It is often said that "we don’t understand deep learning" but it is not as often clarified what is it exactly that we don’t understand. In this post I try to list some of the "puzzles" of modern machine learning, from a theoretical perspective. This list is neither comprehensive nor authoritative. Indeed, I only started looking at these issues last year, and am very much in the position of not yet fully understanding the questions, let alone potential answers. On the other hand, at the rate ML research is going, a calendar year corresponds to about 10 "ML years"…
Machine learning offers many opportunities for theorists; there are many more questions than answers, and it is clear that a better theoretical understanding of what makes certain training procedures work or fail is desperately needed. Moreover, recent advances in software frameworks made it much easier to test out intuitions and conjectures. While in the past running training procedures might have required a Ph.D in machine learning, recently the "barrier to entry" was reduced to first to undergraduates, then to high school students, and these days it’s so easy that even theoretical computer scientists can do it 🙂
To set the context for this discussion, I focus on the task of supervised learning. In this setting we are given a training set 

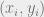


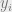
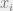
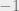



The standard approach is to consider some parameterized family of classifiers, where for every vector 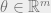



The generalization puzzle
The approach outlined above has been well known and analyzed for many decades in the statistical learning literature. There are many cases where we can prove that a classifier obtained in this case has a small generalization gap, in the sense that if the training set 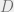
Ultimately, these results all boil down to the Chernoff bound. Think of the random variables 
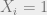





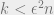






To a first approximation, the number of classifiers (even after "bunching together") is roughly exponential in the number 
This is a beautiful theory, but unfortunately the classical theorems yield vacous results in the realm of modern machine learning, where we often train networks with millions of parameters on a mere tens of thousands of examples. Moreover, Zhang et al showed that this is not just a question of counting parameters better. They showed that modern deep networks can in fact "overfit" and achieve 100% success on the training set even if you gave them random or arbitrary labels.
The results above in particular show that we can find classifiers that perform great on the training set but perform terribly on the future tests, as well as classifiers that perform terrible on the training set but pretty good on future test. Specifically, consider an architecture that has the capacity to fit 
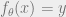


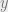


In an analogous way, we can find parameters
The above insights break the separation of concerns or separation of computational problems from algorithms which we theorists like so much. Ideally, we would like to phrase the "machine learning problem" as a well defined optimization objective, such as finding, given a set
Unfortunately, modern machine learning does not currently lend itself to such a clean partition. In particular, since not all optima are equally good, we don’t actually want to solve the task of minimizing the loss function in a "black box" way. In fact, many of the ideas that make optimization faster such as accelaration, lower learning rate, second order methods and others, yield worse generalization performance. Thus, while the objective function is somewhat correlated with generalization performance, it is neither necessary nor sufficient for it. This is a clear sign that we don’t really understand what makes machine learning work, and there is still much left to discover. I don’t know what machine learning textbooks in the 2030’s will contain, but my guess is that they would not prescribe running stochastic gradient descent on one of these loss functions. (Moritz Hardt counters that what we teach in ML today is not that far from the 1973 book of Duda and Hart, and that by some measures ML moved slower than other areas of CS.)
The generalization puzzle of machine learning can be phrased as the question of understanding what properties of procedures that map a training set
The computational puzzle
Yet another puzzle in modern machine learning arises from the fact that we are able to find the minimum of 
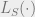
So perhaps the right way to phrase the computational puzzle is as
"How come that we are able to use stochastic gradient descent to find the vector
which when phrased like that, doesn’t seem like much of a puzzle after all.
The off-distribution performance puzzle
In the supervised learning problem, the training samples 
Coming up with a theory that can supply some predictions for learning in a way that is not as tied to the particular distribution is still very much open. I see it as somewhat akin to finding a theory for the performance of algorithms that is somewhere between average-case complexity (which is highly dependant on the distribution) and worst-case complexity (which does not depend on the distribution at all, but is not always achievable).
The robustness puzzle
If the previous puzzles were about understanding why deep networks are surprisingly good, the next one is about understanding why they are surprisingly bad. Images of physical objects have the property that if we modify them in some ways, such as perturbing them in a small number of pixels or by few shades or rotating by an angle, they still correspond to the same object. Deep neural networks do not seem to "pick up" on this property.
Indeed, there are many examples of how tiny perturbations can cause a neural net to think that one image is another, and people have even printed a 3D turtle that most modern systems recognize as a rifle. (See this excellent tutorial, though note an "ML decade" has already passed since it was published). This "brittleness" of neural networks can be a significant concern when we deploy them in the wild. (Though perhaps mixing up turtles and rifles is not so bad: I can imagine some people that would normally resist regulations to protect the environment but would support them if they confused turtles with guns..)
Perhaps one reason for this brittleness is that neural networks can be thought of as a way of embedding a set of examples in dimension 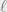
Recent works have attempted to rectify this, by using a variants of the loss function where
The interpretability puzzle
Deep neural networks are inspired by our brain, and it is tempting to try to understand their internal structure just like we try to understand the brain and see if it has a "grandmother neuron". For example, we could try to see if there is a certain neuron (i.e., gate) in a neural network that "fires" only when it is fed images with certain high level features (or more generally find vectors that have large correlation with the state at a certain layer only when the image has some features). This also of practical importance, as we increasingly use classifiers to make decisions such as whether to approve or deny bail, whether to prescribe to a patient treatment A or B, or whether a car should steer left or right, and would like to understand what is the basis for such decisions. There are beautiful visualizations of neural networks’ decisions and internal structures , but given the robustness puzzle above, it is unclear if these really capture the decision process. After all, if we could change the classification from a cat to a dog by perturbing a tiny number of pixels, in what sense can we explain why the network made this decision or the other.
The natural distributions puzzle
Yet another puzzle (pointed out to me by Ilya Sutskever) is to understand what is it about "natural" distributions such as images, texts, etc.. that makes them so amenable to learning via neural networks, even though such networks can have a very hard time with learning even simple concepts such as parities. Perhaps this is related to the "noise robustness" of natural concepts which is related to being correlated with low degree polynomials. Another suggestion could be that at least for text etc.., human languages are implicitly designed to fit neural network. Perhaps on some other planets there are languages where the meaning of a sentence completely changes depending on whether it has an odd or an even number of letters…
Summary
The above are just a few puzzles that modern machine learning offers us. Not all of those might have answers in the form of mathematical theorems, or even well stated conjectures, but it is clear that there is still much to be discovered, and plenty of research opportunities for theoretical computer scientists. In this blog I focused on supervised learning, where at least the problem is well defined, but there are other areas of machine learning, such as transfer learning and generative modeling, where we don’t even yet know how to phrase the computational task, let alone prove that any particular procedure solves it. In several ways, the state of machine learning today seems to me as similar to the state of cryptography in the late 1970’s. After the discovery of public key cryptography, researchers has highly promising techniques and great intuitions, but still did not really understand even what security means, let alone how to achieve it. In the decades since, cryptography has turned from an art to a science, and I hope and believe the same will happen to machine learning.
Acknowledgements: Thanks to Preetum Nakkiran, Aleksander Mądry, Ilya Sutskever and Moritz Hardt for helpful comments. (In particular, I dropped an interpretability experiment suggested in an earlier version of this post since Moritz informed me that several similar experiments have been done.) Needless to say, none of them is responsible for any of the speculations and/or errors above.

Hi Boaz:
A nice summary of some open directions in theoretical ML. Since like me you’re starting this ML journey from theoretical CS (TCS) as a starting point, I wanted to mention a significant difference in the ML worldview: in many cases one has to give up the notion of a problem being defined on all possible input sizes. In TCS, problems like SAT, Matching etc. are defined for all input sizes and one is interested in asymptotic complexity. This is often not true in ML. Example: classifying images of cats vs dogs. At first sight it may appear that the input size is the # of pixels in the image, but this is illusory because the problem is essentially unchanged even if you switch to a camera of 10x resolution. Ditto for many other adjacent fields: NLP, brain, neuroscience, genomics etc.
Of course one can still (carefully) use asymptotic thinking while designing algorithms, since linear time still usually beats quadratic. But many ideas in complexity/lowerbounds/reductions are not as useful because they really rely on the problem definition being asymptotic (eg, a reduction may change problem size from n to n^2).
ps There is of course a separate complication that worst-case complexity of problems is not the right notion for ML but that is clear already in your post. I wanted to caution that even asymptotic complexity is not a good match
Thanks Sanjeev,
I agree with you about asymptotic complexity – the thinking is useful but you should be careful how you apply it – but I think this is true beyond ML. Matching or SAT might be defined for all input lengths but people only care about it for some specific inputs. Similarly, while some ML tasks might have natural intrinsic dimensionality, at least in principle these can grow too (hopefully the ideas behind image recognition can be applied beyond just trying to mimic tasks that humans do with their finite-sized retinas..)
However, as you say, typically an asymptotic difference between linear and quadratic, or polynomial and exponential, whether it is in running time or number of samples will correspond to some “real” phenomenon.
Finally, as I’m sure you can identify, I have never felt the costs of computational inefficiency more real since I started being involved in ML research, as each computational operation literally translate into a charge on my credit card from Google cloud computing.
Boaz
Hi Boaz,
Thanks for summarizing some important questions of modern machine learning.
From a historical perspective one may say that these foundational fissures have been present in machine learning all along (or, at least, for a long time), yet the practical success of deep learning forced us to face the real nature of the underlying phenomena.
One historical reference is the Leo Breiman’s note “Reflections After Refereeing Papers for NIPS” from 1995, where he discussed the current (at the time) state of understanding of neural networks. In particular, he asks the following questions:
“1. Why don’t heavily parameterized neural networks overfit the data?
2. What is the effective number of parameters?
3. Why does not backpropagation head for a poor local minimum?
4. When should one stop backpropagation and use the current parameters?”
All of these questions seem fresh 24 years later.
A similar set of observations was made about the boosting algorithms. In particular, the paper “Boosting the margin: a new explanation for the effectiveness of voting methods” (https://projecteuclid.org/euclid.aos/1024691352) starts with “One of the surprising recurring phenomena observed in experiments with boosting is that the test error of the generated classifier usually does not increase as its size becomes very large, and often is observed to decrease even after the training error reaches zero.” While the theoretical analysis there does not seem to apply in broader settings (e.g., to interpolation of noisy data), the proposed idea that increasing the complexity of the hypothesis space allows for better choice of classifiers is very insightful.
Thanks to deep learning, it now looks like we can view all of these phenomena in the same light, leading to a hope that a unified theory for supervised learning may be possible.
My optimistic view is that all of these puzzles will be addressed and usefully understood mathematically, once we find the right analytical tools.
Misha
Thank you Misha! Indeed I just saw a talk by Lenka Zdeborova where she mentioned this exact quote of Breiman.
While we might have not found answers yet to Breiman’s questions, I do think we now know we should phrase the questions a little differently. For example, the “effective number of parameters” is a useful measure, but it won’t be on its own an explanation of generalization performance, in the sense that, no matter how you measure, the large networks are truly over-parameterized. Similarly, I think that the question is not really why SGD arrives at a good local minima (i.e., one that has small loss for the function it is optimizing) but rather why it arrives at a solution that generalizes well, and the latter property is correlated with but not identical to minimizing the loss function.
Hi Boaz,
I agree. Our understanding of these issues is far better now than 20 years ago. In particular, the question about the effective number of parameters is no
longer very relevant. I am not quite sure what Breiman meant by “poor” local minima — maybe those that do not generalize?
It seems that a reasonably complete theoretical analysis is now within reach.
It is perhaps slightly disconcerting that we needed the practical success of deep learning to point us to something which has been there all along.
Misha