Today, we have a guest post from Frank McSherry talking about a clever approach to using Differential Privacy for handling pesky dependencies that get in the way of proving measure concentration results.
———————
In this post I’ll explain a cute use of differential privacy as a tool in probabilistic analysis. This is a great example of differential privacy being useful for something other than privacy itself, although there are other good examples too. The main problem we’ll be looking at is the analysis of mostly independent random variables, through the lens of a clustering problem I worked on many years ago.
In the problem of clustering data drawn from a Gaussian mixture, you assume that you are provided access to a large volume of data each of which is a sample from one of a few high-dimensional Gaussian distributions. Each of the Gaussian distributions are determined by a mean vector and a co-variance matrix, and each Gaussian has a mixing weight describing their relative fraction of the overall population of samples. There are a few goals you might have from such a collection of data, but the one we are going to look at is the task of clustering the data into parts corresponding to the Gaussian distributions from which they were drawn. Under what conditions on the Gaussians is such a thing possible? [please note: this work is a bit old, and does not reflect state of the art results in the area; rather, we are using it to highlight the super-cool use of differential privacy].
The main problem is that while each coordinate of a Gaussian distribution is concentrated, there are some large number 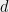

![\displaystyle Pr [ | x - \mu |_2^2 \gg d \cdot \sigma^2 ] \le \delta \; ,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr+%5B+%7C+x+-+%5Cmu+%7C_2%5E2+%5Cgg+d+%5Ccdot+%5Csigma%5E2+%5D+%5Cle+%5Cdelta+%5C%3B+%2C+&bg=eeeeee&fg=000000&s=0&c=20201002)
where 

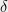
Dimitris Achlioptas and I had an algorithm for doing this based on spectral projections: we would find the optimal low-rank subspace determined by the singular value decomposition (the rank taken to be 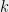

![\displaystyle Pr [ |P x - \mu |_2^2 \gg k \cdot \tau^2 ] \le \delta \; ,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr+%5B+%7CP+x+-+%5Cmu+%7C_2%5E2+%5Cgg+k+%5Ccdot+%5Ctau%5E2+%5D+%5Cle+%5Cdelta+%5C%3B+%2C+&bg=eeeeee&fg=000000&s=0&c=20201002)
where 

The problem is that this “more-or-less vanishes” thing is really only true when the target space and the random noise are independent. However, since the optimal low-rank subspace was determined from the data, it isn’t independent of any of the noise we are projecting. It’s slightly dependent on the noise, and in the wrong way (it attempts to accomodate the noise, which isn’t what we want if we want to project *out* the noise). In particular, you don’t immediately get access to the sorts of bounds above.
You could do things the way Dimitris and I did, which was a fairly complicated mess of cross-training (randomly partition the data and use each half to determine the subspace for the other), and you end up with a paper that spends most of its time determining algorithms and notation to enforce the independence (the cross-training needs to be done recursively, but we can’t afford to cut the samples in half at each level, blah blah, brain explodes). You can read all about it here. We’re going to do things a bit simpler now.
Enter differential privacy. Recall, for a moment, the informal statement of differential privacy: a randomized computation has differential privacy if the probability of any output occurrence is not substantially adjusted when a single input element is added or removed. What a nice privacy definition!
Now, let’s think of it slightly differently, in terms of dependence and independence. If 
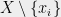
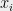

For example, let’s consider the probability of the property: “the squared length of the projection of 


![\displaystyle Pr [ | P_i x_i - \mu |_2^2 \gg k \cdot \tau^2 ] < \delta \; .](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr+%5B+%7C+P_i+x_i+-+%5Cmu+%7C_2%5E2+%5Cgg+k+%5Ccdot+%5Ctau%5E2+%5D+%3C+%5Cdelta+%5C%3B+.+&bg=eeeeee&fg=000000&s=0&c=20201002)
When the input data are 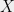

![\displaystyle Pr [ | P x_i - \mu |_2^2 \gg k \cdot \tau^2 ] < \exp(\epsilon) \times \delta \; .](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Pr+%5B+%7C+P+x_i+-+%5Cmu+%7C_2%5E2+%5Cgg+k+%5Ccdot+%5Ctau%5E2+%5D+%3C+%5Cexp%28%5Cepsilon%29+%5Ctimes+%5Cdelta+%5C%3B+.+&bg=eeeeee&fg=000000&s=0&c=20201002)
We can even live with fairly beefy values of 
Now let’s discuss differentially private optimal subspace computation. One standard way to compute optimal low dimensional subspaces is by taking the covariance matrix of the data and computing its top singular vectors, using the singular value decomposition. One standard way to release the covariance matrix while preserving differential privacy is to add Laplace noise proportional to the largest magnitude permitted of any of the data points, to each of the entries of the covariance matrix. Since our Gaussian data are nicely concentrated, they aren’t likely to be terribly enormous, and a data-independent upper bound will work great here.
What we get is a noisy covariance matrix, which we then subject to the singular value decomposition. There are some nice theorems about how the SVD is robust in the presence of noise, which is actually the same reason it is used as a tool to filter out all of that noise that the Gaussian distributions added in in the first place. So, even though we added a bunch of noise to the covariance matrix, we still get a fairly decent approximation to the space spanned by the means of the Gaussian distributions (as long as the number of samples is larger than the dimensionality of the samples). At the same time, because the resulting subspace is differentially private with respect to the samples, we can still use the concentration bounds typically reserved for the projection of random noise on independent subspaces, as long as we can absorb a factor of
At its heart, this problem was about recovering a tenuous independence which was very important for simplicity (and arguably tractability) of analysis. It shows up in lots of learning problems, especially in validating models: we would typically split data into test and training, to permit an evaluation of learned results without the issue of overfitting. Here differential privacy makes things simpler: if your learning process is differentially private, you did not overfit your data (much).

Very neat! Maybe we need a survey of things (beside privacy) one can accomplish with differential privacy.