This is the 6th and final part of a series on clustering, Gaussian mixtures, and Sum of Squares (SoS) proofs. If you have not read them yet, I recommend starting with Part 1, Part 2, Part 3, Part 4, and Part 5. Also, if you find errors please mention them in the comments (or otherwise get in touch with me) and I will fix them ASAP.
Did you find this series helpful? Unhelpful? What could be done better? If there were to be another tutorial series on a Sum of Squares-related topic, what would you like to see? Let me know in the comments!
Last time we developed our high-dimensional clustering algorithm for Gaussian mixtures. In this post we will make our SoS identifiability proofs high-dimensional. In what is hopefully a familiar pattern by now, these identifiability proofs will also amount to an analysis of the clustering algorithm from part 5. At the end of this post is a modest discussion of some of the literature on the SoS proofs-to-algorithms method we have developed in this series.
Setting
We decided to remember the following properties of a collection 
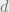
(1) ![S_1,\ldots,S_k \subseteq [n]](https://s0.wp.com/latex.php?latex=S_1%2C%5Cldots%2CS_k+%5Csubseteq+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)


(2) Each cluster has bounded moments, and this has a small certificate: for some 


![\left \| \mathbb{E}_{j \sim S_i} \left ( [X_j - \mu_i]^{\otimes t/2} \right ) \left ( [X_j - \mu_i]^{\otimes t/2} \right )^\top - \mathbb{E}_{Y \sim \mathcal{N}(0, I)} \left ( Y^{\otimes t/2} \right ) \left ( Y^{\otimes t/2} \right)^\top \right \|_F^2 \leq 1](https://s0.wp.com/latex.php?latex=%5Cleft+%5C%7C+%5Cmathbb%7BE%7D_%7Bj+%5Csim+S_i%7D+%5Cleft+%28+%5BX_j+-+%5Cmu_i%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+%5BX_j+-+%5Cmu_i%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29%5E%5Ctop+-+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2C+I%29%7D+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright%29%5E%5Ctop+%5Cright+%5C%7C_F%5E2+%5Cleq+1&bg=eeeeee&fg=666666&s=0&c=20201002)
(3) The means are separated: if 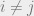

Our identifiability proof follows the template we have laid out in the non-SoS proof from part 1 and the one-dimensional SoS proof from later parts. The first thing to do is prove a key fact about a pair of overlapping clusters with bounded moments.
Fact 3
The next fact is the high-dimensional analogue of Fact 2. (We are not going to prove a high-dimensional analogue of Fact 1; the reader should at this point have all the tools to work it out for themselves.) We remind the reader of the key family polynomial inequalities.
Given a collection of points 



![i \in [n]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
![\sum_{i \in [n]} w_i = N](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+%3D+N&bg=eeeeee&fg=666666&s=0&c=20201002)
![\left \| \frac 1 N \sum_{i \in [n]} \! w_i \left ( [X_i - \mu]^{\otimes t/2} \right ) \! \left ( [X_i - \mu]^{\otimes t/2} \right )^\top \! - \! \mathbb{E}_{Y \sim \mathcal{N}(0, I)} \left ( Y^{\otimes t/2} \right ) \! \left ( Y^{\otimes t/2} \right)^\top \right \|_F^2 \leq 1](https://s0.wp.com/latex.php?latex=%5Cleft+%5C%7C+%5Cfrac+1+N+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D%C2%A0+%5C%21+w_i+%5Cleft+%28+%5BX_i+-+%5Cmu%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5C%21%C2%A0+%5Cleft+%28+%5BX_i+-+%5Cmu%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29%5E%5Ctop%C2%A0+%5C%21+-+%5C%21+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2C+I%29%7D+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5C%21+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright%29%5E%5Ctop+%5Cright+%5C%7C_F%5E2+%5Cleq+1&bg=eeeeee&fg=666666&s=0&c=20201002)
where as usual ![\mu(w) = \frac 1 N \sum_{i \in [n]} w_i X_i](https://s0.wp.com/latex.php?latex=%5Cmu%28w%29+%3D+%5Cfrac+1+N+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+X_i&bg=eeeeee&fg=666666&s=0&c=20201002)
![S \subseteq [n]](https://s0.wp.com/latex.php?latex=S+%5Csubseteq+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

Fact 3.
Let; let
be its mean. Let
be a power of
. Suppose
satisfies
.
Then

The main difference between the conclusions of Fact 3 and Fact 2 is that both sides of the inequality are multiplied by 



The main innovation in proving Fact 3 is the use of the
Proposition.
.
Proof of Proposition.
Expanding the polynomial 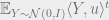

where 




QED.
Proof of Fact 3.
As usual, we write things out in terms of

By SoS Holder’s inequality, we get

By the same reasoning as in Fact 2, using 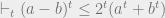

![\mathcal{B} \vdash_{O(t)} \left ( \sum_{i \in S} w_i \right )^t \|\mu - \mu_S\|^{2t} \leq 2^t \cdot \left ( \sum_{i \in S} w_i \right )^{t-1} \cdot \left [ \sum_{i \in [n]} w_i \langle X_i - \mu, \mu - \mu_S \rangle^t + \sum_{i \in S} \langle X_i - \mu_S, \mu - \mu_S \rangle^t \right ].](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BB%7D+%5Cvdash_%7BO%28t%29%7D+%5Cleft+%28+%5Csum_%7Bi+%5Cin+S%7D+w_i+%5Cright+%29%5Et+%5C%7C%5Cmu+-+%5Cmu_S%5C%7C%5E%7B2t%7D+%5Cleq+2%5Et+%5Ccdot+%5Cleft+%28+%5Csum_%7Bi+%5Cin+S%7D+w_i+%5Cright+%29%5E%7Bt-1%7D+%5Ccdot+%5Cleft+%5B+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+%5Clangle+X_i+-+%5Cmu%2C+%5Cmu+-+%5Cmu_S+%5Crangle%5Et+%2B+%5Csum_%7Bi+%5Cin+S%7D+%5Clangle+X_i+-+%5Cmu_S%2C+%5Cmu+-+%5Cmu_S+%5Crangle%5Et+%5Cright+%5D.&bg=eeeeee&fg=666666&s=0&c=20201002)
By our usual squaring and use of 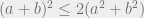
![\mathcal{B} \vdash_{O(t)} \left ( \sum_{i \in S} w_i \right )^{2t} \|\mu - \mu_S\|^{4t} \leq 2^{O(t)} \cdot \left ( \sum_{i \in S} w_i \right )^{2(t-1)} \cdot \left [ \left ( \sum_{i \in [n]} w_i \langle X_i - \mu, \mu - \mu_S \rangle^t \right )^2 + \left ( \sum_{i \in S} \langle X_i - \mu_S, \mu - \mu_S \rangle^t \right ) \right ].](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BB%7D+%5Cvdash_%7BO%28t%29%7D+%5Cleft+%28+%5Csum_%7Bi+%5Cin+S%7D+w_i+%5Cright+%29%5E%7B2t%7D+%5C%7C%5Cmu+-+%5Cmu_S%5C%7C%5E%7B4t%7D+%5Cleq+2%5E%7BO%28t%29%7D+%5Ccdot+%5Cleft+%28+%5Csum_%7Bi+%5Cin+S%7D+w_i+%5Cright+%29%5E%7B2%28t-1%29%7D+%5Ccdot+%5Cleft+%5B+%5Cleft+%28+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+%5Clangle+X_i+-+%5Cmu%2C+%5Cmu+-+%5Cmu_S+%5Crangle%5Et+%5Cright+%29%5E2+%2B+%5Cleft+%28+%5Csum_%7Bi+%5Cin+S%7D+%5Clangle+X_i+-+%5Cmu_S%2C+%5Cmu+-+%5Cmu_S+%5Crangle%5Et+%5Cright+%29+%5Cright+%5D.&bg=eeeeee&fg=666666&s=0&c=20201002)
(We want both sides to be squared so that we are set up to eventually use SoS Cauchy-Schwarz.) We are left with the last two terms, which are
![\mathcal{B} \vdash_{O(t)} \left ( \sum_{i \in [n]} w_i \langle X_i - \mu, \mu - \mu_S \rangle^t \right )^2 \leq 2^{O(t)} t^{t} \cdot \|\mu - \mu_S\|^{2t} \cdot N^2](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BB%7D+%5Cvdash_%7BO%28t%29%7D+%5Cleft+%28+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+%5Clangle+X_i+-+%5Cmu%2C+%5Cmu+-+%5Cmu_S+%5Crangle%5Et+%5Cright+%29%5E2+%5Cleq+2%5E%7BO%28t%29%7D+t%5E%7Bt%7D+%5Ccdot+%5C%7C%5Cmu+-+%5Cmu_S%5C%7C%5E%7B2t%7D+%5Ccdot+N%5E2&bg=eeeeee&fg=666666&s=0&c=20201002)
and similarly
then we would be done. We start with the second inequality. We write the polynomial on the LHS as
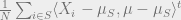

Squaring again as usual, it would be enough to bound both 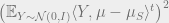

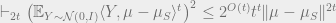
For the latter, notice that
![\left ( \frac 1 N \sum_{i \in S} \langle X_i - \mu_S, \mu - \mu_S \rangle^t - \mathbb{E}_{Y \sim \mathcal{N}(0,I)} \langle Y, \mu - \mu_S \rangle^t \right )^2 = \left \langle M, \left [ (\mu - \mu_S)^{\otimes t/2} \right ] \left [ (\mu - \mu_S)^{\otimes t/2} \right ]^\top \right \rangle](https://s0.wp.com/latex.php?latex=%5Cleft+%28+%5Cfrac+1+N+%5Csum_%7Bi+%5Cin+S%7D+%5Clangle+X_i+-+%5Cmu_S%2C+%5Cmu+-+%5Cmu_S+%5Crangle%5Et%C2%A0+-+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2CI%29%7D+%5Clangle+Y%2C+%5Cmu+-+%5Cmu_S+%5Crangle%5Et+%5Cright+%29%5E2+%3D+%5Cleft+%5Clangle+M%2C+%5Cleft+%5B%C2%A0+%28%5Cmu+-+%5Cmu_S%29%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%5D+%5Cleft+%5B+%28%5Cmu+-+%5Cmu_S%29%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%5D%5E%5Ctop+%5Cright+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002)
where 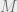
![M = \mathbb{E}_{j \sim S} \left ( [X_j - \mu_S]^{\otimes t/2} \right ) \left ( [X_j - \mu_S]^{\otimes t/2} \right )^\top - \mathbb{E}_{Y \sim \mathcal{N}(0, I)} \left ( Y^{\otimes t/2} \right ) \left ( Y^{\otimes t/2} \right)^\top](https://s0.wp.com/latex.php?latex=M+%3D+%5Cmathbb%7BE%7D_%7Bj+%5Csim+S%7D+%5Cleft+%28+%5BX_j+-+%5Cmu_S%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+%5BX_j+-+%5Cmu_S%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29%5E%5Ctop+-+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2C+I%29%7D+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright%29%5E%5Ctop&bg=eeeeee&fg=666666&s=0&c=20201002)
Hence by SoS Cauchy-Schwarz, we get
![\vdash_{O(t)} \left \langle M, \left [ (\mu - \mu_S)^{\otimes t/2} \right ] \left [ (\mu - \mu_S)^{\otimes t/2} \right ]^\top \right \rangle^2 \leq \|M\|_F^2 \cdot \|\mu - \mu_S\|^{2t} \leq \|\mu - \mu_S\|^{2t}](https://s0.wp.com/latex.php?latex=%5Cvdash_%7BO%28t%29%7D+%5Cleft+%5Clangle+M%2C+%5Cleft+%5B%C2%A0+%28%5Cmu+-+%5Cmu_S%29%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%5D+%5Cleft+%5B+%28%5Cmu+-+%5Cmu_S%29%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%5D%5E%5Ctop+%5Cright+%5Crangle%5E2+%5Cleq+%5C%7CM%5C%7C_F%5E2+%5Ccdot+%5C%7C%5Cmu+-+%5Cmu_S%5C%7C%5E%7B2t%7D+%5Cleq+%5C%7C%5Cmu+-+%5Cmu_S%5C%7C%5E%7B2t%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Putting these together, we get
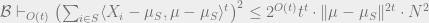
the second of the inequalities we wanted. Proving the first one is similar, using the hypothesis
in place of 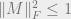
Lemma 3
The last thing is to use Fact 3 to prove Lemma 3, our high-dimensional SoS identifiability lemma. Predictably, it is almost identical to our previous proof of Lemma 2 using Fact 2.
Lemma 3.
Letbe a partition of
pieces of size
such that for each
obeys the following moment bound:
where
is the average
and
which is a power of
be such that
for every
Let
be indeterminates. Let
as defining a set
via its
indicator, let
be the formal expression
Let
be a degree
pseudoexpectation which satisfies
![\tilde{\mathbb{E}} \left [ \sum_{i \in [k]} \left ( \frac{|T \cap S_i|}{N} \right )^2 \right ] \geq 1 - \frac{2^{O(t)} t^{t/2} k^2}{\Delta^t}.](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Cmathbb%7BE%7D%7D+%5Cleft+%5B+%5Csum_%7Bi+%5Cin+%5Bk%5D%7D+%5Cleft+%28+%5Cfrac%7B%7CT+%5Ccap+S_i%7C%7D%7BN%7D+%5Cright+%29%5E2+%5Cright+%5D+%5Cgeq+1+-+%5Cfrac%7B2%5E%7BO%28t%29%7D+t%5E%7Bt%2F2%7D+k%5E2%7D%7B%5CDelta%5Et%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Proof of Lemma 3.
Let 
By 
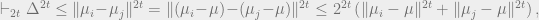
where we implicitly used the SoS triangle inequality 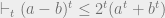

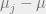
So,
![\tilde{\mathbb{E}} |T \cap S_i|^t |T \cap S_j|^t \leq \tilde{\mathbb{E}} \left [ \frac{\|\mu_i - \mu\|^{2t} + \|\mu_j - \mu\|^{2t}}{2^{2t} \Delta^{2t}} |T \cap S_i|^t |T \cap S_j|^t \right ].](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Cmathbb%7BE%7D%7D+%7CT+%5Ccap+S_i%7C%5Et+%7CT+%5Ccap+S_j%7C%5Et+%5Cleq+%5Ctilde%7B%5Cmathbb%7BE%7D%7D+%5Cleft+%5B+%5Cfrac%7B%5C%7C%5Cmu_i+-+%5Cmu%5C%7C%5E%7B2t%7D+%2B+%5C%7C%5Cmu_j+-+%5Cmu%5C%7C%5E%7B2t%7D%7D%7B2%5E%7B2t%7D+%5CDelta%5E%7B2t%7D%7D%C2%A0+%7CT+%5Ccap+S_i%7C%5Et+%7CT+%5Ccap+S_j%7C%5Et+%5Cright+%5D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Now we are going to bound 
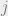
We apply Fact 3:
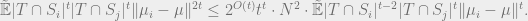
Then we use pseudoexpectation Cauchy-Schwarz to get

Putting these two together and canceling 
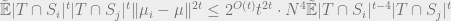
Also, clearly 
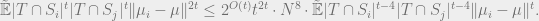
We started out with the goal of bounding
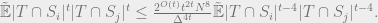
Applying pseudoexpectation Holder’s inequality, we find that
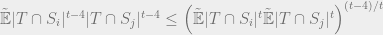
Rearranging things, we get

Now proceeding as in the proof of Lemma 2, we know
![\tilde{\mathbb{E}} \left ( ( \sum_{i \in [k]} \frac{|T \cap S_i|}{N} \right )^2 = 1](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Cmathbb%7BE%7D%7D+%5Cleft+%28+%28+%5Csum_%7Bi+%5Cin+%5Bk%5D%7D+%5Cfrac%7B%7CT+%5Ccap+S_i%7C%7D%7BN%7D+%5Cright+%29%5E2+%3D+1&bg=eeeeee&fg=666666&s=0&c=20201002)
so
![\tilde{\mathbb{E}} \sum_{i \in [k]} \left ( \frac{|T \cap S_i|}{N} \right )^2 \geq 1 - \frac{2^{O(t)} t^{t/2} k^2}{\Delta^{t}}.](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Cmathbb%7BE%7D%7D+%5Csum_%7Bi+%5Cin+%5Bk%5D%7D+%5Cleft+%28+%5Cfrac%7B%7CT+%5Ccap+S_i%7C%7D%7BN%7D+%5Cright+%29%5E2+%5Cgeq+1+-+%5Cfrac%7B2%5E%7BO%28t%29%7D+t%5E%7Bt%2F2%7D+k%5E2%7D%7B%5CDelta%5E%7Bt%7D%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
QED.
Remark: We cheated ever so slightly in this proof. First of all, we did not state a version of pseudoexpectation Holder’s which allows the exponent 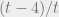

Putting Things Together
The conclusion of Lemma 3 is almost identical to the conclusion of Lemma 2, and so the rest of the analysis of the high-dimensional clustering algorithm proceeds exactly as in the one-dimensional case. At the end, to show that the clustering algorithm works with high probability to cluster samples from a separated Gaussian mixture model, one uses straightforward concentration of measure to show that if
Related literature
The reader interested in further applications of the Sum of Squares method to unsupervised learning problems may consult some of the following works.
- [Barak, Kelner, Steurer] on dictionary learning
- [Potechin, Steurer] on tensor completion
- [Ge, Ma] on random overcomplete tensors
Though we have not seen it in these posts, often the SoS method overlaps with questions about tensor decomposition. For some examples in this direction, see the [Barak, Kelner, Steurer] dictionary learning paper above, as well as
- [Ma, Shi, Steurer] on tensor decomposition
The SoS method can often be used to design algorithms which have more practical running times than the large SDPs we have discussed here. (This often requires further ideas, to avoid solving large semidefinite programs.) See e.g.:
- [Hopkins, Schramm, Shi, Steurer] on extracting spectral algorithms (rather than SDP-based algorithms) from SoS proofs
- [Schramm, Steurer] developing a sophisticated spectral method for dictionary learning via SoS proofs
- [Hopkins, Kothari, Potechin, Raghavendra, Schramm, Steurer] with a meta-theorem on when it is possible to extract spectral algorithms from SoS proofs
Another common tool in constructing SoS proofs for unsupervised learning problems which we did not see here are concentration bounds for random matrices whose entries are low-degree polynomials in independent random variables. For some examples along these lines, see
- [Hopkins, Shi, Steurer] on tensor principal component analysis
- [Rao, Raghavendra, Schramm] on random constraint satisfaction problems
as well as several of the previous papers.

One thought on “Clustering and Sum of Squares Proofs, Part 6”