Update (5/7): This post earned me a spot on the not-so-exclusive club of people called names such as a “narrow-minded” “biased” “religious worshiper” “who doesn’t want to learn something difficult and new” by Luboš Motl. Interestingly, he mostly takes issue with my discounting the possibility that the complexity of SAT is something like  or
or  . Although I do believe such an algorithm is extremely unlikely, its discovery wouldn’t be a bad thing to computational complexity. On the contrary, I imagine that if such an algorithm is discovered then investigating whether it can be improved and implemented would be seen as meriting the investment of a huge amount of resources, possibly larger than those given for the Large Hadron Collider.
. Although I do believe such an algorithm is extremely unlikely, its discovery wouldn’t be a bad thing to computational complexity. On the contrary, I imagine that if such an algorithm is discovered then investigating whether it can be improved and implemented would be seen as meriting the investment of a huge amount of resources, possibly larger than those given for the Large Hadron Collider.
[ First, an announcement. Mark Braverman and Bernard Chazzelle are organizing a workshop on May 20-21 on Natural Algorithms and the Sciences , bringing together researchers from computer science, mathematics, physics, biology, and engineering to explore interactions among algorithms, dynamical systems, statistical physics, and complexity theory (in all senses of the term) ]
In some very pleasant though unsurprising news, Scott Aaronson got tenure at MIT. Among his many talents and activities, Scott has done a fantastic amount of outreach and exposition, explaining the concepts of theoretical computer science and quantum computing to other scientists and interested laymen. He also spends considerable energy trying to dispel wrong opinions with amazing patience and resilience (apparently due to his immutable psychological makeup). So, in honor of Scott getting tenure, just after a bruising flamewar with various “interesting characters” he managed to find in some dark corner of the Internet, I thought I’d step up to help him along and try to do my share of dispelling some common myths about complexity and particularly the 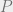 vs
vs 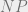 problem.
problem.
P vs. NP: Reasons to Care
The  question (and its close variants) is the central question of computer science. In fact, its hard to think of another question in any field that combines such mathematical depth and beauty with great importance to understanding nature. Scott did a pretty good job explaining why
question (and its close variants) is the central question of computer science. In fact, its hard to think of another question in any field that combines such mathematical depth and beauty with great importance to understanding nature. Scott did a pretty good job explaining why  is true. In this brief post I’ll try to outline why I and many others are so intrigued by this question, by trying to answer various objections that are commonly made against its importance. Some of these issues are mentioned in my book with Arora but I thought a more explicit discussion might be worthwhile.
is true. In this brief post I’ll try to outline why I and many others are so intrigued by this question, by trying to answer various objections that are commonly made against its importance. Some of these issues are mentioned in my book with Arora but I thought a more explicit discussion might be worthwhile.
What if = but the algorithm for SAT takes or time?
In other words, what if SAT has exponential complexity for all inputs up to size 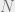 for some huge number , and only starts becoming comparatively easier after that number. This is the equivalent of asking what if the laws of nature we’ve learned so far are true only in the corner of the universe we’ve managed to observe, and are completely different in other areas. Yes, this is a logical possibility, but we have not seen the remotest reason to believe it. Also, in recent years we’ve been exploring the computational universe (in terms of the huge growth of input sizes and computational resources) at a much faster rate than the physical one, and as we do so, it only becomes more important to understand the asymptotic behavior of algorithms. Having said that, I agree that after proving
for some huge number , and only starts becoming comparatively easier after that number. This is the equivalent of asking what if the laws of nature we’ve learned so far are true only in the corner of the universe we’ve managed to observe, and are completely different in other areas. Yes, this is a logical possibility, but we have not seen the remotest reason to believe it. Also, in recent years we’ve been exploring the computational universe (in terms of the huge growth of input sizes and computational resources) at a much faster rate than the physical one, and as we do so, it only becomes more important to understand the asymptotic behavior of algorithms. Having said that, I agree that after proving 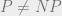 , the next order of business would be to get a more precise estimate of the number of computational operations needed to solve length-
, the next order of business would be to get a more precise estimate of the number of computational operations needed to solve length- instances of SAT as a function of .
instances of SAT as a function of .
The question is irrelevant since is only a mathematical model having nothing to do with efficient computation.
The universality of computation, leading to equivalent models whether you study Turing machines, cellular automatons, electronic computers, mathematical deduction systems, or computation by natural systems (see workshop above) or economic markets, has been a surprising and central phenomena, validating the formal study of Turing machines or Boolean circuits. But I do agree is an imperfect model for efficient computation. Yet it is still a fine tool for the question of studying the complexity of SAT or other NP-complete problems. It’s true that is often too permissive a model, allowing algorithms that are prohibitively expensive to run on today’s technology, but this is not as much of an issue when the question is whether you can beat the exponential-time brute force algorithm. (Indeed, it has been often observed that natural problems either have fairly efficient algorithms with 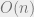 or
or 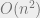 running time, or seem to have exponential (i.e.,
running time, or seem to have exponential (i.e.,  ) complexity.)
) complexity.)
Perhaps a more serious concern is that may be too restrictive, since it does not allow taking advantage of quantum mechanics (or maybe other physical theories), and is also only concerned with worst case computation. While those concerns are valid in principle, it seems that while quantum computers can do wonders for certain structured problems such integer factoring, their effect on NP-hard problems such as SAT is fairly limited. Also, while it is possible to posit a theoretical world in which but every problem is easy to solve on the average, the evidence so far strongly points to that not being the case. So, while one can argue that instead of we should be asking what’s the size of the smallest quantum circuit that solves SAT on the average case, all evidence points out to these two questions having the same answer. Moreover, at the moment we’re so far from resolving either question that the tools we have to study all those variants are the same. When we start getting close to , we might want to try to understand the more refined variants such as quantum or average-case complexity.
is not a fundamental property of nature such as the physical laws.
“Fundamental” is a subjective term, and can be used in different senses. The fundamental theorem of algebra can be (and is) derived from more basic axioms, and so this theorem is fundamental not because it’s the foundation for all algebraic facts but because it is central and important. One can make a similar analogy between “high level” laws of nature, positing the impossibility of perpetual motion machines or devices that transmit information faster than light, and the laws governing behavior of elementary particles that may be used to derive them. , positing (essentially) the impossibility of a machine that gets a SAT formula and spits out a satisfying assignment, is comparable to these high level laws in flavor, and I would say also in importance.
is only about practical efficiency whereas the deeper / more fundamental question is which computational problems can be solved at all.
I don’t think anyone that actually studied complexity for even a short while would share this objection. To paraphrase Edmonds (whom we quote in our book), in many contexts the difference between polynomial and exponential is more significant than the difference between exponential and infinite. An example we give in the book is Arthur Ganson’s kinetic sculpture Machine with Concrete. It’s composed of a sequence of 12 gears, each rotating 50 times slower than the previous one. While the first gear rotates 200 times per minute, the last one, at 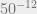 that speed, is to all practical purposes stationary, and indeed is embedded in a block of concrete. So, exponentially hard problems are essentially unsolvable. But it turns out that in most cases the problems we want to solve (from simulating the physical world to finding if there is an input making our program take more than
that speed, is to all practical purposes stationary, and indeed is embedded in a block of concrete. So, exponentially hard problems are essentially unsolvable. But it turns out that in most cases the problems we want to solve (from simulating the physical world to finding if there is an input making our program take more than  units of time) are trivially computable, so in such cases the interesting question is whether their complexity is polynomial or exponential.
units of time) are trivially computable, so in such cases the interesting question is whether their complexity is polynomial or exponential.
A related concern is that only involves “elementary” mathematics, as opposed to “deep” questions such as, say, the Riemann hypothesis. While the terms “deep” and “elementary” are not well defined (it seems that, similar to the AI effect, some people consider every problem or result in fields they don’t like as “shallow”), I believe it is again the case that this is not a concern shared by people that actually studied computational complexity. While this field is very young, it already contains several deep and beautiful results, and it is clear that many more will be needed for us to approach resolving 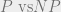 .
.
Resolving is not interesting, since we already know the answer is that .
I can sympathize with this objection, as I too firmly believe that and in fact I believe that concrete problems such as, say, CIRCUIT-SAT cannot be solved in subexponential time. The reason we are looking for the proof is not just to get an extra level of confirmation to what we already know, but because we believe coming up with such a proof will necessarily have to yield new deep insights about the nature of computation. It is impossible to predict what would be the nature of such insights or what would be the extent of their applications; but in particular a better understanding of the dividing line between easy and hard problems can yield on the one hand new algorithms, and on the other hand new encryption schemes that are provably impossible to break.
Even if =, we wouldn’t necessarily be able to automate creativity, find hard proofs, beautify symphonies etc..
Some people making this objection are really thinking of the first objection, namely that  but the algorithm is so inefficient that it still holds that in the “observable computational universe”. Others note that it’s not immediately clear how you use an algorithm for SAT to do things such as perfect artificial intelligence, weather prediction, etc… Lance Fortnow has a nice description in his book of a universe in which (see also Impagliazzo’s survey). Indeed, given the vast amount of NP-complete problems from all science, combined with the ability (if ) to solve even problems higher in the polynomial hierarchy, I think it’s hard to overestimate the implications of an efficient SAT algorithm. But I still do not see achieving this ideal world as the main reason to study . As I said, even if we don’t have a formal proof, there are plenty of reasons to believe that . So, I view the fact we can not rule out this hypothetical computational utopia not as a sign that it might be true but rather as demonstrating how much is still left for us to discover in the world of computation.
but the algorithm is so inefficient that it still holds that in the “observable computational universe”. Others note that it’s not immediately clear how you use an algorithm for SAT to do things such as perfect artificial intelligence, weather prediction, etc… Lance Fortnow has a nice description in his book of a universe in which (see also Impagliazzo’s survey). Indeed, given the vast amount of NP-complete problems from all science, combined with the ability (if ) to solve even problems higher in the polynomial hierarchy, I think it’s hard to overestimate the implications of an efficient SAT algorithm. But I still do not see achieving this ideal world as the main reason to study . As I said, even if we don’t have a formal proof, there are plenty of reasons to believe that . So, I view the fact we can not rule out this hypothetical computational utopia not as a sign that it might be true but rather as demonstrating how much is still left for us to discover in the world of computation.

I *do* think it’s easy to estimate the implications of an efficient SAT algorithm. Let’s say that indeed you have a 100(m+n)-time algorithm for n-variable, m-clause 3Sat instances in some nice fixed RAM model. What things *definitely* will happen, and what things only *might* happen?
Definitely will happen:
1. Cryptography will be in big trouble and we’ll probably have to go back to security via physical means.
2. Operations research/industrial engineering stuff will get notably better. For example, I expect that UPS will be able to route their trucks maybe 5% more efficiently, which is worth many millions.
3. We will learn the correct answer to many famous math problems (i.e., we’ll almost surely learn that the Riemann Hypothesis is true, that the Twin Primes conjecture is true, etc.)
Maybe will happen:
. We’ll get a human-understandable proof of the Riemann Hypothesis.
Very unclear to me if it will happen:
. Automatically generating new Shakespeare plays, automatic translation between human languages, curing all diseases, etc. etc.
@Mr. O’Donnell: What would be the connection between finding the causes and cures for diseases and computational ability or the lack thereof? If you look at the list of diseases that modern medicine has no clue as to the cause , it is VERY long.
Ryan, I agree the immediate consequences are what you mentioned, but what’s harder to guess are the less immediate ones. For example such an algorithm would yield “perfect machine learning” of any hypothesis class under any noise model from the minimal necessary amount of examples. I don’t know all the applications of this, but translation between human languages sounds quite plausible. (In fact there have already been many advances in machine translation even without a perfect SAT solver.)
Similarly such “perfect machine learning” can help us use measurements to generate computer models of complex systems such as the brain and other biological systems, thus replacing “wet labs” with computer simulations (which themselves could be exponentially faster to execute using SAT). It seems reasonable this would significantly advance the pace of science, and potentially also help in finding cures for diseases.
From what little I know, it seems to me that what real-world machine learners suffer from is a lack of enormous amounts of labeled data rather than lack of fast algorithms. (Natural language translation was probably not a great example on my part, though, because we actually *do* have quite a lot of labeled data there.)
I doubt machine learners currently use the information-theoretic minimum number of examples. I think there is some computation vs number of examples tradeoff, where people use many more examples than strictly necessary for identification in order to enable efficient learning (e.g. in order to handle noise and to be able to use simple hypothesis classes).
In particular the “deep learning” method seems to use vast amount of computational resources, so the bottleneck does not seem to be only availability of data.
I’m a bit confused by your second answer:
and only starts becoming comparatively easier after that number…. Yes, this is a logical possibility, but we have not seen the remotest reason to believe it.
Wouldn’t the four colour theorem style proof be a good example of this behaviour? Recall that the proof consists of manual examination of a few hundred base cases. Hence solving a graph instance for n=6 or 7 can be done faster by exhaustive enumeration of all colourings while for large n, (e.g. n=1,000,000) it is easier to do a complete proof of the theorem and then run the polynomial time algorithm induced from the minors in the proof on the specific graph instance.
Similarly, why could this not be the case for SAT formulae? Let’s say for the sake of the argument that there are 1,000,000,000 basic cases in the implication/clause graph, and hence for small formulas one is better of launching some sort of guided search of the entire 2^n assignment space. In contrast for larger instances we search for the “minors” (so to speak) that would imply the formula is a contradiction and if none are present then the formula is satisfiable?
p.s. otherwise an excellent article and I’m very much in agreement with the message that P vs. NP is a fundamental problem in science.
I’m a bit confused by your second answer:
and only starts becoming comparatively easier after that number…. Yes, this is a logical possibility, but we have not seen the remotest reason to believe it.
Wouldn’t the four colour theorem style proof be a good example of this behaviour? Recall that the proof consists of manual examination of a few hundred base cases. Hence solving a graph instance for n=6 or 7 can be done faster by exhaustive enumeration of all colourings while for large n, (e.g. n=1,000,000) it is easier to do a complete proof of the theorem and then run the polynomial time algorithm induced from the minors in the proof on the specific graph instance.
Similarly, why could this not be the case for SAT formulae? Let’s say for the sake of the argument that there are 1,000,000,000 basic cases in the implication/clause graph, and hence for small formulas one is better of launching some sort of guided search of the entire 2^n assignment space. In contrast for larger instances we search for the “minors” (so to speak) that would imply the formula is a contradiction and if none are present then the formula is satisfiable?
p.s. otherwise an excellent article and I’m very much in agreement with the message that P vs. NP is a fundamental problem in science.
The 4 color theorem is a nice example, but even here, the number of basic cases (and the running time of the algorithm) have been significantly improved since the first Appel-Haken result, and there may very well be future improvements. (For example, in many interesting cases where there is an algorithm based on the Robertson-Seymour theorem using a huge number of basic cases, there are also more direct algorithms.) So, I still think that there is very little reason to suspect that the best algorithm for SAT would require a truly humongous number of basic cases.
They number of cases has gone down but only to 633 from the 1,936 cases in the original 1976 proof, with progress last made in 1996. Hard to deduce from that that it will go any lower.
Moreover I heard at least two experts declare that they expect the number of irreducible cases to be no lower than 150 or so even under somewhat optimistic assumptions. This would still leave the possibility of “for small cases exhaustive search is best, for large cases use complicated ‘minor’ induced method” wide open, don’t you think?
I guess one of the first things we’ll do with a SAT algorithm is try to find if there is a shorter, completely different proof of the 4 color theorem 🙂
I agree one can imagine that there exists an efficient algorithm for SAT that has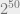 basis cases or so, but still disagree this is in any way likely. (Of course, I also don’t think it’s likely that SAT has an efficient algorithm without such a “fat base” inductive structure.)
basis cases or so, but still disagree this is in any way likely. (Of course, I also don’t think it’s likely that SAT has an efficient algorithm without such a “fat base” inductive structure.)
Of course, I also don’t think it’s likely that SAT has an efficient algorithm without such a “fat base” inductive structure.
Exactly, we searched the simple cases for long enough to nearly discard the possibility of a low degree simple algorithm without a ton of base cases.
I say “nearly” because the beautiful primality testing algorithm of Agrawal, Kayal and Saxena ended up being much simpler than I ever thought possible, so you never know.
BTW there is another issue why I think it would be unlikely that SAT has a 4-color-type “fat base” algorithm. I don’t know if this is the case for the 4 color theorem, but it makes to me intuitive sense that even when the worst-case algorithm needs a huge number of base cases, there are simpler heuristics that work on instances that are “typical”, “generic” or “arising in practice”. In contrast for SAT, not only do we not know of a worst-case algorithm, we also have fairly simple ways to generate random instances that fool any known algorithm (e.g., using sparse parity with noise or Feige’s hypothesis). To me, this makes it less likely that a huge number of base cases will help for SAT.
Interesting argument. You are aware I’m sure that current SAT solvers are quite good on real life instances. Having said that I’m not sure if I take this as evidence for or against a fat base case algorithm (or neither).
Maybe this is very wrong, since it just occurred to me on the spot, but let’s say for the sake of the argument that—modulo some minor reductions and boundary cases—every SAT “graph” that doesn’t contain a large simple minor (say a clique on 100 vertices) is satisfiable.
Wouldn’t this be perfectly consistent with an n^100 algorithm since CLIQUE is W[1] hard?
SAT solvers do very well on some of the instances that are given to them, or perhaps the other way around – people have become good at understanding what are the kind of instances on which SAT solvers stand a chance. However, it’s very easy to generate instances on which they’ll choke.
Your conjecture that every unsatisfiable formula has a local obstruction, if true, would imply that one can certify that a formula is unsatisfiable via an 100 round linear (or semidefinite) program. Such algorithms have been ruled out unconditionally.
Your conjecture that every unsatisfiable formula has a local obstruction
I didn’t mean it quite that literally, which is why I always placed quotes around ‘minor’. It could be that the reductions and “contractions” allowed are quite different than those of minors and thus not a local obstruction in the strict sense of the term nor do they lead to a linear or semidefinite program.
I should add that I do not hold that P=NP nor do I suggest that it can be solved using minor-like techniques. My point is that perhaps that avenue isn’t as closed down by current evidence as you think.
Certainly the discussion so far has been very enlightening.
Thank you Alex for these comments and the discussion! I agree that we should be (and in fact are) studying various restricted algorithms for SAT. Even if they can’t solve the problem completely, they might solve it on interesting classes of instances, or help us understand better why it’s hard.
The reason for the current lower bounds, which might hold at last for some more general notions of “minors” and “contractions” is that if you look at a subformula of size 100 (or even n/100) of a random SAT formula with 10n clauses, then it looks pretty much like a random subformula and doesn’t tell you that the formula is unsatisfiable (which it will be with high probability). In fact, I haven’t verified this but I believe one can show that if you “plant” a solution in such a formula (in the right way), then the distribution it induces on the window is statistically close to the distribution induced by a random formula.
As perhaps you can tell, I haven’t thought as deeply on this issue as you have. So with that caveat, here’s my question: wouldn’t your last argument apply to the clique of size 100 *** as well? It seems to me that if you were to grab a random subset of the graph it wouldn’t look like a clique, but if you grabbed the right subset you would find the clique and determine its unsatisfability?
*** where by “clique of size 100” I mean some minor-like graph property that is hard to check for small exponent but easy to check for large exponent.
You are right – I should have been more careful and gave a statement that allows to choose the subset *after* the choice of the formula.
Let me give a higher level description of the issue. When you select a random 3SAT formula of 100n clauses, we know it’s likely unsatisfiable by a chernoff bound combined with a union bound over all possible 2^n assignments.
This seems to be a very non-constructive and also “global” argument, in that that if we looked at k<<n clauses, then there simply wouldn't be enough random bits in the choice of that subformula to do such a union bound.
What formally people show is that the clause-vs-variable in such a formula is a very strong expander, which means that if you take a set S of such k clauses then almost every clause in S involves a "unique neighbor" variable that is not touched by any other clause in S. Therefore its trivially easy to satisfy by assigning an appropriate value to this variable. This argument ends up generalizing to rule out various LP and SDP hierarchies, and I think would work for at least some definitions of "minors".
That said, I wouldn't want to discourage you or anyone from trying to find such an algorithm, which as far as I know, may well exist. The only thing I would suggest is that if you have a candidate algorithm, these random unsatisfiable formulas would be a good test inputs to try it on.
there are at least 137672 automated creative machines, finding hard proofs. You either need to explain how they work, or discount this argument. I see very little interaction of complexity theory and human cognition/perception/action. I also see that computer programs are inferior to the humans in this respect (otherwise we would have computer repository of hard proofs growing faster than human written journal papers) (http://mathoverflow.net/questions/5485/how-many-mathematicians-are-there)
Boaz, on behalf of the International Association of Luboš Motl Insultees, we’re deeply honored to welcome you as our newest member.
Like many engineers, I immensely enjoy and learn greatly from both Arora and Barak Computational Complexity: a Modern Approach (2009) and Juris Hartmanis’ older monograph Feasible Computations and Provable Complexity Properties (1978).
That is why, if an infallible mathematical oracle magically appeared, and offered to evaluate one (and only one) complexity-theoretic postulate as either “true”, “false”, or “undecidable”, in the context of any formal system of logic that I cared to specify, then it would be mighty tough (for me anyway) to choose between the Arora/Barak textbook statement of the P ≠ NP postulate (which is equivalent to Steven Cook’s Millennium Prize statement of it) versus the following postulate that is distilled from Hartmanis’ monograph:
The choice is tough because it is consistent with present knowledge of complexity theory — as I incompletely appreciate that knowledge — to regard the Arora/Barak/Cook oracular P ≠ NP postulate and the Hartmanis little P ≠ NP postulate as logically independent of one another.
That is why the oracle-question choice boils down to a pragmatic decision: which of these two postulates is more useful and/or beautiful? Reasonable opinions may differ, but from an engineering perspective, the Hartmanis-style “little” P ≠ NP postulate is preferable in both regards.
Therefore, if it should happen that a second edition of Arora and Barak ever appears, it would be terrific if these tough oracular-choices were discussed in it! In the meantime, thank you for a wonderful textbook, that has so greatly assisted very many folks (including me) to a better appreciation of complexity theory.
I strongly agree about the importance of the P vs NP problem and I have great admiration for Scott and others who take their time to explain why this is a fundamental question. I disagree however with the very strong bias towards P not equal to NP. The main reason is probably because different people have different criteria for what evidence is. In particular, with respect to this post, I disagree with the comment that the question of whether SAT has a big exponent is the equivalent of asking what if the laws of nature we’ve learned so far are true only in the corner of the universe we’ve managed to observe, and are completely different in other areas. I guess we could paraphrase this to say, if all the sheep we see in the world is white, there would be no good reason to think that there are also some black sheep in the world. But what if we have good reasons to think that we as humans have some sort of a deficiency regarding seeing black sheep? What if we are only good at seeing white sheep? I think we have a similar issue regarding P vs NP problem. There seems to be a very strong bias towards algorithms with small exponents. The bias is understandable because these are the algorithms that our homo sapien brains can understand. And it is, in my opinion, no surprise that all the efficient algorithms that we have been able to come up with have low exponents. The land of algorithms with large exponents is completely dark to us (I would consider e.g. 20 to be a large exponent). For me, it would be surprising that every “natural” problem solvable in P has a small exponent, because I have no reason to expect this. I guess we differ in how capable we think the human brain is.
I don’t know if “having small exponent” and “easy for humans to understand” are the same thing.
Often it has been the case that people first discovered algorithms with larger exponent and then with much work got the exponent down.
Also, for some classes of problems (e.g., constraint satisfaction problems) there are proven or conjectured *dichotomies* in which every problem in that class either has an algorithm with a low exponent or is NP-hard.
That said, I’m sure there are some natural problems whose best algorithm has a large exponent, or even a weirder complexity function such as exp(exp(sqrt(log n))) etc.. I just don’t think SAT is one of them.
Also, relating to the larger point of this post, I don’t think that the interest in complexity theory is dependent on the assumption that SAT has either O(n) or 2^{Omega(n)} complexity. At its heart, the P vs NP question is to determine the computational difficulty of SAT and other NP-hard functions, whatever that difficulty turns out to be. If it’s going to be surprisingly smaller than 2^n, whether because its 100*n, its 2^{sqrt{n}}, or n^{1000}, that’s going to be a super interesting result and only a reason to care more about it.
[First, a typo correction: in my first comment I mistakenly wrote “I do think it’s easy to estimate the implications of an efficient SAT algorithm”. As you can tell from the rest of the comment, I meant to say, “I do think it’s easy to *over*estimate the implications of an efficient SAT algorithm”.]
Boaz, what do you estimate as the probability that P = NP? How low a probability do you think it’s reasonable to argue for?
I ask because by chance I had exactly this kind of discussion with Eli Ben-Sasson last week. His opinion (I think) was extremely similar to Anıl’s. So that’s at least two respected complexity theorists who honestly find no particular reason to disbelieve P = NP. Personally, I disagree with them, but they’re entitled to their opinions. (And really, the whole discussion of the “probability a statement is true” can only be just for jokes, but at least it’s fun.) In particular, if Eli or Anıl says “My gut TCS intuition simply does not accept the commonly proposed evidence in favor of P \neq NP” then what can you say?
OTOH, Eli at least said that if forced to bet, he’d bet in favor of P \neq NP. But maybe he’d give it 70%, and 30% for P = NP? I don’t know. I think Anıl once told me he felt it was 50-50.
Anyway, I give the probability of P = NP something like 2%. And I would question anyone who put it at 20%, OR at 0.2%. 🙂
I think if I was forced, I would also say P \neq NP is more likely. But if it was shown that P = NP, I wouldn’t be surprised. I think in this sense I said 50-50 but 70-30 probably reflects my beliefs more accurately. I think it is fine to conjecture that P \neq NP, but I don’t agree with treating it as a certainty that we don’t know how to prove. For example, I don’t understand the fifth objection above: “Resolving P vs NP is not interesting, since we already know the answer is that P \neq NP” because for me this implies that we have a very good understanding of computation, and I strongly disagree with this.
I strongly believe P\neq NP but it’s hard for me to put probabilities on that.
I can try to gauge the “shock value” of P=NP, in terms of how deeply I would be surprised.
I would find P=NP to be a surprise on a whole different level than, say, the discovery of an efficient algorithm for factoring integers or discrete log. But yet even the latter would also be considered a huge surprise not just to me, but to the entire field. (In fact, there is a whole industry dependent assuming that can’t be done, without much mechanisms for fall back.)
Somehow I feel that if P=NP, we should have seen some “canary in the coal mine”, an algorithm that seems to beat brute force for general problems, some experimental results, etc.. (There was the “survey propogation algorithm” that did better than expected on random satisfiable 3SAT, but it seems to be something about the quirks of random 3SAT, that doesn’t even apply to random 10SAT or to the unsatisfiable, Feige-Hypothesis, range of parameters.)
As a more general philosophy, which is also the point I was trying to make in the previous post, I think that while it’s good to keep an open mind about things, it’s also good not to have rigorous proofs as our only standard of evidence. So, currently the scientific theory that is supported by the evidence is P\neq NP, though it’s true that it could be overturned in the future (like any other scientific theory in areas other than math).
But again, if you believe that there is a noticeable chance for P=NP, then of course it only makes studying the question more interesting.
This is reasonable response. I definitely agree with you that people need to cut us some slack when it comes to “evidence in favor of P \neq NP”. Given that we cannot prove anything close to the theorem (or its negation), one ought to be a bit lenient when it comes to accepting evidence.
OTOH, I also like Anıl’s comment below.
Maybe I should say a few words on why I am a skeptic. I think in complexity theory we have several surprising results (in hindsight you might say they are not surprising but they were surprising at the time they were discovered). As far as I know all the surprises (with respect to two classes being the same or not) have been on the upper bound side. I don’t think there has been a case where we thought two complexity classes were equal and then surprisingly we showed a lower bound. So it seems our intuition is biased towards complexity classes being separate. The surprising upper bound results teach us that computation can do tricky things. We have been lucky to discover a few but it is reasonable to think that there are so many more yet to be discovered. I think this is more so the case when we talk about very powerful complexity classes like P. As you give an algorithm more power, the more tricky things it can do. And at some point, I think it probably can do things that our very limited brains cannot even begin to comprehend. And I think algorithms in P are very capable of delivering such things. For this reason, if SAT is in P, I don’t really have a good reason to think that the algorithm that solves SAT is within the reach of my understanding. There are of course many algorithms in P that we do understand or we can hope to understand, but I don’t have any good reason to believe that the algorithm for SAT should be one of them.
Given this, the fact that we have not been able to make any algorithmic progress on the P vs NP question is only a very weak form of evidence for me. It moves me from 50-50 to 60-40. Scott gives other reasons to believe P \neq NP here: http://www.scottaaronson.com/blog/?p=122
These arguments move me to 70-30 mainly because of number 5 on the list.
Let me add that I strongly agree with Boaz that the importance of the P vs NP question does not depend too much on the true complexity of SAT. Whatever the answer turns out to be, it will be extremely enlightening.
This is a nice post, Boaz, and I think that few people doubt that the NP=!P conjecture is an important mathematical conjecture which is central to computer science.
Here are a few comments (I did not follow the prior blog discussions so the comments are just on what you write):
1) Arguably the fundamental achievement was to formally introduce P and NP, formulate the NP=!P conjecture, and understand its vast formal and informal implications, connections, and ramifications. Perhaps, this vast conjectural picture and theory around it are even more important that a proof will be but this is yet to be seen.
2) As a mathematical conjecture, the NP!=P is a great question. One concern about it though is that it does not interact so well with the rest of mathematics.
3) P can be permissive in another sense. It is quite possible that there are algorithmic tasks in P where finding the P-algorithm is intractable. For example, if the P-algorithm depends on a secret that if we don’t know we need exponential search to find. This can apply to algorithms for natural processes where we try to repeat things that nature easily does, but don’t have access to some important hidden parameters.
4) Computational complexity is an important thing but it is not the only important thing. When you ask which computational problems can be solved at all, the main issue is not if an exponential task can be done in polynomial type. Our inability today to give an accurate weather forecast for May 9 2014 is not a computational complexity issue. (Not even in principle.)
5) The creativity connection to NP=!P is at best a metaphor You could have used computability or the gap between linear and quadratic algorithms equally well for that metaphor Creative people do not solve intractable computational problems. It is correct that an efficient NP algorithm will enable to prove quickly and mechanically the Poincare conjecture, but it will also allow us to perform tasks that are much harder, have no creativity flavor, and are beyond the ability of the most creative person (or computer) like to find the shortest proof, in a prescribed proof system, for the Poincare conjecture. There is no reason to think that any aspect of human creativity involves solving computational intractable questions, and in spite of NP not being P it is likely that computers can actually perform various creative human activities.
Perhaps, this vast conjectural picture and theory around it are even more important that a proof will be but this is yet to be seen.
I believe that by the time we get a proof, this conjectural picture will only be a small part of the new things we’ll learn about computation, but this of course purely speculative.
For example, if the P-algorithm depends on a secret that if we don’t know we need exponential search to find.
This seems to apply more to non-uniform computation, which is the class P/poly. For P we assume that the algorithm has a absolute constant description size that does not depend on the length of the input.
Our inability today to give an accurate weather forecast for May 9 2014 is not a computational complexity issue.
Obviously if the output we try to compute is not determined by the input then no computation can help. I don’t know if that’s the case or not for weather prediction. As I commented above in the discussion with Ryan, though I am not an expert on machine learning, I believe an algorithm for SAT will certainly help in many prediction tasks. In particular, I think sometimes the problem is finding which features in the data are relevant for the prediction, something that you could do if you had a SAT algorithm.
There is no reason to think that any aspect of human creativity involves solving computational intractable questions
I don’t think creative people have a systematic way to solve intractable questions, but in some cases (like the proof of the Poincare conjecture), they manage to stumble upon the solution. I agree that computers could also do the same even without P=NP, but would be much better at it with an efficient SAT algorithm.
@Gil: Hello Mr. Kalai, Could you also have a case where some psuedorandom number generator was proven to be unbreakable in polynomial time but the generator has no apparent relationship to any other problems in NP ? In other words it would be some kind of “special case” that has a proven lower bound but the lower bound proof could not be applied to NP complete problems. Thanks!
NP-complete problems are the hardest problems in NP. So if you prove that there exists a pseudorandom generator you’ve also proven that P is different from NP and that all NP-complete problems are not in P.
Mr. Barak, thank you for the reply. I still don’t understand the relationship between psuedorandom generators and NP complete problems but you are a professional computer scientist so I will take your word for it ! 😉
This appears in several textbooks and lecture notes (including my own), see for example third slide here http://cosec.bit.uni-bonn.de/fileadmin/user_upload/teaching/07ss/cryptabit/Cryptabit06/LcCharles_Tue.pdf
(note that there different variants of pseudorandom genrators, but am talking here about the variant used for cryptography, others need only milder assumptions such as P different from EXP).
Dear Boaz, I think we are in agreement in strongly believing that NP is different than P, and that finding efficient algorithm for NP-hard problems will have amazing consequences. And also that this is a very interesting and important question.
“I don’t think creative people have a systematic way to solve intractable questions, but in some cases (like the proof of the Poincare conjecture), they manage to stumble upon the solution.”
Here we disagree. Whether you are creative or not, there are no systematic ways to solve intractable questions, or any good chance to stumble upon the solution. (This is why they referred to as intractable.) The Poincare conjecture is simply not intractable. Creativity is related to the phenomenon that verifying is easier than finding, but it is not related to intractability.
We can have some ideas about mathematical questions that are indeed probably intractable, like computing the Ramsey number R(50,50) or finding the length of the shorter proof of the prime number theorem in a prescribed proof system. And indeed, these tasks will not be achieved systematically or by chance, by creative people or by other people or by computers.
“Obviously if the output we try to compute is not determined by the input then no computation can help.”
Yes, but this is a huge issue in the larger area of computation, related to modeling, numerical analysis, chaotic behavior etc. We should care about it too!
“For P we assume that the algorithm has a absolute constant..”
That’s correct, but when we apply insights from cc to real-life problems we obtain distinction between huge intractable constants and constants within reach. If you need to recover the (polynomial) algorithm performed by an unknown computer chip and need to go over all the possible chips of the same size, this is intractable (yet constant), and you may have similar issues for algorithms for natural processes.
“I believe that by the time we get a proof, this conjectural picture will only be a small part of the new things we’ll learn about computation, but this of course purely speculative.”
This is certainly a terrific possibility!
If you need to recover the (polynomial) algorithm performed by an unknown computer chip and need to go over all the possible chips of the same size, this is intractable (yet constant), and you may have similar issues for algorithms for natural processes.
This is an argument why in certain cases P/poly is a better model for “efficient computation” than P. Indeed typically in cryptography, we would like our algorithms to be in P (i.e., explicit algorithm with no large parameters) but want them to be secure even against adversaries in P/poly (even against natural or artificial processes that have large parameters.
Whether you are creative or not, there are no systematic ways to solve intractable questions, or any good chance to stumble upon the solution.
Maybe the issue here is my complexity/cryptogaphy background. I think of an “intractable problem” as a question of mapping inputs to outputs (which in the case of NP have some efficiently verifiable relation between them). The problem is intractable because there is no efficient way that *always* (or in the case of average-case complexity, with good probability) succeeds in mapping an input to the correct output. But even for intractable problems, you may get lucky and manage to find the right output for some input.
You can say that maybe each input defines its own particular problem, and some inputs are intractable and others are easy, but this is a bit problematic, partly because for every particular input there always exists a small circuit that finds the right output (i.e., a circuit with this output hardwired into it), and, as you argue above, it’s not clear if we shouldn’t allow such circuits when we model “efficient computation”.
So, while finding proofs for mathematical statements is hard in general, people still succeed in doing so for particular statements, and when they do so, we feel they are sometimes creative, perhaps exactly because we do not know of any systematic “cookbook” way to find such proofs.
Boaz, I think we are in agreement that the proof of Poincare conjecture required creativity. Connecting creativity to computational complexity intractability in this context is artificial. Why do you think that the third statement below makes more sense than the first two?
1) The general, problem of finding a proof to a mathematical statement can be undecidable, and therefore the proof of Poncare conjecture reflects creativity
2) The size of a proof of a general mathematical statement that has a proof can be huge in terms of the size of the statement. Therefore the proof of Poincare conjecture reflects creativity.
3) Finding a proof of a mathematical statement can be computationally hard even if there is a small length proof. Therefore the proof of Poincare conjecture reflects creativity.
Hi Boaz, actually I think that the point that in certain cases of natural algorithms P/poly is better model than P is quite interesting.
I have a related question that might be quite silly but let me ask anyway. Suppose that you have a decision problem in NP and you are guaranteed that the problem is in P/poly or specifically that it can be solved by a circuit of size when the input is of size n. The question is how hard it is to find a polynomial size circuit that solves the problem. (In its general case.) Is it, or can it be computationally intractable? Can it be NP-hard or something like that?
when the input is of size n. The question is how hard it is to find a polynomial size circuit that solves the problem. (In its general case.) Is it, or can it be computationally intractable? Can it be NP-hard or something like that?
Hi Gil,
If you simply know that the circuit exists it doesn’t help you much, since you can always assume it exists and see what happens.
If you are given black-box access to the circuit, then it’s a well known problem of learning a circuit with oracle queries. This is widely believed to be computationally intractable, even if you make the necessary relaxation that you only need to find a circuit that approximates your black-box. If cryptographic pseudorandom functions exist, they are a great example of circuits that you cannot learn even very weakly from oracle queries.
There is a paper by Bshouty Cleve Gavalda Kannan and Tamon showing you can learn such circuits with access to NP oracle or oracles higher in the polynomial hierarchy (depending on the exact form of queries allowed), see http://www.cs.technion.ac.il/~bshouty/MyPapers/Oracles%20and%20Queries%20that%20are%20Sufficient%20for%20Exact%20Learning/bshouty96oracles.pdf
Hi Mr. Barak,
I looked at the slides you sent me but I did not see any information linking psuedorandom generators to NP complete problems. Is there a psuedorandom generator that is conjectured to be NP complete?
Sorry for the delayed response. If there is an efficient algorithm for an NP complete problem then P=NP and then (as the slide there mentions) there is no secure pseudorandom generator, since for every efficient deterministic algorithm G mapping a small seed into a larger string, it is possibly to efficiently distinguish the output of G from random.
However, there is no known connection in the other direction – it could be that pseudorandom generators do not exist, but it still holds that P is different from NP (and hence NP complete problems do not have efficient algorithms). Thus there is no pseudorandom generator that is proven (and in fact none that is conjectured) to be NP complete. A nice exposition of these and other possibilities is given in Russell Impagliazzo’s survey “A personal view of average-case complexity”, cseweb.ucsd.edu/~russell/average.ps
Thank you for replying Mr. Barak. I understand the concepts now.
Boy, I guess I came to the wrong blog: I’ve had two of my questions ignored by two different bloggers and have not had a response from the host in more than a week. Why am I here?