Theoretical Computer Science is blessed (or cursed?) with many open problems. For some of these questions, such as the 
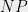

But what other methods can we use to get evidence for questions in computational complexity? After all, it is completely hopeless to experimentally verify even a non-asymptotic statement such as “There is no circuit of size 
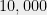
There is in some sense only one tool scientists have to answer such questions, and this is Occam’s Razor. That is, if we want to decide whether an answer to a certain question is Yes or No, we try to think of the simplest/nicest possible world consistent with our knowledge in which the answer is Yes, and the simplest such world in which the answer is No. If, for example, we need to twist and stretch the “No” world in order to fit it with current observations, while the “Yes” world is very natural, and in fact predicts some corollaries that have already been verified, then we can conclude that the answer to our question is probably “Yes”. Let us do this exercise for both of these conjectures.
The Unique Games Conjecture
Khot’s Unique Games Conjecture (UGC) states that a certain approximation problem (known as “Unique Games” or UG) is NP hard. One benefit of using Occam’s Razor is that, if we’re not insisting on formal proofs, we can avoid describing the UG problem and instead focus on the Small Set Expansion (SSE) problem, which I find a bit more natural. While SSE and UG are not known to be formally equivalent, all known algorithmic and hardness results apply equally well to both (c.f., 1, 2, 3, 4, 5, 6). So, whether the UGC is true or not, in a “nice” world these two problems would be equal in computational difficulty. The SSE problem can be described as the problem of “finding a cult inside a social network”: you’re given a graph 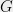

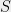
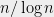
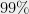
The “UGC true” world.
There is one aspect in which the world where UGC holds is very nice indeed. One of the fascinating phenomenons of complexity is the dichotomy exhibited by many natural problems: they either have a polynomial-time algorithm (often with a low exponent) or are NP-hard, with very few examples in between. A striking result of Raghavendra showed that the UGC implies a beautiful dichotomy for a large family of problems (the constraint-satisfaction problems): there is a clear and simple division between the parameters where they can be solved in polynomial (in fact, quasilinear) time, and those which they cannot. In fact, a single algorithm (based on the Goemans-Williamson semidefinite program for Max-Cut) solves all the cases that can be solved in polynomial time, whereas the rest are NP hard. Alas there is one wrinkle in this picture: where you might expect that in this dichotomy the hard problems would all be equally hard, the subexponential algorithm for unique games shows that some of them would be solved in time 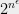
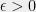


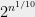
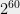
Perhaps the most obvious way in which the “UGC True” world is consistent with current knowledge is that we don’t know of any algorithm that efficiently solves the SSE (or UG) problem. However, by this we mean that there is no algorithm proven to solve the problem on all instances. So there has been an ongoing “battle” between papers showing algorithms that work for natural instances, and papers showing instances that fool natural algorithms. For example, the semi-definite program mentioned above solves the problem on random or expanding inputs. On the other hand, it was shown that there are instances fooling this program (and some generalizations), along the way disproving a conjecture of Goemans and Linial. The subexponential algorithm mentioned above actually runs much faster on those instances, and so for a some time I thought it might actually be a quasipolynomial time algorithm, but there exist instances based on the Reed-Muller code that require it to take (almost) subexponential time. The latest round in this battle was won by the algorithmic side: it turned out that all those papers showing hard instances utilized arguments that can be captured by a sum of squares formal proof system, which implies that the stronger “Sum-of-Squares”/“Lasserre” semidefinite programming hierarchy can solve them in polynomial time.
The “UGC False” world.
While the Unique Games Conjecture can fail in a myriad of ways, the simplest world in which it fails is that there is an efficient (say polynomial or quasipolynomial time) algorithm for the SSE and UG problems. And, given current knowledge, the natural candidate for such an algorithm comes from the “Sum-of-Squares” hierarchy mentioned above. Indeed, for a fairly natural problem on graphs, it’s quite mind boggling that finding hard instances for small-set expansion has been so difficult. In contrast, for other seemingly related problems such as Densest 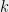
There is actually a spectrum of problems “in the unique games flavor” including not just SSE and UG, but also Max-Cut, Balanced Separator and many others. The cleanest version of the “UGC False” world would be that all of these are significantly easier than NP-hard problems, but whether they are all equal in difficulty is still unclear. Perhaps rather than a dichotomy there would be a smooth time/approximation ratio tradeoff between the threshold in which such problems are NP-hard, and the one in which it can be solved in quasilinear time by the variant of the Geomans-Williamson algorithm.
A personal bottom line.
Regardless of whether the UGC is true, it has been an extremely successful conjecture in that it led to the development of many new ideas and techniques that have found other applications. I am certain that it will lead to more such ideas before it is resolved. There are a number of ways that we could get more confidence in one of the possibilities. We could boost confidence in the “UGC True” case by finding instances that require the sum-of-squares hierarchy a long time to solve. Note that doing so would require using new ideas beyond sum-of-squares arguments. Another way to support the UGC is to try to come up with candidate NP-hardness reductions (even without analysis or assuming some gadgets that have yet to be constructed) for proving it, or to show NP-hardness for problems such as Max-Cut that are “morally close” to the UG/SSE questions. On this latter point, there are some hardness results for problems such as 3LIN over the reals, 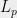
Feige’s Random 3SAT Hypothesis
Unlike Khot’s conjecture, Feige’s Hypothesis (FH) deals with average-case complexity. While a counting argument easily shows that with high probability a random 3SAT formula on 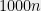
There is added motivation for trying to study heuristic evidence (as opposed to formal proofs) for Feige’s hypothesis. Unlike the UGC, which could be proven via a PCP-type NP-hardness reduction, proving FH seems way beyond our current techniques (even if we’re willing to assume standard assumptions such
The “FH True” world.
One natural way to refute Feige’s Hypothesis would be to show a 





Feige showed that his hypothesis implies several other such hardness of approximation results, including some not known before to hold under
Of course, these hardness of approximation results only relate to worst-case version while the average-case could be potentially much easier. We do note however that in many of these cases, these hardness results are believed to hold even with respect to subexponential (e.g. 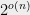

The world in which the generalized form of FH holds is particularly nice in that there is a single algorithm (in fact, the same Goemans-Williamson semidefinite program from above) that achieves the optimal performance on every random constraint-satisfaction problem.
The “FH False” world.
If Feige’s Hypothesis is false, then there should be an algorithm refuting it. No such algorithm is currently known. This could be viewed as significant evidence for FH, but the question is how hard people have tried. Random 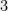
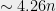
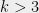
While not known to be equivalent, there is a variant of FH where the goal is not to certify unsatisfiability of a random 3SAT but to find a planted nearly satisfying assignment of a random 3XOR instance. Such instances might be more suitable for computational challenges (a la the RSA Factoring challenge) as well as SAT solving competitions. It would be interesting to study how known heuristics fare on such inputs.
A personal bottom line.
Unlike worst-case complexity, our understanding of average-case complexity is very rudimentary. This has less to do with the importance of average-case complexity, which is deeply relevant not just for studying heuristics but also for cryptography, statistical physics, and other areas, and more to do with the lack of mathematical tools to handle it. In particular, almost every hardness reduction we know of uses gadgets which end up skewing the distribution of instances. I believe studying Feige’s Hypothesis and its ilk (including the conjectures that solution-space shattering implies hardness) offer some of our best hopes for more insight into average-case complexity. I don’t know if we will be able to establish a similar web of reductions to the one we have for worst-case complexity, but perhaps we can come up with meta-conjectures or principles that enable us to predict where the line between easiness and hardness will be drawn in each case. We can study the truth of such conjectures using a number of tools, including not just algorithms and reductions but also integrality-gap proofs, physics-style analysis of algorithms, worst-case hardness-of-approximation results, and actual computational experiments.
As for the truth of Feige’s Hypothesis itself, while it would be premature to use an FH-based encryption to protect state secrets, I think the current (admittedly inconclusive) evidence points in the direction of the hypothesis being true. It definitely seems as if refuting FH would require a new and exciting algorithmic idea. With time, if Feige’s Hypothesis receives the attention it deserves then we can get more confidence in its veracity, or learn more about algorithms for average-case instances.
Parting thoughts
Theoretical Computer Science is sometimes criticized for its reliance on unproven assumptions, but I think we’ll need many more of those if we want to get further insights into areas such as average-case complexity. Sure, this means we have to live with possibility that our assumptions turn out false, just as physicists have to live with the possibility that future experiments might require a revision of the laws of nature, but that doesn’t mean that we should let unconstructive skepticism paralyze us. It would be good if our field had more explicit discussion of what kinds of results can serve as evidence for the hardness or easiness of a computational problem. I deliberately chose two questions whose answer is yet unclear, and for which there is reasonable hope that we’ll learn new insights in the coming years that may upend current beliefs. I hope that as such results come to light, we can reach a better understanding of how we can predict the answer to questions for which we have yet no proofs.

Thanks Boaz, great article. For the record, I believe Feige’s Hypothesis and have become somewhat agnostic on the UGC. I wouldn’t be surprised if there is an algorithm for Max-Cut whose approximation factor goes up from .878 up to 16/17 as you allowed its running time to go up from poly(n) to 2^{n^{1-o(1)}}.
One thing I would like to add is that I’m not sure that constructing new specific integrality gap instances for UG — even ones that defeat the Sum-Of-Squares method — constitutes good evidence that UG is hard. The reason is as follows: Suppose you construct such an instance and prove that although the SOS value is high, the true value is low. Well, presumably your proof that the true value is low was carried out in ZFC and had a reasonable length. So the following “generic” NP algorithm certifies that the instance has low value: guess and verify a short ZFC proof. Granted, this uses nondeterminism, but most people feel that NP-hard problems should not even have coNP algorithms.
My conclusion is that to give good evidence for the hardness of UG, you really need to find a *distribution* on inputs which seems hard. In other words, I agree with your point that we need to focus more on average-case complexity.
Thanks Ryan! I agree with you that a proper hard instance would have to use a nonconstructive argument such as the chernoff+union bound used for random 3SAT. Perhaps fooling SoS would require the use of such methods…
P.s. it you believe Feige’s hypothesis, I’d be interested in your thoughts on the more ambitious version that we propose in the manuscript with Kindler and Steurer
p.p.s, Ryan’s 2007 Oberwolfach talk (which also contrasts the UGC with Feige’s Hypothesis, see http://www.cs.cmu.edu/~odonnell/slides/ugc-on-avg.pps ) , was my first exposure to the question of coming up with hard instances for the Unique Games Conjecture.
Nice and informative article (with pointers to some recent results I wasn’t aware of).
Thanks.
I don’t think that a world in which some NP-hard approximation problems have sub-exponential [2^{n^eps}] complexity and other problems have exponential complexity is a “wrinkled” world. Generally, it is to be expected that different problems have different complexities, no?
More than that, this “wrinkle” is probably there in any case: As you vary the approximation factor you’re after, the same NP-hard approximation problem can move from having exponential complexity (assuming the exponential time hypothesis, namely that SAT requires exponential time) to having sub-exponential complexity. We have good evidence that this is the case with Clique and Set-Cover, for example [these are two problems whose hardness seems unrelated to the unique games conjecture, and so we feel like we might have a better understanding of where things stand].
Generally NP hard problems can of course have subexponential complexity. Indeed, for problems such as k-clique there is always an (n choose k) algorithm. But for constraint satisfaction problems the situation could have been different. For example, in the case of exact computation we believe (assuming the algebraic dichotomy conjecture) that every CSP is either solvable in n^3 time or takes exponential time.
Note that if the UGC is true, then you would still not have all complexities for constant approximation of Max-CSP’s: some CSP’s would be solvable in linear time, while all others would be solvable in time exp(n^{eps}) where eps depends on the problem (and for current NP-hard problems, under ETH, eps would equal 1).
Prasad’s result, which says that the UGC implies dichotomy for approximation of Max-CSP, is up to an epsilon fraction. Similarly, Hastad’s 3SAT is 7/8-hard to approximate result is for 7/8+eps for all *constant* epsilon>0. I have a feeling that if you look at what happens for eps that is smaller than a constant [say eps=1/n^c for certain c’s], you’ll find complexities that are below exp(n^{..}).
In any case, I think that different CSP approximation problems having different complexities exp(n^{alpha}) where alpha depends on the problem, is a natural situation, and not a “wrinkle”.
Great Post!
I’d like to also mention Goldreich’s assumption (1) which nicely complements Feige’s assumption. This assumption essentially asserts that a random local function is hard to invert on average. More precisely, fix some public k-local predicate P, choose a random n-bit input x, apply the predicate P to m random k-subsets of the input variables S_1,…,S_m, and publish the results y_1,…,y_m together with the sets S_1,…,S_m. The assumption (which is parameterized with m,k, and P) asserts that all efficient algorithms fail whp to find the solution x or any other consistent solution x’. In CSP language, this essentially means that solving random CSPs under the planted distribution is hard (think of x as the planted assignment and note that (S_i,y_i) define a k-sparse constraint).
As mentioned in the post, this assumption (which can capture noisy k-XOR as well) is constructive and so it has the advantage of “being more suitable for computational challenges” as well as being useful for cryptography. When m is sufficiently large (say, m=n^k or m=n^{k/2}) the problem is so highly over-constraint that it can be solved via linearization. However, for smaller values of m and reasonable choices of the predicate P the problem seem to be hard. Clearly, we do not know how to prove it, but today there are several evidences that support it, and, more interestingly, some relations to other problems.
In a nutshell, when m=n the problem seems hard for almost all predicates, e.g., DPLLs will run in expected exponential time (2). When the constraint density m/n exceeds a sufficiently large constant, the problem is solvable (3) via spectral techniques if the predicate is “simple”, i.e., correlated with one or two of its inputs (e.g., as in majority). Interestingly, in this regime (or even when the density is n^{\epsilon}) there is evidence (4) that supports a dichotomy: non-simple predicates are almost always hard at least with respect to a limited class of algorithms.
There are also several (average-case) reductions between different variants of the problem. For example, to solve the problem on average it suffices to solve it on a tiny fraction (5) or to find an approximate solution x’ which is, say, 0.51-correlated with a real solution (3).
Furthermore, the hardness of the search problem implies (for a suitable choice of the predicates) that it’s even hard to distinguish the planted CSP (S_i,y_i) from a random CSP in which the y_i’s are chosen uniformly at random (6,7). Since the random case is almost always unsatisfiable (as m>>n) this provides a constructive version of Feige’s hypothesis; namely, a pair of efficiently samplable CSP distributions (SAT,UnSAT), one over satisfiable instances and one over unsatisfiable instances, which cannot be distinguished efficiently. This stronger version also leads to strong consequences such as hardness of approximating the densest-subhypergraph up to a polynomial factor (7), ultra-fast secure two-party computation (that beats FHE!) (8), and provides simple proofs for the existence of approximation resistance predicates (9).
Refs
(1) http://www.wisdom.weizmann.ac.il/~oded/ow-candid.html
(2) http://www.cs.berkeley.edu/~luca/pubs/cemt09.pdf
(3) http://www.cse.cuhk.edu.hk/~andrejb/pubs/goldreichowf.pdf
(4) http://eccc.hpi-web.de/report/2011/126/
(5) http://www.cse.cuhk.edu.hk/~andrejb/pubs/local-amplification.pdf
(6) http://www.eng.tau.ac.il/~bennyap/pubs/ncpkcFull1.pdf
(7) http://www.eccc.uni-trier.de/report/2011/007/
(8) http://www.cs.ucla.edu/~rafail/PUBLIC/91.pdf
(9) http://www.eng.tau.ac.il/~bennyap/pubs/LPRG-full.pdf
Thank you Benny for this informative comment!!
I would like to add two more comments which could support the “UG False” side.
1. I think the following would be a reasonable opinion: “[ABS] showed (roughly speaking) that UG can be solved in time 2^{O(n^eps)} for all eps. Since 2^{n^{.01}} is completely practical as a running time, this shows that UG is simply not Hard; morally speaking the UGC is false. Whether or not UG is formally NP-hard is a question that can be left to the hard-core complexity aficionados — in much the same way as we can leave the question of getting a ‘practical’ exponent like 2^{3 n^{eps}} for all eps to the hard-core algorithmic aficionados.” I don’t necessarily support this opinion, but I’d be sympathetic to it.
2. I think it is fair to say that in the “de facto” or “law of physics” sense, Max-Cut can be efficiently 16/17 approximated. I can even tell you the polynomial-time algorithm: the degree-10 SOS method, say. The fact is that despite lots of thought, no one knows any input, let alone family of inputs, where this algorithm fails to get 16/17. [On the other hand, I can definitely easily randomly generate Max-Cut instances which I’d be shocked if an efficient algorithm can (16/17+eps)-approximate: just start with random unsatisfiable 3Sat instances (a la Feige, or 3XOR a la Alekhnovitch), run the Moshkovitz-Raz reduction on them, run the Hastad 3Lin reduction, and then tack on the Hastad/TSSW gadget. Yes, this is kind of a weird distribution, but (unlike you?) I don’t mind that at all, so long as it’s polynomial-time generatable, which it is.]
I would say that in some sense the UGC is morally both true and false: it’s morally false by the reasons you mention, while morally true because it seems that UG-hard problems are harder in some sense than non-UG-hard problems, if only because they require 10 rounds or so of SOS rather than one.
Regarding 2, note that Alekhnovitch’s 3XOR instance already gives you the result of the Hastad 3LIN reduction (1-eps vs 1/2+eps hardness) so there’s no need to do the Moshkovitz-Raz+Hastad transformation.
> Regarding 2, note that Alekhnovitch’s 3XOR instance already gives you the result of the Hastad 3LIN reduction (1-eps vs 1/2+eps hardness) so there’s no need to do the Moshkovitz-Raz+Hastad transformation.
Oh, right. Even simper then.
Thanks Boaz! You definitely explored two conjectures/assumptions that are progressing our science.
Dealing with assumptions is a tricky business though. Assumptions are of course necessary in Cryptography, but we have seen a huge change in the way they are dealt with. I feel that in Cryptography, we are now rather careless in offering new assumptions that are usually not well studied, nor justified by any serious argument. The flood of new assumptions does not always give appropriately strong applications (they sometimes only seem to facilitate “lazy research”).
Another question, which baffled me all along is what’s the advantage in assuming that UG is NP hard rather than just hard?
Omer, one of my goals is indeed to try to come up with some ways of offering arguments in support of conjectures, when a proof is unlikely. We do sometimes have such heuristic arguments in crypto as well (e.g., random oracle model, black box groups), and I think it’s worthwhile to try to apply such arguments whenever studying a new conjecture, and try to study them in their own right.
I didn’t describe the world in which UG is not NP-hard but it is still hard because we have no evidence for this world, and our experience says that combinatorial optimization problems are either in P or NP-hard unless proven otherwise.. However, it is of course a logical possibility. The fact the UGC is stated as NP-hardness as opposed to hardness doesn’t make much difference, but I kind of like that the conjecture is stated in its strongest form. It also makes sense since UG is a type of a PCP, and PCP’s are always NP-hardness reductions.
Great post. How is a world in which Faige’s Hypothesis is NP-complete looks like?
There are works in Complexity Theory that show that it’s very unlikely [will cause a collapse of the polynomial hierarchy] that there will be reductions from NP-Complete problems to average case problems (See Bogdanov-Trevisan, which is based on Feigenbaum-Fortnow).
Those works talk only about the unlikeliness of non-adaptive reductions from NP-complete problems to average-case problems. Whether adaptive reductions are possible is completely open.
Cold is right about the current knowledge. In fact, i believe that we don’t even know how to rule out reductions with two rounds of adaptivity!
See also the paper http://www.cs.cornell.edu/~mohammad/files/papers/RandCheck.pdf for a recent discussion of this issue.
However, I believe it’s still unlikely that even adaptive reductions can reduce average case hardness to P vs NP.
As an interested bystander to computational complexity, I found this post a wonderful window into current frontiers. Thanks so much for writing it.
Thank you David for your kind words!
Thanks, Dana!
2 more questions:
A way to think about algorithms for random 3-SAT for a 1000n clauses formula is as following: You choose a secret 0-1 string of length n and choose a random 3-SAT with 1000n clauses under the condition that this string is not violated. The algorithmic task is to give an algorithm that will
say yes with high probability for such a formula and say no with high probability on a genuinly random 3-SAT problem with 1000 n clauses.
Does the FH hypothesis say that it is impossible to give such an algorithm or is it stronger/weaker/unrelated.
Another question: “One natural way to refute Feige’s Hypothesis would be to show a (worst-case) approximation algorithm for 3SAT.”
Isnt such an algorithm actually stronger than just refuting the hypothesis?
Re Q1: I believe that the problem you formulated is efficiently solvable as it is known how to find (whp) a satisfying assignment for the planted distribution when the density is a sufficiently large constant. This was first done by Flaxman (http://www.math.cmu.edu/~adf/research/spectral3sat.pdf) as well as by Feige-Vilenchik and Feige-Mossel-Vilenchik. These algorithm find witness for satisfiability and therefore will never err on NO instance, while Feige’s assumption requires a one-sided algorithm which never errs on YES instances.
Re Q2: I believe that such a worst-case refutation procedure would be stronger.
BTW, a seemingly simpler task (which does not refute F’s hypothesis) will be to prove that a short (polynomial) witness for unsatisfiability exists for almost all formulas of density 1000.
Interestingly, for some range of parameters (density n^{0.2}) we only have such a non-constructive result (see Kim-Ofek-Feige).
Hi Gil, I thought I’d add a bit more on top of Benny’s excellent answer.
In the distribution you describe, if the secret string is x_1….x_n, and x_1 happens to equal 1, then there will be a considerable bias towards choosing clauses where x_1 is not negated, and that’s essentially the reason why there are algorithms for this case.
If you want a search version that’s “morally related” to Feige’s Hypothesis, it’s better to do as follows: choose a secret random string x in {0,1}^n, then choose 990n random 3-tuples of literals (i.e. either x_i’s or their negation) such that their XOR equals 1, and add some noise of 10n random 3-tuples.
You’ll get an instance that is 99% satisfiable (since XOR(y_1,y_2,y_3)=1 implies that OR(y_1,y_2,y_3)=1), but it seems that it would be hard to find any assignment that satisfies significantly more than 7/8 fraction of the clauses.
Regarding your second question. Yes, while an algorithm like that is perhaps a natural first approach to refuting FH, it is much stronger than that. Indeed, we know that such an algorithm doesn’t exist unless P=NP, while the evidence for FH is significantly weaker. I think a nonconstructive refutation (in the sense described by Benny) would also “morally refute” Feige’s hypothsis. The Feige-Kim-Ofer result Benny mentions is fascinating, but it only applies in density > n^{0.2}. It also only gives a refutation to the formula being perfectly satisfiable, as opposed to 99% satisfiable, for which, as far as I know, there is no short refutation even for density almost as large as sqrt(n). (Beyond that density, there are fairly easy algorithms.)
Great post!
Quote: “the subexponential algorithm for unique games shows that some of them would be solved in time {2^{n^{\epsilon}}} for some {\epsilon>0}”
Don’t you mean “for all {\epsilon>0}”?