equivalent to finding a vertex of 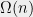
Let us think of trying to find the vertex
Now, in the course of performing this random walk at some time we will touch the boundary of 
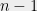
This is pretty much the actual algorithm which we call the Edge-Walk algorithm (except that to make it implementable we take tiny Gaussian random steps instead of doing Brownian motion; and this makes the analysis easier too). I will refer to the paper for the full details of the algorithm and its analysis, but let me just say what the punchline is: you are more likely to hit nearer constraints than farther ones.
Before moving on, note that the Edge-Walk algorithm can be defined for any polytope
Discussion This concludes the three post series. Perhaps, sometime in the future there will be other posts on other notable results in discrepancy theory (like the Beck-Fiala theorem). Keeping with the trend from the last two posts, let me end with another open question which strengthens Theorem 1 in a strong way:
Komlos Conjecture Given unit vectors
, there exists
such that

Theorem 1 follows from the above if we take