(I’m a non native speaker – is it Hopkins’ or Hopkins’s? –Boaz)
Sam Hopkins just completed a heroic 6 part blog post sequence on using the Sum of Squares algorithm for unsupervised learning.
The goal of unsupervised learning is to recover the underlying structure of a distribution 


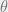
Theoretical computer scientists are used to the setting where every problem can be solved if you have enough computational power, and so intuitively would think that identifiability and recovery have nothing to do with each other, and that the former would be a much easier task than the latter. Indeed this is often the case, but Sam discussed some important cases where we can (almost) automatically transform a proof of identifiability into an efficient algorithm for recovery.
While reading these 6 (not too long) blog posts might take an afternoon, it is an afternoon you would learn something in, and I highly recommend this series, especially for students who might be interested in pursuing questions in the theory of machine learning or the applications of semidefinite programming.
The series is as follows:
- In part I Sam describes the general model of unsupervised learning and focuses on the classical problem (dating at least as far back as the 19th century) of learning a Gaussian mixture model , but for which significant progress was just made by Sam and others. He wisely focuses on the one dimensional case, and gives a proof of identifiability for this case.
- In part II Sam introduces the Sum of Squares proof system, and starts on an SoS proof (and statement) of his identifiability proof from the first Part. He completes this proof of identifiability in the (relatively short) part III.
- In the part IV, Sam completes the transformation of this identifiability proof into an algorithm for the one dimensional Gaussian mixture model.
- The above already gives a complete description of how to transform and identifiability proof to an algorithm, but of course we really care about the high dimensional case. In Part V Sam generalizes the identifiability proof to higher dimensions,
- In Part VI Sam completes the transformation of the higher dimensional identifiability proof to an algorithm, and also includes an overview of other papers and resources on this general area.
While I realize that today’s social media is trending towards 140 characters, I hope that some people still have the attention span for a longer exposition, and I do believe those that read it will find it worthwhile.
Thanks so much Sam!

I would go with Hopkins’ but I’ve noticed some British writers using the other convention.
Hopkins’s, IMO. I think the other ending is reserved for collective ownership. For example: “there are a lot of professors in this department — do they have enough coffee in the professors’ lounge?”