
See arxiv link for paper by Nikhil Vyas, Sham Kakade, and me.
Conditional generative models hold much promise for novel content creation. Whether it is generating a snippet of code, piece of text, or image, such models can potentially save substantial human effort and unlock new capabilities. But there is a fly in this ointment. These models are trained on vast quantities of data, much of which is copyrighted. Due to precedents such as Authors Guild vs Google, many legal scholars believe that training a machine-learning model on copyrighted material constitutes fair use. However, the legal permissibility of using the sampled outputs of such models could be a different matter.
This is not just a theoretical concern. Large models do memorize significant chunks of their training data. For example, if you feed the first sentence of Harry Potter and the Sorcerer’s Stone to GPT-3, it provides the remaining ones:

(To be fair to GPT-3, this text likely appears many times in its training set; deduplication can help with reducing memorization but is not a panacea.)
Similarly, as shown by Carlini et al, diffusion models can (and do) memorize images from their training set as well; see this figure from their paper:

Given the above, if you use a generated code in your program or a generated art in your design, how can you be sure it is not substantially similar to some copyrighted work from the training set, with all the legal and ethical implications this entails?
In a new paper, we (Nikhil, Sham, and Boaz) provide a formalism that enables rigorous guarantees on the similarity (and, more importantly, guarantees on the lack of similarity) between the output of a generative model and any potentially copyrighted data in its training set. Our work is not just theoretical: we give algorithms that can transform a training pipeline into one that satisfies our definition with minimal degradation in efficiency and quality of output. We demonstrate this on both language (transformer) and image (diffusion) models.
As noted in our paper, there are a number of ethical and legal issues in generative models. We should emphasize that our work focuses solely only on copyright infringements by the outputs of these models, and our concepts and tools do not address issues related to other forms of intellectual property, including privacy, trademarks, or fair use. Also, despite superficial similarities between the goals of privacy and copyright protection, these notions are distinct, and our work shows that solution concepts for the latter need not address the former. (See the paper for a detailed discussion of the differences between our definition and differential privacy.)
This post only provides an informal presentation of the concepts and tools formally defined in the paper. Please see the paper for full details.
The Technical Concept: Near Access-Freeness
Our definition is motivated by laws of the U.S. and many other countries to establish that copyright infringement has occurred. This requires:
- Access: To prove that a copyright infringement took place, the plaintiff needs to prove that “the defendant had access to the plaintiff’s copyrighted work.”
- Substantial similarity. The plaintiff also needs to prove there are “substantial similarities between the defendant’s work and original elements of the plaintiff’s work.” The Feist v. Rural U.S. Supreme Court Opinion states that this similarity must be the result of actual copying and not fortuitous similarity: In their words: “assume two poets, each ignorant of the other, compose identical poems … both are original and, hence, copyrightable.”
A natural candidate to capture the notion of access is to say that a generative model 


Some of these transformations result in significant Hamming distance, though they can all be captured in only a few bits of information. Rather than wade into these issues, we use the fact that generative models are inherently probabilistic. Hence we can use distance measures between distributions that are information-theoretic and agnostic to superficial issues such as pixel-based representations. Our formalization is the following:
Definition 1 (Near Access Freeness – NAF): Let 
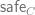


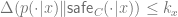
This definition reduces the task of determining a copyright infringement to (1) a quantitative question of the acceptable value of 
Definition 1 is stringent in the sense that it bounds (by
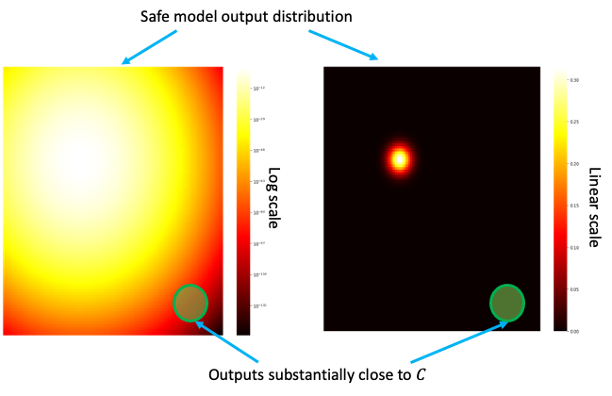 , which was trained without access to a given copyrighted piece of data . It is reasonable to expect the probability of outputs of the model would assign an exponentially small likelihood to any outputs that are substantially similar to . Hence a probability distribution that has bounded divergence from the safe model would also be extremely unlikely to output those.
, which was trained without access to a given copyrighted piece of data . It is reasonable to expect the probability of outputs of the model would assign an exponentially small likelihood to any outputs that are substantially similar to . Hence a probability distribution that has bounded divergence from the safe model would also be extremely unlikely to output those. Algorithms
Given the restrictive nature of the definition, one may be concerned that trying to achieve it would result in losing much of the utility of the original generative model. Fortunately, as our work shows, this is not the case. We provide several algorithms that can transform, in a black-box manner, any training pipeline for a generative model into one that produces models that have strong copyright protections under our definition. We now illustrate two of these:
Algorithm 
Input: A dataset 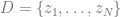
Learning: First de-deduplicate 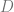




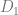
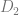
The Output Generative Model: Return the generative model 
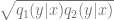
Note that for any copyrighted work 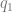
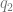


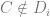
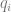
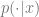
The intuition is provided in the following animation
and with a range of spike locations. We see how the distributions proportional to  and
and  significantly “flatten” these spikes.
significantly “flatten” these spikes.Imagine that both 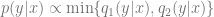
There a number of modifications to 
Algorithm 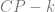
Input: A model
Learning: First de-deduplicate
The Output Generative Model: Return the generative model 
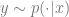
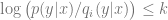
The intuition of 
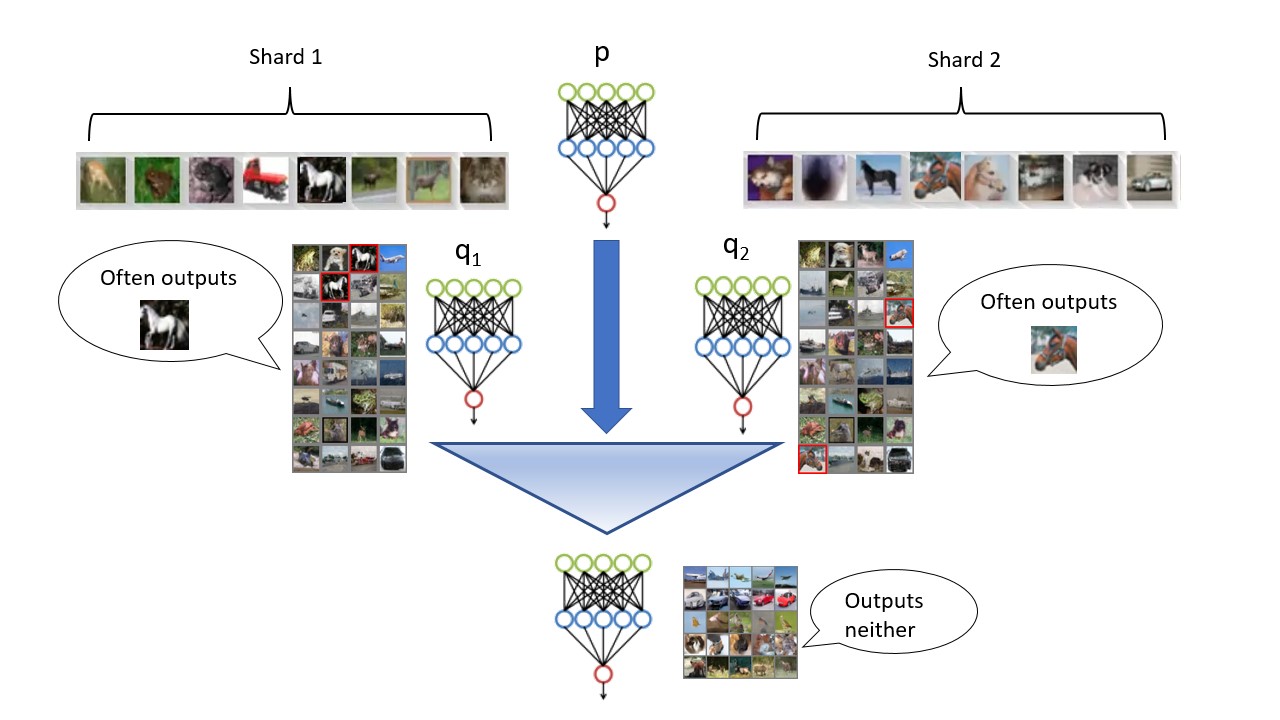
An Illustrative Experiment
 trained on the full modified CIFAR10 dataset; we injected multiple copies of two images (marked with red frames), so they are likely to be memorized by the model. Middle two images: Models
trained on the full modified CIFAR10 dataset; we injected multiple copies of two images (marked with red frames), so they are likely to be memorized by the model. Middle two images: Models 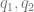 trained on two shards of the dataset, split so that each injected image appears in only one of them. Right: A model obtained by combining
trained on two shards of the dataset, split so that each injected image appears in only one of them. Right: A model obtained by combining  using our algorithm. Despite being a black-box transformation of the three memorizing models, the combined model does not output either of the injected images.
using our algorithm. Despite being a black-box transformation of the three memorizing models, the combined model does not output either of the injected images.We now present a qualitative experiment demonstrating how applying our algorithm to memorizing models produces a model that no longer memorizes. Specifically, we first augment CIFAR-10 with multiple copies of two images (images close to the augmented images are marked with red boundaries); hypothetically, suppose these two images are copyrighted works. For illustrative purposes, we do not deduplicate our dataset. Note our goal here is not to simply present a heuristic approach, such as deduplication, that “often works in practice,” but it is to show that an algorithm with rigorous guarantees can also be practical.
The leftmost image shows generations from a model 
See the paper ( https://arxiv.org/abs/2302.10870 ) for the full details of our definitions, theorems, and experiments. We believe that there is much room for follow-up work, including optimization of performance, as well as much larger-scale experiments.
