(See also pdf version , and these lecture notes)
The divide between frequentists and Bayesians in statistics is one of those interesting cases where questions of philosophical outlook have actual practical implications. At the heart of the debate is Bayes’ theorem:
![\Pr[A|B] = \Pr[A \cap B ]/\Pr[B]\;.](https://s0.wp.com/latex.php?latex=%5CPr%5BA%7CB%5D+%3D+%5CPr%5BA+%5Ccap+B+%5D%2F%5CPr%5BB%5D%5C%3B.&bg=eeeeee&fg=666666&s=0&c=20201002)
Both sides agree that it is correct, but they disagree on what the symbols mean. For frequentists, probabilities refer to the fraction that an event happens over repeated samples. They think of probability as counting, or an extension of combinatorics. For Bayesians, probabilities refer to degrees of belief, or, if you want, the odds that you would place on a bet. They see probability as an extension of logic.1
A Bayesian is like Sherlock Holmes, trying to use all available evidence to guess who committed the crime. A frequentist is like the lawmaker who comes up with the rules how to assign guilt or innocence in future cases, fully accepting that in some small fraction of the cases the answer will be wrong (e.g., that a published result will be false despite having statistical significance). The canonical question for a Bayesian is “what can I infer from the data about the given question?” while for a frequentist it is “what experiment can I set up to answer the question?”. Indeed, for a Bayesian probability is about the degrees of belief in various answers, while for a frequentist probability comes from the random choices in the experiment design.
If we think of algorithmic analogies, then given the task of finding a large clique in graphs, a frequentist would want to design a general procedure that has some assurances of performance on all graphs. A Bayesian would be only interested in the particular graph he’s given. Indeed, Bayesian procedures are often exponential in the worst case, since they want to use all available information, which more often than not will turn out to be computationally costly. Frequentists on the other hand, have more “creative freedom” in the choice of which procedure to use, and often would go for simple efficient ones that still have decent guarantees (think of a general procedure that’s meant to adjudicate many cases as opposed to deploying Sherlock Holmes for each one).
Given all that discussion, it seems fair to place theoretical computer scientists squarely in the frequentist camp of statistics. But today (continuing a previous post) I want to discuss what a Bayesian theory of computation could look like. As an example, I will use my recent paper with Hopkins, Kelner, Kothari, Moitra and Potechin, though my co authors are in no way responsible to my ramblings here.
Peering into the minds of algorithms.
What is wrong with our current theory of algorithms? One issue that bothers me as a cryptographer is that we don’t have many ways to give evidence that an average-case problem is hard beyond saying that “we tried to solve it and we couldn’t”. We don’t have a web of reductions from one central assumption to (almost) everything else as we do in worst-case complexity. But this is just a symptom of a broader lack of understanding.
My hope is to obtain general heuristic methods that, like random models for the primes in number theory or the replica method in statistical physics, would allow us to predict the right answer to many questions in complexity, even if we can’t rigorously prove it. To me such a theory would need to not just focus on questions such as “compute 

What do I mean by “computational knowledge”? Well, while generally if you stop an arbitrary C program before it finishes its execution then you get (to use a technical term) bubkas, there are some algorithms, such as Monte Carlo Markov Chain, belief propagation, gradient descent, cutting plane, as well as linear and semidefinite programming hierarchies, that have a certain “knob” to tune their running time. The more they run, the higher quality their solution is, but one could try to interpret their intermediate state as saying something about the knowledge that they accumulated about the solution up to this point.
Even more ambitiously, one could hope that in some cases one of those algorithms is the best, and hence its intermediate state can be interpreted as saying something about the knowledge of every computationally bounded observer that has access to the same information and roughly similar computational resources.
Modeling our knowledge of an unknown clique
To be more concrete, suppose that we are given a graph 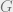




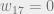
But if you consider probabilities as encoding beliefs, then it’s quite likely that a computationally bounded observer is not certain whether 



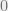

Here is one approach. Since we are given no information on 



true in a satisfying assignment” even if the formula is unsatisfiable.) This is analogous to trying to compute the probability that a unicorn has blue eyes, but indeed computationally bounded observers are in the uncomfortable positions of having to talk about their beliefs even in objects that mathematically cannot exist.
Computational Bayesian probabilities
So, what would a consistent theory of “computational Bayesian probabilities” would look like? Let’s try to stick as closely as possible to standard Bayesian inference. We think that there are some (potentially unknown) parameters 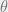


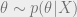





A crucial property we require is calibration: if 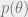
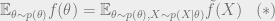
Indeed, the most simple minded computationally bounded observer might ignore 
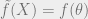
But of course we want to also talk about the beliefs of observers with intermediate powers. To do that, we want to say that 


Finally, we would also want to ensure that the map 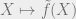
Different rules of inference or proof systems lead to different ways of assigning these probabilities. The Sum of Squares algorithm / proof system is one choice I find particularly attractive. Its main advantages are:
- It encapsulates many algorithmic techniques and for many problems it captures the best known algorithm. That makes it a better candidate for capturing (for some restricted subset of all computational problems) the beliefs of all computationally bounded observers.
- It corresponds to a very natural proof system that contains in it many of the types of arguments, such as Cauchy Schwarz and its generalizations, that we use in theoretical computer science. For this reason it has been used to find constructive versions of important results such as the invariance principle.
- It is particularly relevant when the functions
- It is a tractable enough model that we can prove lower bounds for it, and in fact have nice interpretations as to what these “estimates” are, in the sense that they correspond to a distribution-like object that “logically approximates” the Bayesian posterior distribution of
SoS lower bounds for the planted clique.
Interestingly, a lower bound showing that SoS fails on some instance amounts to talking about “unicorns”. That is, we need to take an instance 
We need to come up with reasonable “pseudo Bayesian” estimates for certain quantities even though in reality these estimates are either completely determined (if 
For example, if 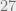







![\Pr[N(\tfrac{n}{2}+k,\tfrac{n}{4})=Z]/\Pr[N(\tfrac{n}{2},\tfrac{n}{4})=Z]](https://s0.wp.com/latex.php?latex=%5CPr%5BN%28%5Ctfrac%7Bn%7D%7B2%7D%2Bk%2C%5Ctfrac%7Bn%7D%7B4%7D%29%3DZ%5D%2F%5CPr%5BN%28%5Ctfrac%7Bn%7D%7B2%7D%2C%5Ctfrac%7Bn%7D%7B4%7D%29%3DZ%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

We can try to use similar ideas to come up with how we should update our estimate for
In our new paper we take an alternate route. Rather than trying to work out the updates for each such term individual, we simply declare by fiat that our estimates should:
- Be simple functions of the graph itself. That is
will be a low degree function of
- Respect the calibration condition (*) for all functions
This condition turns out to imply that our estimates automatically respect all the low degree statistics. The “only” work that is then left is to show that they satisfy the constraint that the estimate of a 
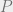

I think that a fuller theory of computational Bayesian probabilities, which would be the dual to our standard “frequentist” theory of pseudorandomness, is still waiting to be discovered. Such a theory would go far beyond just looking at sums of squares.
- As discussed in my previous post, this is somewhat of a caricature of the two camps, and most practicing statisticians are pragmatic about this and happy to take ideas from either side as it applies to their particular situation.↩

Hi Boaz’ can you explain a little more or give concrete examples what is the practical difference between frequentists and Bayesians.
I not an expert on practical data analysis but this talk of Michael Jordan is a pretty good resource http://videolectures.net/mlss09uk_jordan_bfway/
As I said, one of the differences is in the questions asked which is why some people use both Bayesian and Frewuentists tools in different contexts.
Every time you compute statistical significance using some hypothesis test you are using a Frequentist method. And the notion of statistical significance is a frequentist notion: it means that if the null hypothesis was true, if we repeated the same expetiment many times we would have gotten the result we did only 5% of the times.
In contrast, most of the times you make a “one off” decision such as wether to invest in Stock A or Stock B you use Bayesian methods.
One way to contrast the two methods is to look at political polls. The margin of error in a poll is a frequentist notion, the probability here is simply over the choice of the sample.
Trying g to predict who will win based on polls and other data , as well as other prior information on factors related to the final outcome, is Bayesian enterprise. In this case we think of the question of who will win as probabilistic, where the probability is due to our own uncertainty.