This is part 5 of a continuing series on clustering, Gaussian mixtures, and Sum of Squares (SoS) proofs. If you have not read them yet, I recommend starting with Part 1, Part 2, Part 3, and Part 4. Also, if you find errors please mention them in the comments (or otherwise get in touch with me) and I will fix them ASAP.
Last time we finished our algorithm design and analysis for clustering one-dimensional Gaussian mixtures. Clustering points on  isn’t much of a challenge. In this post we will finally move to the high-dimensional setting. We will see that most of the ideas and arguments so far carry over nearly unchanged.
isn’t much of a challenge. In this post we will finally move to the high-dimensional setting. We will see that most of the ideas and arguments so far carry over nearly unchanged.
In keeping with the method we are advocating throughout the posts, the first thing to do is return to the non-SoS cluster identifiability proof from Part 1 and see how to generalize it to collections of points in dimension 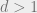 . We encourage the reader to review that proof.
. We encourage the reader to review that proof.
Generalizing the non-SoS Identifiability Proof
Our first step in designing that proof was to correctly choose a property of a collection of samples  from a Gaussian mixture which we would rely on for identifiability. The property we chose was that the points break into clusters
from a Gaussian mixture which we would rely on for identifiability. The property we chose was that the points break into clusters 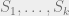 of equal size so that each cluster has bounded empirical
of equal size so that each cluster has bounded empirical  -th moments and the means of the clusters are separated.
-th moments and the means of the clusters are separated.
Here is our first attempt at a high-dimensional generalization: break into  clusters of equal size
clusters of equal size 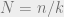 such that
such that
(1) for each cluster  and
and  ,
,
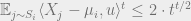
where  is the empirical mean of cluster , and
is the empirical mean of cluster , and
(2) those means are separated:  for
for 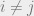 .
.
The first property says that every one-dimensional projection of every cluster has Gaussian -th moments. The second should be familiar: we just replaced distance on the line with 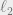 distance in
distance in 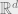 .
.
The main steps in our one-dimensional non-SoS identifiability proofs were Fact 1 and Lemma 1. We will give an informal discussion on their high-dimensional generalizations; for the sake of brevity we will skip a formal non-SoS identifiability proof this time and go right to the SoS proof.
The key idea is: for any pair of sets ![S,S' \subseteq [n]](https://s0.wp.com/latex.php?latex=S%2CS%27+%5Csubseteq+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002) such that
such that  and
and  satisfy the empirical -th moment bound (2) with respect to empirical means
satisfy the empirical -th moment bound (2) with respect to empirical means  and
and  respectively, if
respectively, if 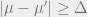 , then by the one-dimensional projections
, then by the one-dimensional projections

are collections of numbers in which satisfy the hypotheses of our one-dimensional identifiability arguments. All we did was choose the right one-dimensional projection of the high-dimensional points  to capture the separation between and .
to capture the separation between and .
(The reader is encouraged to work this out for themselves; it is easiest shift all the points so that without loss of generality  .)
.)
Obstacles to High-dimensional SoS Identifiability
We are going to face two main difficulties in turning the high-dimensional non-SoS identifiability proofs into SoS proofs.
(1) The one-dimensional projections above have  in the denominator, which is not a low-degree polynomial. This is easy to handle, and we have seen similar things before: we will just clear denominators of all inequalities in the proofs, and raise both sides to a high-enough power that we get polynomials.
in the denominator, which is not a low-degree polynomial. This is easy to handle, and we have seen similar things before: we will just clear denominators of all inequalities in the proofs, and raise both sides to a high-enough power that we get polynomials.
(2) The high-dimensional -th moment bound has a “for all  ” quantification. That is, if
” quantification. That is, if 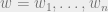 are indeterminates as in our one-dimensional proof, to be interpreted as the
are indeterminates as in our one-dimensional proof, to be interpreted as the 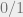 indicators for membership in a candidate cluster
indicators for membership in a candidate cluster ![T \subseteq [n]](https://s0.wp.com/latex.php?latex=T+%5Csubseteq+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , we would like to enforce
, we would like to enforce
![\max_{u \in \mathbb{R}^d} \frac 1 N \sum_{i \in [n]} w_i \langle X_i - \mu, u \rangle^t \leq 2 \cdot t^{t/2} \cdot \|u\|^t](https://s0.wp.com/latex.php?latex=%5Cmax_%7Bu+%5Cin+%5Cmathbb%7BR%7D%5Ed%7D+%5Cfrac+1+N+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+%5Clangle+X_i+-+%5Cmu%2C+u+%5Crangle%5Et+%5Cleq+2+%5Ccdot+t%5E%7Bt%2F2%7D+%5Ccdot+%5C%7Cu%5C%7C%5Et&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
Because of the 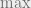 , this is not a polynomial inequality in
, this is not a polynomial inequality in  . This turns out to be a serious problem, and it will require us to strengthen our assumptions about the points .
. This turns out to be a serious problem, and it will require us to strengthen our assumptions about the points .
In order for the SoS algorithm to successfully cluster , it needs to certify that each of the clusters it produces satisfies the -th empirical moment property. Exactly why this is so, and whether it would also be true for non-SoS algorithms, is an interesting topic for discussion. But, for the algorithm to succeed, in particular a short certificate of the above inequality must exist! It is probably not true that such a certificate exists for an arbitrary collection of points in satisfying the -th empirical moment bound. Thus, we will add the existence of such a certificate as an assumption on our clusters.
When  are sufficiently-many samples from a
are sufficiently-many samples from a 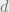 -dimensional Gaussian, the following matrix inequality is a short certificate of the -th empirical moment property:
-dimensional Gaussian, the following matrix inequality is a short certificate of the -th empirical moment property:
![\left \| \frac 1 N \sum_{i \in [m]} \left ( Y_i^{\otimes t/2} \right ) \left ( Y_i^{\otimes t/2} \right)^\top - \mathbb{E}_{Y \sim \mathcal{N}(0, I)} \left ( Y^{\otimes t/2} \right ) \left ( Y^{\otimes t/2} \right)^\top \right \|_F \leq 1](https://s0.wp.com/latex.php?latex=%5Cleft+%5C%7C+%5Cfrac+1+N+%5Csum_%7Bi+%5Cin+%5Bm%5D%7D+%5Cleft+%28+Y_i%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+Y_i%5E%7B%5Cotimes+t%2F2%7D+%5Cright%29%5E%5Ctop+-+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2C+I%29%7D+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright%29%5E%5Ctop+%5Cright+%5C%7C_F+%5Cleq+1&bg=eeeeee&fg=666666&s=0&c=20201002)
where the norm 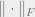 is Frobenious norm (spectral norm would have been sufficient but the inequality is easier to verify with Frobenious norm instead, and this just requires taking a few more samples). This inequality says that the empirical -th moment matrix of is close to its expectation in Frobenious norm. It certifies the -th moment bound, because for any , we would have
is Frobenious norm (spectral norm would have been sufficient but the inequality is easier to verify with Frobenious norm instead, and this just requires taking a few more samples). This inequality says that the empirical -th moment matrix of is close to its expectation in Frobenious norm. It certifies the -th moment bound, because for any , we would have
![\mathbb{E}_{i \sim [m]} \langle Y_i, u \rangle^t \leq \mathbb{E}_{Y \sim \mathcal{N}(0,I)} \langle Y, u \rangle^t + \|u\|^t \leq 2 \cdot t^{t/2} \cdot \|u\|^t](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bi+%5Csim+%5Bm%5D%7D+%5Clangle+Y_i%2C+u+%5Crangle%5Et+%5Cleq+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2CI%29%7D+%5Clangle+Y%2C+u+%5Crangle%5Et+%2B+%5C%7Cu%5C%7C%5Et+%5Cleq+2+%5Ccdot+t%5E%7Bt%2F2%7D+%5Ccdot+%5C%7Cu%5C%7C%5Et&bg=eeeeee&fg=666666&s=0&c=20201002)
by analyzing the quadratic forms of the empirical and true -th moment matrices at the vector  .
.
In our high-dimensional SoS identifiability proof, we will remember the following things about the samples from the underlying Gaussian mixture.
- break into clusters , each of size , so that if is the empirical mean of the
 -th cluster, if , and
-th cluster, if , and
- For each cluster :
![\left \| \mathbb{E}_{j \sim S_i} \left ( [X_j - \mu_i]^{\otimes t/2} \right ) \left ( [X_j - \mu_i]^{\otimes t/2} \right )^\top - \mathbb{E}_{Y \sim \mathcal{N}(0, I)} \left ( Y^{\otimes t/2} \right ) \left ( Y^{\otimes t/2} \right)^\top \right \|_F^2 \leq 1](https://s0.wp.com/latex.php?latex=%5Cleft+%5C%7C+%5Cmathbb%7BE%7D_%7Bj+%5Csim+S_i%7D+%5Cleft+%28+%5BX_j+-+%5Cmu_i%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+%5BX_j+-+%5Cmu_i%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29%5E%5Ctop+-+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2C+I%29%7D+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright%29%5E%5Ctop+%5Cright+%5C%7C_F%5E2+%5Cleq+1&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
Algorithm for High-Dimensional Clustering
Now we are prepared to describe our high-dimensional algorithm for clustering Gaussian mixtures. For variety’s sake, this time we are going to describe the algorithm before the identifiability proof. We will finish up the high-dimensional identifiability proof, and hence the analysis of the following algorithm, in the next post, which will be the last in this series.
Given a collection of points  , let
, let  be the following set of polynomial inequalities in indeterminates
be the following set of polynomial inequalities in indeterminates  :
:
 for all
for all ![i \in [n]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
![\sum_{i \in [n]} w_i = N](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+%3D+N&bg=eeeeee&fg=666666&s=0&c=20201002)
![\left \| \frac 1 N \sum_{i \in [n]} \! w_i \left ( [X_i - \mu]^{\otimes t/2} \right ) \! \left ( [X_i - \mu]^{\otimes t/2} \right )^\top \! - \! \mathbb{E}_{Y \sim \mathcal{N}(0, I)} \left ( Y^{\otimes t/2} \right ) \! \left ( Y^{\otimes t/2} \right)^\top \right \|_F^2 \leq 1](https://s0.wp.com/latex.php?latex=%5Cleft+%5C%7C+%5Cfrac+1+N+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D%C2%A0+%5C%21+w_i+%5Cleft+%28+%5BX_i+-+%5Cmu%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5C%21%C2%A0+%5Cleft+%28+%5BX_i+-+%5Cmu%5D%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29%5E%5Ctop%C2%A0+%5C%21+-+%5C%21+%5Cmathbb%7BE%7D_%7BY+%5Csim+%5Cmathcal%7BN%7D%280%2C+I%29%7D+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright+%29+%5C%21+%5Cleft+%28+Y%5E%7B%5Cotimes+t%2F2%7D+%5Cright%29%5E%5Ctop+%5Cright+%5C%7C_F%5E2+%5Cleq+1&bg=eeeeee&fg=666666&s=0&c=20201002)
where as usual ![\mu(w) = \frac 1 N \sum_{i \in [n]} w_i X_i](https://s0.wp.com/latex.php?latex=%5Cmu%28w%29+%3D+%5Cfrac+1+N+%5Csum_%7Bi+%5Cin+%5Bn%5D%7D+w_i+X_i&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
The algorithm is: given  , find a degree-
, find a degree-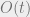 pseudoexpectation
pseudoexpectation  of minimal
of minimal  satisfying . Run the rounding procedure from the one-dimensional algorithm on
satisfying . Run the rounding procedure from the one-dimensional algorithm on  .
.

2 thoughts on “Clustering and Sum of Squares Proofs, Part 5”