Crossposted on lesswrong Modern humans first emerged about 100,000 years ago. For the next 99,800 years or so, nothing happened. Well, not quite nothing. There were wars, political intrigue, the invention of agriculture -- but none of that stuff had much effect on the quality of people's lives. Almost everyone lived on the modern equivalent … Continue reading Thoughts by a non-economist on AI and economics
CS 2881: AI Safety
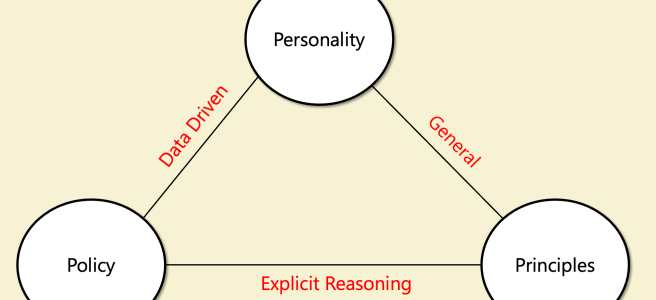
The webpage for my AI safety course is on https://boazbk.github.io/mltheoryseminar/ including homework zero, video of first lecture and slides. Future blog posts related to this course will be posted on lesswrong since many people interested in AI safety visit that. Video of first lecture https://youtu.be/-NCiWaRS6So Some snapshots from slides:
AI Safety Course Intro Blog

I am teaching CS 2881: AI Safety this fall at Harvard. This blog is primarily aimed at students at Harvard or MIT (where we have a cross-registering agreement) who are considering taking the course. However, it may be of interest to others as well. For more of my thoughts on AI safety, see the blogs … Continue reading AI Safety Course Intro Blog
Machines of Faithful Obedience
[Crossposted on LessWrong] Throughout history, technological and scientific advances have had both good and ill effects, but their overall impact has been overwhelmingly positive. Thanks to scientific progress, most people on earth live longer, healthier, and better than they did centuries or even decades ago. I believe that AI (including AGI and ASI) can do … Continue reading Machines of Faithful Obedience
Trevisan prize (guest post by Alon Rosen)
The Trevisan Prize for outstanding work in the Theory of Computing is sponsored by the Department of Computing Sciences at Bocconi University and the Italian Academy of Sciences. The prize is named in honor of Luca Trevisan in recognition of his major contributions to the Theory of Computing. It aims to recognize outstanding work in the field, and to broaden the reach … Continue reading Trevisan prize (guest post by Alon Rosen)
Call for papers Information-Theoretic Crpytography
The sixth Information-Theoretic Cryptography (ITC) conference will be held at UC Santa Barbara, California, on August 16-17, 2025. The conference is affiliated with CRYPTO 2025, and will take place in the same location just before CRYPTO. Information-theoretic cryptography deals with the design and implementation of cryptographic protocols and primitives with unconditional security guarantees and the usage … Continue reading Call for papers Information-Theoretic Crpytography
Knuth prize call for nominations
Please consider nominating worthy candidates to the Knuth Prize! The prize is awarded "for major research accomplishments and contributions to the foundations of computer science over an extended period of time." 2025 Knuth Prize Committee:Noga Alon, Edith Cohen (Chair), David Eppstein, Valerie King, Salil Vadhan, and Moshe Vardi. Deadline: March 31 https://www.sigact.org/prizes/knuth.html
FOCS 2025 call for papers (Guest post by Clément Cannone)
The 66th Annual Symposium on Foundations of Computer Science (FOCS 2025), sponsored by the IEEE Computer Society Technical Committee on Mathematical Foundations of Computing, will be held in Sydney, Australia, December 14-17. Papers presenting new and original research on theory of computation are sought. Typical but not exclusive topics of interest include: algorithmic coding theory, algebraic … Continue reading FOCS 2025 call for papers (Guest post by Clément Cannone)
Six Thoughts On AI Safety
[Crossposted on lesswrong, see here for prior posts] The following statements seem to be both important for AI safety and are not widely agreed upon. These are my opinions, not those of my employer or colleagues. As is true for anything involving AI, there is significant uncertainty about everything written below. However, for readability, I … Continue reading Six Thoughts On AI Safety
ACM Paris Kanellakis Theory and Practice Award
(From Sergey Yekhanin; committee chair) Please nominate people to the Kanellakis award - deadline is December 15. https://awards.acm.org/kanellakis/nominations
