This week’s post touches on subjects spanning almost 2000 years — we start with a cryptographic problem and go back in time to discover a theorem that could be known to the Greeks. Its content is based on a paper co-authored with Anton Mityagin and Kobbi Nissim that appeared in ANTS VII in 2006. The paper was motivated by a cryptographic question, previously introduced by Claus-Peter Schnorr, but the machinery that we ended up using had more to do with extremal graph theory, projective geometry, and combinatorial number theory. It fits in nicely with the overarching theme of this blog, which is interconnectedness of mathematics and CS theory, and leaves open several intriguing questions at the intersection of these areas.
I. Motivation
Consider the problem of computing the discrete logarithm in a generic group of a known prime order 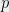 : given two random elements
: given two random elements 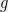 and
and  , find
, find  so that
so that 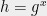 . Instead of having access to the group itself, we may only manipulate encodings of its elements (basically, a random mapping of the group
. Instead of having access to the group itself, we may only manipulate encodings of its elements (basically, a random mapping of the group 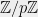 to a sufficiently large alphabet) via a group oracle. The group oracle accepts encodings of two elements and returns the encoding of their product. Think of it as a model of an abstract group, where the result of multiplying two group elements is treated as a new formal variable.
to a sufficiently large alphabet) via a group oracle. The group oracle accepts encodings of two elements and returns the encoding of their product. Think of it as a model of an abstract group, where the result of multiplying two group elements is treated as a new formal variable.
Let us try solving the discrete logarithm problem in this model. Given the encodings of two elements and , one can multiply them, obtaining the encoding of 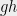 , square the result, etc. In general, it is possible to compute (encodings of) elements of the form
, square the result, etc. In general, it is possible to compute (encodings of) elements of the form 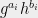 , where
, where 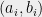 are pairs of integers modulo (all arithmetic not involving or is going to be modulo from now on). Of course, there can be multiple ways of arriving at the same element. For instance,
are pairs of integers modulo (all arithmetic not involving or is going to be modulo from now on). Of course, there can be multiple ways of arriving at the same element. For instance,  (as the group is of the prime order, it is necessarily Abelian). Unless we do it on purpose, all elements that we obtain from the group oracle are going to be distinct with an overwhelming probability over
(as the group is of the prime order, it is necessarily Abelian). Unless we do it on purpose, all elements that we obtain from the group oracle are going to be distinct with an overwhelming probability over  (assume that the group order is large, say, at least
(assume that the group order is large, say, at least  ). Indeed, if
). Indeed, if  , then
, then  which happens for
which happens for  with probability at most
with probability at most 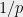 . On the other hand, if we do get a non-trivial relationship, we can recover right away.
. On the other hand, if we do get a non-trivial relationship, we can recover right away.
In other words, the group oracle keeps outputting some random encodings that tell us nothing useful about the elements and (we could sample encodings from the same distribution ourselves, without access to the oracle), until it returns an element that we did see before, which immediately gives away the answer to the discrete logarithm problem.
If is chosen uniformly at random from , the success probability of any algorithm in the generic group model making no more than  group operations is bounded by
group operations is bounded by 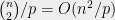 : each pair of elements output by the group oracle collides with probability at most , there are at most
: each pair of elements output by the group oracle collides with probability at most , there are at most  such pairs, union bound, check and mate. A formal version of this handwavy argument is due to Victor Shoup, which gives a tight (up to a constant) bound on the success probability of any algorithm for solving the discrete logarithm problem in the generic group model.
such pairs, union bound, check and mate. A formal version of this handwavy argument is due to Victor Shoup, which gives a tight (up to a constant) bound on the success probability of any algorithm for solving the discrete logarithm problem in the generic group model.
A simple algorithm matches this bound. Let 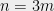 . Compute
. Compute  (by repeat multiplications by ),
(by repeat multiplications by ),  (by repeat multiplications by
(by repeat multiplications by  ), and using the elements already available, compute
), and using the elements already available, compute  . If
. If ![{x\in [-m,m^2-m]}](https://s0.wp.com/latex.php?latex=%7Bx%5Cin+%5B-m%2Cm%5E2-m%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002) , there’s going to be a collision between
, there’s going to be a collision between  and
and 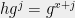 for some
for some 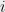 and
and 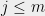 . This algorithm is known as the baby-step giant-step method — we are making “baby ”steps when we are multiplying by powers of , and “giants” steps, when we are computing powers of . If
. This algorithm is known as the baby-step giant-step method — we are making “baby ”steps when we are multiplying by powers of , and “giants” steps, when we are computing powers of . If  , the discrete logarithm problem is solved with probability 1.
, the discrete logarithm problem is solved with probability 1.
The above argument suggests that in order to solve the discrete logarithm problem in the generic group model one would want to maximize the probability of observing a collision. Collisions have simple geometric interpretation: each time the algorithm computes  , it draws a line
, it draws a line  in the
in the  space. An element
space. An element  is “covered” if two lines intersect above this element:
is “covered” if two lines intersect above this element:  . The adversary is trying to cover as many elements as possible with the fewest number of lines.
. The adversary is trying to cover as many elements as possible with the fewest number of lines.
As we just have seen, the number of group operations required to solve the discrete logarithm problem in the generic group when and are chosen uniformly at random is 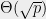 . The question becomes much more interesting if we constrain the joint distribution of and .
. The question becomes much more interesting if we constrain the joint distribution of and .
What is the complexity of the discrete logarithm problem measured as the number of group operations, if  , where is sampled uniformly from
, where is sampled uniformly from  ?
?
It turns out that this question has been answered for some simple sets 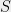 , but it is wide open in general.
, but it is wide open in general.
II. Geometric Formulation
We re-formulate the problem using the language of finite field geometry.
Given a subset of  , define its DL-complexity, denoted as
, define its DL-complexity, denoted as 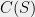 , as the minimal number of lines in whose intersection points projected to the -axis cover .
, as the minimal number of lines in whose intersection points projected to the -axis cover .
In the notation of the previous section, the adversary is drawing lines  . It scores a hit when two lines intersect above point
. It scores a hit when two lines intersect above point  , i.e.,
, i.e.,  . The adversary’s goal is to cover the entire set with the smallest number of lines, which would correspond to solving the discrete logarithm problem for the case when and
. The adversary’s goal is to cover the entire set with the smallest number of lines, which would correspond to solving the discrete logarithm problem for the case when and  .
.
What are the most basic facts about ?
 . Indeed, we know that the (generic) baby-step giant-step algorithm covers the entire with lines.
. Indeed, we know that the (generic) baby-step giant-step algorithm covers the entire with lines.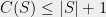 — duh! It suffices to draw a single line
— duh! It suffices to draw a single line 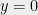 and one line for each element of
and one line for each element of  .
.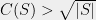 : if
: if  lines can cover the entire , then the number of intersection points, which is less than
lines can cover the entire , then the number of intersection points, which is less than  , is at least
, is at least  .
.
Putting these bounds together on this schematic picture drawn in the log-log scale, we can see that lives inside the shaded triangle.
 The most intriguing part of the triangle is the upper-left corner, marked with the target sign, that corresponds to sets that are as small as
The most intriguing part of the triangle is the upper-left corner, marked with the target sign, that corresponds to sets that are as small as 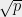 but have the property that solving the discrete logarithm problem in these subsets is as hard as in the entire . How can we get there, or just get closer? But first, why do we care at all?
but have the property that solving the discrete logarithm problem in these subsets is as hard as in the entire . How can we get there, or just get closer? But first, why do we care at all?
One, rather vague motivation is that we are interested in characterizing these subsets because they capture the complexity of the discrete logarithm problem. Another, due to Claus-Peter Schnorr, who defined the problem in 2000, is that the amount of entropy needed to sample an element of that set is half of 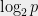 . The observation that got us going back in 2005 was that modular exponentiation takes amount of time that depends on the exponent. Wouldn’t it be nice if we could choose exponents that allowed for faster exponentiation algorithms? These exponents could cover only a fraction of the entire space, which naturally led us to the question of understanding the discrete logarithm problem restricted to a subset, which turned out to be very interesting in its own right.
. The observation that got us going back in 2005 was that modular exponentiation takes amount of time that depends on the exponent. Wouldn’t it be nice if we could choose exponents that allowed for faster exponentiation algorithms? These exponents could cover only a fraction of the entire space, which naturally led us to the question of understanding the discrete logarithm problem restricted to a subset, which turned out to be very interesting in its own right.
The first result, going back to Schnorr, is very encouraging:
For a random of size  ,
,  with probability at least
with probability at least 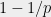 .
.
It means a random subset has essentially maximal possible DL-complexity (up to a  factor) with very high probability. Unfortunately, using (truly) random subsets forecloses the possibility of extracting any gains in exponentiation relative to the average case. Second, it really does not quite answer the question of whether any specific sets are particularly hard for the discrete logarithm problem.
factor) with very high probability. Unfortunately, using (truly) random subsets forecloses the possibility of extracting any gains in exponentiation relative to the average case. Second, it really does not quite answer the question of whether any specific sets are particularly hard for the discrete logarithm problem.
In the rest of this post we explore several approaches towards constructing explicit sets and sets with succinct representation for which we can prove a lower bound on their DL-complexity stronger than  .
.
III. A first attempt
Rather than trying to solve the problem in full generality, let’s constrain the definition of to capture only generalizations of the baby-step giant-step method. Let us call this restriction  , defined as follows:
, defined as follows:
Given a subset of , let  be the minimal number so that is covered by intersection of two sets of lines
be the minimal number so that is covered by intersection of two sets of lines  and
and  , where
, where  .
.
Recall that the intersection of two lines covers an element of if these lines intersect at a point whose first coordinate is in .
The definition of complexity considers only horizontal lines (analogous to the giant steps of the algorithm,  ) and parallel slanted lines (corresponding to the elements
) and parallel slanted lines (corresponding to the elements  ). The 1 in BSGS1 refers to the fact that all slanted lines have slope of exactly 1 (for now — this condition will be relaxed later).
). The 1 in BSGS1 refers to the fact that all slanted lines have slope of exactly 1 (for now — this condition will be relaxed later).
Can we come up with a constraint on that would guarantee that 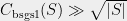 ? It turns out that we can.
? It turns out that we can.
Assume for a moment that all pairwise sums of elements in are distinct, i.e., no four elements satisfy the following equation:  , where
, where  , unless
, unless  . If this is the case, at least one of the intersection points of the lines in the following configuration will miss an element of :
. If this is the case, at least one of the intersection points of the lines in the following configuration will miss an element of :
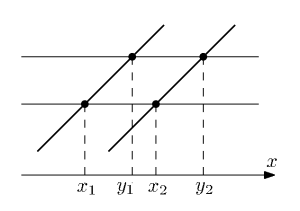
To see why it is so, observe that 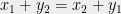 — a contradiction with ‘s not having solutions to this equation.
— a contradiction with ‘s not having solutions to this equation.
We now introduce one more way of thinking about these lines in that are trying to hit elements of (we promise it is going to be the last!). Associate lines with the vertices of a graph and draw an edge between two vertices if the intersection point of the corresponding vertices projects to (“kills an element of ”).
If all pairwise sums of are distinct, then the graph whose nodes are the horizontal and slanted lines does not have a 4-cycle. This property alone is sufficient to bound the total number of edges in the graph (and thus the number of elements of hit by these lines) to be less than 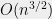 . If the graph is bipartite, which is our case, this bound is known as the Zarankiewicz problem, which can be established via a simple counting argument.
. If the graph is bipartite, which is our case, this bound is known as the Zarankiewicz problem, which can be established via a simple counting argument.
If  lines cannot cover more than elements of , it means that
lines cannot cover more than elements of , it means that  .
.
What’s left to do is to construct sets whose pairwise sums never repeat. They are known as modular Sidon sets, with several beautiful constructions resulting in sets of astonishingly high density. Ponder it for a moment: we want a subset of such that no two pairs of its elements sum to the same thing. Obviously, by the pigeonhole principle, the size of such as set is . This bound is tight, as there exist — explicit, and efficiently enumerable — sets of size !
Notice that when two lines cover an element of , their coefficients satisfy an especially simple condition: if 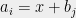 , where
, where  , then
, then  . Let
. Let  and
and  . If all of is covered by intersections between lines
. If all of is covered by intersections between lines 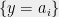 and
and  , then
, then  , where
, where  is the sumset of
is the sumset of  and
and  . Using the language of additive combinatorics, Erdős and D. Newman posed in 1977 the problem of constructing subsets of
. Using the language of additive combinatorics, Erdős and D. Newman posed in 1977 the problem of constructing subsets of  that cannot be covered by sumsets of small sets. They proved that the set of “small squares”
that cannot be covered by sumsets of small sets. They proved that the set of “small squares”  has this property, or in our terminology,
has this property, or in our terminology,  for any
for any 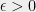 .
.
IV. Moving upwards
Let’s relax the constraint of the previous definition by allowing two classes of lines — horizontal and arbitrarily slanted, but the only hits that count are due to intersections between lines of different classes. Call the resulting measure of complexity  :
:
Given a subset of , let be the minimal number so that is covered by intersection of two classes of lines and  , for
, for  , where only intersections between lines of different classes count towards covering .
, where only intersections between lines of different classes count towards covering .
By analogy with the previous argument, we’d like to identify a local property on that will result in a non-trivial bound on . More concretely, we should be looking for some condition on a small number of elements of that make them difficult to cover by few lines of two different classes.
Fortunately, one such property is not that difficult to find. Consider the following drawing:
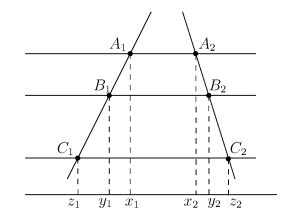
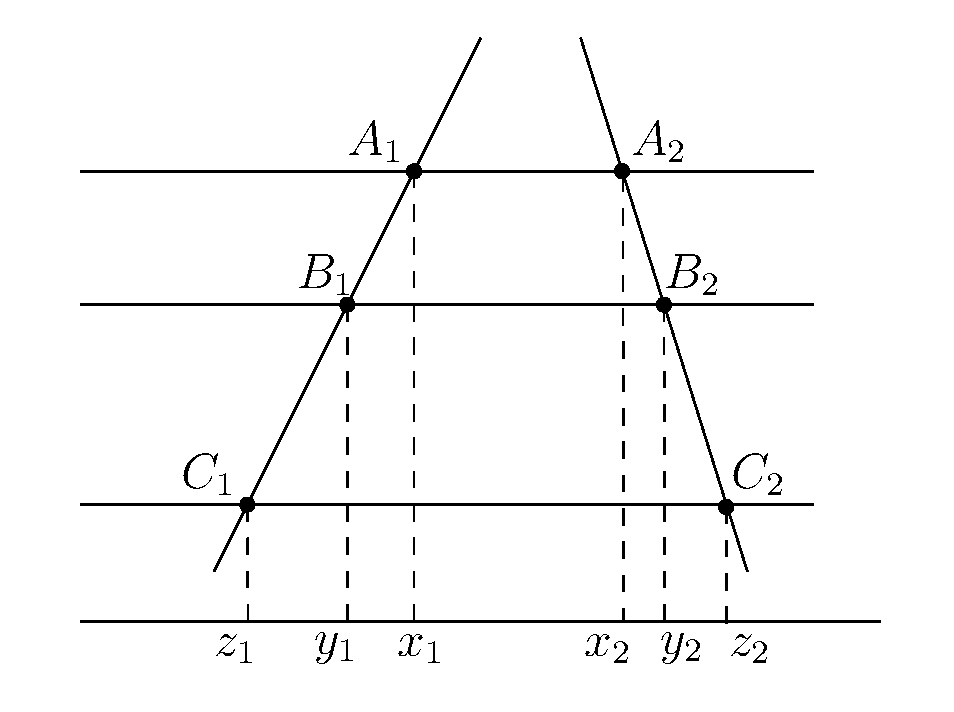
The intercept theorem (known also as Thales’ theorem) implies that 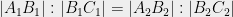 , and consequently (applying it a second time),
, and consequently (applying it a second time),
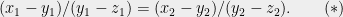
Conversely, if the 6-tuple  is such that
is such that  , these points cannot be covered all at once by three horizontal and two slanted lines.
, these points cannot be covered all at once by three horizontal and two slanted lines.
Consider again the bipartite graph drawn on the sets of horizontal and slanted lines, where two lines are adjacent in the graph if their intersection point covers an element of . What is the maximal density of this graph if it is prohibited from containing the  subgraph? Somewhat surprisingly, the answer is asymptotically the same as before, namely, the number of edges in the graph is . Therefore, if the set avoids 6-tuples satisfying (*), then
subgraph? Somewhat surprisingly, the answer is asymptotically the same as before, namely, the number of edges in the graph is . Therefore, if the set avoids 6-tuples satisfying (*), then 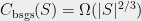 .
.
What about constructing sets that have that property? A short answer is that we don’t know how to do so explicitly, but at least there exist sets satisfying this property with succinct representation.
V. Going all the way
Having flexed our muscles with the watered-down notions of sets’ DL-complexity, let us try to extend our technique to handle the most general case of unrestricted lines, where everything goes and all intersections count towards the attacker’s goal of covering the entire set .
Once again, we’d like to find a local property with global repercussions. Concretely, we should be looking for a configuration of lines whose intersection points satisfy some avoidable condition, similar to or the quadratic polynomial of the previous section. It may seem that we should look no further than Menelaus’ theorem, which gives us just that. If your projective geometry is a bit rusty, Menelaus’ theorem applies to the six intersection points of four lines in the plane:
 It states, in the form most relevant to us that
It states, in the form most relevant to us that
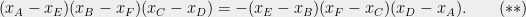
It seems like a nice local property but what about its global ramifications? Namely, if we manage to construct a set such that no 6-tuple satisfies the cubic polynomial (**), what can we say about the number of lines required to cover that set? Well, our luck runs out here. Recall that we used the local property to guarantee that the graph, whose nodes corresponded to lines and edges corresponded to elements of covered by intersection points, excluded a certain subgraph. First, it was a 4-cycle, then . Unfortunately, if the graph excludes a complete graph on four vertices, which Menelaus’ theorem guarantees for sets avoiding (**), the number of edges in that graph can be as large as  . This is the consequence of Turán’s theorem (or Erdős–Stone) that yields no bound better than that unless the excluded subgraph is bipartite.
. This is the consequence of Turán’s theorem (or Erdős–Stone) that yields no bound better than that unless the excluded subgraph is bipartite.
The only path forward is to find a Menelaus-like theorem that allows us to exclude a bipartite graph. It turns that the minimal such configuration involves seven lines and 12 intersection points:
 Most compactly, the theorem states that the following determinant evaluates to 0:
Most compactly, the theorem states that the following determinant evaluates to 0:
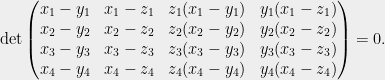
Using the same argument as before, if avoids solutions to the above equation on 12 variables and total degree 6, the “hit” graph defined over the lines avoids the  graph. A variant of the Zarankiewicz bound guarantees that such graph has
graph. A variant of the Zarankiewicz bound guarantees that such graph has 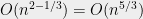 edges (the exponent in the Zarankiewicz bound depends only on size of the smaller part of the excluded bipartite graph). Since each element of the set corresponds to at least one edge of the “hit” graph,
edges (the exponent in the Zarankiewicz bound depends only on size of the smaller part of the excluded bipartite graph). Since each element of the set corresponds to at least one edge of the “hit” graph, 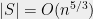 and consequently
and consequently  , which is better than the trivial bound
, which is better than the trivial bound 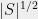 . Finding explicit constructions remains a challenge, although it is easy to demonstrate existence of such sets with succinct representation by probabilistic method.
. Finding explicit constructions remains a challenge, although it is easy to demonstrate existence of such sets with succinct representation by probabilistic method.
VI. Bipartite Menelaus’ Theorem and Open Problems
Even though our original motivation was rooted in cryptography, we ended up proving a fact of projective geometry. In an equivalent form, which is most similar to the standard formulation of Menelaus’ theorem, it asserts that
 where the line segments are signed: positive if they point in the same direction as the line they are part of (for some arbitrary but fixed orientation), and negative otherwise.
where the line segments are signed: positive if they point in the same direction as the line they are part of (for some arbitrary but fixed orientation), and negative otherwise.
The classic (and classical — after all, Menelaus of Alexandria lived in the first century AD) theorem is implied by ours. Indeed, in the degenerate case when  ,
,  , and
, and  , following a furious round of cancellations, we end up with Menelaus’. This explains why we refer to our “12-point’’ theorem as bipartite Menelaus’: it is the minimal Menelaus-like theorem that involves lines separated into two classes.
, following a furious round of cancellations, we end up with Menelaus’. This explains why we refer to our “12-point’’ theorem as bipartite Menelaus’: it is the minimal Menelaus-like theorem that involves lines separated into two classes.
We did search far and wide for evidence that this theorem had been known before, and came up empty. In retrospect, such a theorem is inevitable — the number of intersections (i.e., equations) grows quadratically in the number of lines, each of which only requires two free variables to describe. This is a counting argument that really gives no insight into why bipartite Menelaus’ theorem is what it is. Is there a purely geometric proof? Is it a consequence of a simpler/deeper fact about projective geometries over finite fields? We’d love to know.
Let’s measure our progress against the initial goal of finding explicit sets that are as hard as the entire group against the discrete-logarithm-finding adversary. We are not there yet — although we did develop some machinery for arguing that some sets are more resistant than the most pessimistic square-root bound implies, but these sets are hard to construct and too small to be useful. What about proving that some natural sets, such as the sets of squares, as in Erdős-Newman, or cubes, have high DL-complexity? It is conceivable that the combinatorial approach based on excluded subgraphs is not sufficient to get us to the sweet spot of sets of size and DL-complexity  . What can?
. What can?
A necessary disclaimer: the generic group model is just that — a model. Any instantiation of the abstract group allows direct observation of the group elements, and may enable attacks not captured by the model. For instance, representation of the group elements as integers modulo  has enough structural properties that index calculus is exponentially more effective in
has enough structural properties that index calculus is exponentially more effective in  than any generic algorithm. On the positive side, for many groups, such as some elliptic curves or prime-order subgroups of for sufficiently large , no algorithms for finding discrete logarithms faster than generic methods are presently known. It motivates studying generic groups as a useful abstraction of many groups of cryptographic significance.
than any generic algorithm. On the positive side, for many groups, such as some elliptic curves or prime-order subgroups of for sufficiently large , no algorithms for finding discrete logarithms faster than generic methods are presently known. It motivates studying generic groups as a useful abstraction of many groups of cryptographic significance.
Notes
The abstract (generic) group model was introduced in the papers by Nechaev and Shoup, and hardness of the discrete logarithm in that model was shown to be . Several generic methods for computing discrete logarithm with similar total running time are known: Shank’s baby-step giant-step method, Pollard’s rho and kangaroo (lambda) methods. These algorithms can be adapted to intervals ![[a,b]\subset \mathbb{Z}/p\mathbb{Z}](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D%5Csubset+%5Cmathbb%7BZ%7D%2Fp%5Cmathbb%7BZ%7D&bg=eeeeee&fg=000000&s=0&c=20201002) to work in time
to work in time  , matching the pessimistic square-root bound. For small-weight subsets of
, matching the pessimistic square-root bound. For small-weight subsets of  see work of Stinson and references therein. Canetti put forward a variant of the Decisional Diffie-Hellman assumption where one of the exponents is sampled from an arbitrary distribution of bounded min-entropy. Chateauneuf, Ling, and Stinson gave a combinatorial characterization of algorithms for computing discrete logarithm in terms of slope coverings, and show how weak Sidon sets are related to optimal algorithms. Erdős and Newman defined the notion of bases for subsets of , which corresponds (up to a factor of 4) to BSGS1-complexity in . They showed that random subsets of size
see work of Stinson and references therein. Canetti put forward a variant of the Decisional Diffie-Hellman assumption where one of the exponents is sampled from an arbitrary distribution of bounded min-entropy. Chateauneuf, Ling, and Stinson gave a combinatorial characterization of algorithms for computing discrete logarithm in terms of slope coverings, and show how weak Sidon sets are related to optimal algorithms. Erdős and Newman defined the notion of bases for subsets of , which corresponds (up to a factor of 4) to BSGS1-complexity in . They showed that random subsets of size  have basis of size
have basis of size  and for sets of squares their basis is
and for sets of squares their basis is 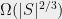 . Subsuming the counting argument of Erdős and Newman, Schnorr proved that the discrete logarithm problem has essentially optimal (up to a logarithmic factor) hardness on random subsets. Resolving the question of Erdős and Newman, Alon, Bukh, and Sudakov showed that for sets of size exactly even their restricted DL-complexity,
. Subsuming the counting argument of Erdős and Newman, Schnorr proved that the discrete logarithm problem has essentially optimal (up to a logarithmic factor) hardness on random subsets. Resolving the question of Erdős and Newman, Alon, Bukh, and Sudakov showed that for sets of size exactly even their restricted DL-complexity,  is
is  . They also extend analysis of BSGS1-complexity for the set of squares to that of higher powers.
. They also extend analysis of BSGS1-complexity for the set of squares to that of higher powers.
 The most intriguing part of the triangle is the upper-left corner, marked with the target sign, that corresponds to sets that are as small as
The most intriguing part of the triangle is the upper-left corner, marked with the target sign, that corresponds to sets that are as small as 
 It states, in the form most relevant to us that
It states, in the form most relevant to us that  Most compactly, the theorem states that the following determinant evaluates to 0:
Most compactly, the theorem states that the following determinant evaluates to 0: where the line segments are signed: positive if they point in the same direction as the line they are part of (for some arbitrary but fixed orientation), and negative otherwise.
where the line segments are signed: positive if they point in the same direction as the line they are part of (for some arbitrary but fixed orientation), and negative otherwise.