In this series of three posts I want to discuss some recent and old advances in discrepancy theory and their applications to algorithms. Discrepancy minimization is quite a rich and beautiful area as evidenced in these two books. Here I will focus on a specific perspective — that of “Beating the Union Bound” — which while being limiting captures the main issues in the examples and applications we consider. The description below is particularly efficient in hiding the main combinatorial motivations for the questions in discrepancy theory, but hopefully we will makeup for it by other means.
As a preview of what’s to come, in the next post I will discuss Gluskin’s geometric approach to proving the `Six Standard Deviations Suffice’ theorem (Theorem 1 below, but with a constant different from 
We all know what the union bound is. But if you don’t, here’s how the well-known mathematical genius S. Holmes described it: “When you have eliminated the impossible, whatever remains, however improbable, must be the truth”. In non-sleuth terms this says that if you have arbitrary events 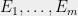
![\displaystyle {Pr[E_1 \cup E_2 \cup \cdots \cup E_m] \leq Pr[E_1] + \cdots + Pr[E_m]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7BPr%5BE_1+%5Ccup+E_2+%5Ccup+%5Ccdots+%5Ccup+E_m%5D+%5Cleq+Pr%5BE_1%5D+%2B+%5Ccdots+%2B+Pr%5BE_m%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
In particular, if the latter sum is less than 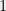
By now, we have seen several strangely simple and powerful applications of this simple precept – e.g., existence of good Ramsey graphs (Erdős), existence of good error correcting codes (Shannon), existence of good metric embeddings (Johnson-Lindenstrauss). And the union bound and further variants of it are one of the main techniques we have for showing existential results.
However, the union bound is indeed quite naive in many important contexts and is not always enough to get what we want (as nothing seems to be these days). One particularly striking example of this is the Lovász local lemma (LLL). But let us not digress along this (beautiful) path. Here we will discuss how “beating” the union bound can lead to some important results in the context of discrepancy theory.
Discrepancy and Beating the Union Bound: Six Suffice A basic probabilistic inequality which we use day-in and day-out is the Chernoff bound. The special case of interest to us is the following: for any vector 

![\displaystyle Pr_{\epsilon \sim \{1,-1\}^n}\left[\left|\sum_i \epsilon_i a_i\right| > t \sqrt{n}\right] \leq 2 \exp(-t^2/2). \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr_%7B%5Cepsilon+%5Csim+%5C%7B1%2C-1%5C%7D%5En%7D%5Cleft%5B%5Cleft%7C%5Csum_i+%5Cepsilon_i+a_i%5Cright%7C+%3E+t+%5Csqrt%7Bn%7D%5Cright%5D+%5Cleq+2+%5Cexp%28-t%5E2%2F2%29.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=eeeeee&fg=000000&s=0&c=20201002)
In words, the probability that the sum 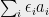

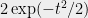

![\displaystyle Pr_{\epsilon \sim \{1,-1\}^n}\left[\exists j \in [n],\; \left|\sum_{i=1}^n \epsilon_i a^j_i\right| > t\sqrt{n}\right] \leq 2 n \exp(-t^2/2). \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr_%7B%5Cepsilon+%5Csim+%5C%7B1%2C-1%5C%7D%5En%7D%5Cleft%5B%5Cexists+j+%5Cin+%5Bn%5D%2C%5C%3B+%5Cleft%7C%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i+a%5Ej_i%5Cright%7C+%3E+t%5Csqrt%7Bn%7D%5Cright%5D+%5Cleq+2+n+%5Cexp%28-t%5E2%2F2%29.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=eeeeee&fg=000000&s=0&c=20201002)
In particular, if we choose 

![{j \in [n]}](https://s0.wp.com/latex.php?latex=%7Bj+%5Cin+%5Bn%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)

Theorem 1 For all
, vectors
.
We will see a proof of the theorem in the next post.
Discrepancy and Beating the Union Bound (and some): Paving Conjecture As discussed in this post a few months back, the stunning result (adjective is mine) of Adam Marcus, Daniel Spielman and Nikhil Srivastava proving the paving conjecture (and hence resolving the Kadison-Singer problem) can also be cast in a discrepancy language. Let me repeat this from Nikhil’s post for completeness. Let us look at a specific variant of the ‘Matrix Chernoff Bound’ (see Nikhil’s post for references; here 
Theorem 2 Given symmetric matrices
,
![\displaystyle Pr_{\epsilon \sim \{1,-1\}^m}\left[\left\|\sum_{i=1}^m \epsilon_i A_i\right\| \geq t \left\|\sum_{i=1}^m A_i^2\right\|^{1/2}\right] \leq 2 n \exp(-t^2/2).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr_%7B%5Cepsilon+%5Csim+%5C%7B1%2C-1%5C%7D%5Em%7D%5Cleft%5B%5Cleft%5C%7C%5Csum_%7Bi%3D1%7D%5Em+%5Cepsilon_i+A_i%5Cright%5C%7C+%5Cgeq+t+%5Cleft%5C%7C%5Csum_%7Bi%3D1%7D%5Em+A_i%5E2%5Cright%5C%7C%5E%7B1%2F2%7D%5Cright%5D+%5Cleq+2+n+%5Cexp%28-t%5E2%2F2%29.&bg=eeeeee&fg=666666&s=0&c=20201002)
Note that the above is a substantial generalization of Equation 2 which corresponds to the special case when the matrices 
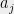

An implication of the above theorem is that for symmetric matrices 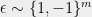

Just as for the scalar case, the 
- Question 1: Can the
- Question 2: Can the
‘s?
Here we will focus on the first question, but let me say a couple of words about the second one. In all known examples showing tightness of the matrix Chernoff bound, the matrices 
Regarding the first question, Spencer’s theorem gives a positive answer in the special case when 
Discrepancy and Beating the Union: Matrix Spencer Theorem? The above discussions prompt the following question:
Conjecture For any symmetric matrices
with
, there exist signs
such that
.
The above conjecture is a strong generalization of Spencer’s theorem which corresponds to the matrices
One can view the conjecture as giving a partial answer to Question 1. In the case when 


In the next post, I will discuss Gluskin’s proof of Theorem 1, which for now (to me) seems to be the most promising approach for proving the conjecture.
Acknowledgments
Thanks to Shachar Lovett, Oded Regev and Nikhil Srivastava for helpful suggestions, comments, and corrections during the preparation of this post.

Hi,
Isn’t there a typo in the statement of Theorem 2? (namely, $i$ ranges from $1$ to $m$, yet $\epsilon$ has only $n$ coordinates; $\epsilon_i$ can only have $i\in[n]$).
Thanks; corrected the typo.
Thank you Raghu – looking forward to see the proof.
Should there be A_i^2 inside the norm of the conjecture? Also, is it a “sum of norms” or a “norm of sums”? I have to say that I don’t have good intuition as to when we should expect a bound with the latter form and when we cannot improve on the former.
The question is probably as interesting with A_i^2 inside the norm, but it probably shouldn’t make much of a difference in terms of its validity.
I don’t have good intuition either, but my guess would be that for sums of independent random matrices, in most cases the stronger ”norm of sums” bound will likely hold. For dependent sums, things may fail quite badly however.
Hi Raghu,
I guess I can just wait and see, but I am curious: are you going for Gluskin’s proof (via Minkowski’s theorem), or the Giannopoulos version of the proof?
To kill the surprise … I’m planning to follow Gluskin’s original proof.
Looking forward!