(see also this post and these lecture notes)
There is a longstanding feud in statistics between “frequentists” and “Bayesians”. One way to understand these two camps is to consider the following statements:
- The probability that my paternal great great grandfather had blue eyes is 5%
- The probability that the
 -th digit of
-th digit of  is 7 is 10%
is 7 is 10%
A frquentist would say that these statements are meaningless— even if I don’t know his eye color, my great great grandfather either had blue eyes or didn’t, and there is no sense in which it can be blue with probability that is neither 0 or 1. Similarly, the -th digit of is either 7 or isn’t. A Bayesian would say that such probabilities make perfect sense, and in particular one would be completely rational to take, say, an 11 to 1 bet that the -th digit of is 7. Moreover, almost any real-life application of probability theory involves probabilities over events that are in principle pre-determined. After all, even the results of a toss of a die are completely determined by the initial conditions. (This is of course a caricature of both positions, which are subtler than that; also many statisticians are pragmatists who can use either a frequentist or Bayesian perspective in different situations; you can do far worse than watching Michael Jordan’s talk on this issue.)
As theoretical computer scientists, we are naturally frequentists. For us a probability is a measure over some sample space. Moreover, our canonical activity is worst case analysis of algorithms, which meshes well with the frequentist point of view that doesn’t assume any prior distribution over the inputs one might encounter in practice. The canonical notion of pseudo randomness corresponds to a computational analog of frequentist probability. In this blog post I will discuss a different notion of “pseudo randomness”, arising from the study of computational proof systems and convex programming, that can be viewed as a computational analog of Bayesian probability. Borrowing a page from quantum mechanics, this notion will invole objects that behave like probability measure but where some of the probabilities can actually be negative.
“Classical” pseudo-randomness theory
Before describing this new notion, it might be useful to discuss the “classical” notion of pseudo-randomness as was developed in the 1980’s works of Shamir, Blum, Micali, Yao, Goldwasser and others. Recall that a probability measure is a function  where
where  is the sample space (which you can think of as the set of binary strings of length
is the sample space (which you can think of as the set of binary strings of length  for some ), and
for some ), and  satisfies that
satisfies that ![\mu(\omega) \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cmu%28%5Comega%29+%5Cin+%5B0%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002) for all
for all  and
and  . For a function
. For a function 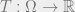 , we define the expectation of
, we define the expectation of  under to be
under to be  .
.
Nore that two distributions and  are identical if and only if
are identical if and only if  for every function . Pseudorandomness arises from relaxing this notion to consider only functions that are efficiently computable. That is, loosely speaking, two measures and are computationaly indistinguishable if for every computationally bounded test (i.e., function
for every function . Pseudorandomness arises from relaxing this notion to consider only functions that are efficiently computable. That is, loosely speaking, two measures and are computationaly indistinguishable if for every computationally bounded test (i.e., function  that can be efficiently computable),
that can be efficiently computable),  and
and 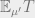 are very close to one another. We say that is pseudorandom if it is computationally indistinguishable from the uniform distribution (i.e., the measure
are very close to one another. We say that is pseudorandom if it is computationally indistinguishable from the uniform distribution (i.e., the measure 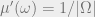 ).
).
I deliberatly omitted the definition of “computationally bounded” and it can change in different settings. Sometimes we consider the set of all tests that can computed by an efficient Turing machine or Boolean circuit (and then need to rely on computational assumptions), and in some applications one can consider more restricted families of tests (such as in Braverman’s result where he showed that distributions with polylogarithmic independence fool all small constant-depth circuits, or the result of Green and Tao that a certain distribution on “almost primes” fools a particular class of tests related to arithmetic progressions).
Pseudorandomness and computational indistinguishability have found a great number of applications in many areas of computer science and mathematics, see Salil Vadhan’s monograph for more on this beautiful area.
Bayesian pseudo-randomness
Bayesian pseudo-distributions arise from taking a computational analog of Bayesian probability. Consider the following scenario: suppose that we are given a SAT formula  that has a unique assignment
that has a unique assignment  . A frequentist would say that there is no sense to a statement such as “the probability that
. A frequentist would say that there is no sense to a statement such as “the probability that  is 60%”. Even a (non computational) Bayesian might have some qualms about defending such a statement. After all, the observation completely determines , and so according to standard Bayesian analysis, the only posterior distribution that makes sense is the one that puts all weight on the single string . But yet to a computer scientist it’s clear that simply because is completely determined by the formula , it doesn’t mean that we can actually recover it. Hence we have some uncertainty about it, and encoding this uncertaintly via probabilities seems rather natural.
is 60%”. Even a (non computational) Bayesian might have some qualms about defending such a statement. After all, the observation completely determines , and so according to standard Bayesian analysis, the only posterior distribution that makes sense is the one that puts all weight on the single string . But yet to a computer scientist it’s clear that simply because is completely determined by the formula , it doesn’t mean that we can actually recover it. Hence we have some uncertainty about it, and encoding this uncertaintly via probabilities seems rather natural.
But how do we actually go about it? Rather than considering efficient tests, we will focus our attention on efficient deduction or proof systems. That is, we say that is a pseudo distribution consistent with if it satisfies that 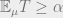 for every function and number
for every function and number  such that a computationally bounded observer can deduce the conclusion that
such that a computationally bounded observer can deduce the conclusion that  from the assumption that satisfies . As above we are deliberately vague on how we model the deductive power of computationally bounded observers, but in fact I also glossed over on an even more basic point— what kind of an object is ? The initial guess is that is simply another distribution — it might not be the true distribution
from the assumption that satisfies . As above we are deliberately vague on how we model the deductive power of computationally bounded observers, but in fact I also glossed over on an even more basic point— what kind of an object is ? The initial guess is that is simply another distribution — it might not be the true distribution  that is supported on the unique satisfying assignment, but simply has a different support. However one can quickly see that this is not possible: under any reasonable model of computation, a bounded observer would be able to deduce that
that is supported on the unique satisfying assignment, but simply has a different support. However one can quickly see that this is not possible: under any reasonable model of computation, a bounded observer would be able to deduce that  for every clause
for every clause 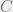 of . For example, if contains the clause
of . For example, if contains the clause 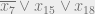 then clearly it is trivial to deduce that every distribution over satisfying assignments would satisfy
then clearly it is trivial to deduce that every distribution over satisfying assignments would satisfy  . But note that if was supported on even a single string that failed to satisfy this clause then it would have been the case that
. But note that if was supported on even a single string that failed to satisfy this clause then it would have been the case that  . Since the same reasoning applies to all clauses, we can conslude that the only distribution that is consistent with is the distribution over the unique satisfying assignment.
. Since the same reasoning applies to all clauses, we can conslude that the only distribution that is consistent with is the distribution over the unique satisfying assignment.
The above seems to trivialize the definition, and again rule out the possiblity of statements such as “ “. However, this only happened because we insisted on being an actual distribution. The definition didn’t require that, but merely required the existence of the operator mapping to the number
“. However, this only happened because we insisted on being an actual distribution. The definition didn’t require that, but merely required the existence of the operator mapping to the number  where is in some class that computationally bounded observers can argue about. Such an operator need not correspond to actual distributions, though if it is linear (which makes sense when we think of a class closed under taking linear combinations), then it must have the form
where is in some class that computationally bounded observers can argue about. Such an operator need not correspond to actual distributions, though if it is linear (which makes sense when we think of a class closed under taking linear combinations), then it must have the form 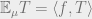 for some function
for some function 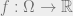 . In fact, we will identify this function
. In fact, we will identify this function  with . Surely a bounded observer can deduce that
with . Surely a bounded observer can deduce that 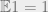 and hence we can assume
and hence we can assume  . The only constraint we might not be able to enforce is that
. The only constraint we might not be able to enforce is that  for all
for all 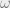 . Hence we can think of as a “distribution” that can take negative probabilities, as long as for “simple” functions , it is still the case that
. Hence we can think of as a “distribution” that can take negative probabilities, as long as for “simple” functions , it is still the case that  whenever a computationally bounded can prove that is non-negative.
whenever a computationally bounded can prove that is non-negative.
The sum of squares proof system (also known as Positivstallensatz) is one concrete candidate for a bounded deduction system. There the simple functions correspond to low degree polynomials, and (roughly speaking) a computationally bounded prover can deduce from 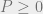 and
and  that
that  and
and  and can use the axiom that
and can use the axiom that  for every low degree
for every low degree 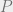 . This gives rise to a rather clean notion of pseudo-distributions where we can make precise statements such as “” where is a distribution over satisfying assignments of , even when has a unique satisfying assignments. In fact, we can even make such statements when has no satisfying assignments, as long as a computationally bounded prover cannot certify that this is the case. Perhaps even more exciting is that we have some reasons to believe (or at least hope) that in some contexts this proof system is optimal in the sense that it captures the capabalities of every computationally bounded observer. There are still many more questions in this research area. See my lecture notes and survey for more on this topic.
. This gives rise to a rather clean notion of pseudo-distributions where we can make precise statements such as “” where is a distribution over satisfying assignments of , even when has a unique satisfying assignments. In fact, we can even make such statements when has no satisfying assignments, as long as a computationally bounded prover cannot certify that this is the case. Perhaps even more exciting is that we have some reasons to believe (or at least hope) that in some contexts this proof system is optimal in the sense that it captures the capabalities of every computationally bounded observer. There are still many more questions in this research area. See my lecture notes and survey for more on this topic.
I do believe that this notion of “pseudo distribution” can be applicable beyond the sum-of-squares algorithm. For example, in number theory there are many heuristics that treat deterministic objects (such as the primes) as if they were chosen at random, and I wonder if these ideas can help formalize such intuitions. A similar situation arises in the study of random constraint satisfaction problems using local algorithms. For a random SAT formula with variables and  clauses, the Belief Propagation algorithm predicts correctly the entropy of the distribution over satisfying assignments for
clauses, the Belief Propagation algorithm predicts correctly the entropy of the distribution over satisfying assignments for  up to roughly 3.86, but then diverges from the truth and in particular predicts that this entropy is positive (and hence the formula is satisfiable) when can be as large as 4.667, whereas the true threshold is roughly 4.267 (see Chapter 14 of this excellent book). One can imagine a notion of “belief propagation pesudo-distribution” which coincides with the actual distribution up to some density but then diverges from it as the problem becomes more computationally difficult. I am also wondering if it can be related to cryptographic notions such as “inaccesible entropy” (e.g., see here) or to questions in computational economics where we try to model the beliefs of computationally bounded agents.
up to roughly 3.86, but then diverges from the truth and in particular predicts that this entropy is positive (and hence the formula is satisfiable) when can be as large as 4.667, whereas the true threshold is roughly 4.267 (see Chapter 14 of this excellent book). One can imagine a notion of “belief propagation pesudo-distribution” which coincides with the actual distribution up to some density but then diverges from it as the problem becomes more computationally difficult. I am also wondering if it can be related to cryptographic notions such as “inaccesible entropy” (e.g., see here) or to questions in computational economics where we try to model the beliefs of computationally bounded agents.

2 thoughts on “A different type of pseudo”