In my last post, we saw that the problem of learning juntas, hard as it is over Boolean inputs, seems even worse over other alphabets. Coding theory happens to have a inexhaustible supply of such problems. Some of these are long-standing open problems, others are of a more recent vintage. More of these problems seem to crop up all the time. And as will be clear from the list below, this issue does seem to follow me around.
Here are four of my favorite problems, completely solved for  but wide open for any other alphabet (which we take to be some finite field).
but wide open for any other alphabet (which we take to be some finite field).
Optimal codes of distance d: Arguably the mother of all such problems. How many parity checks must a 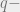 ary length
ary length  code of distance
code of distance 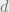 have? Here we think of
have? Here we think of  as a constant and going to infinity. For the Hamming bound tells us that
as a constant and going to infinity. For the Hamming bound tells us that 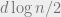 parity checks are necessary. The BCH construction tells us that this is also sufficient. For larger alphabets, the best lower bound is still the Hamming bound, and the Hamming bound is still
parity checks are necessary. The BCH construction tells us that this is also sufficient. For larger alphabets, the best lower bound is still the Hamming bound, and the Hamming bound is still  . Alas the BCH upper bound is now
. Alas the BCH upper bound is now  . For more on this problem and its connections to additive combinatorics, see here.
. For more on this problem and its connections to additive combinatorics, see here.
List-decoding Reed-Muller codes: Given a function  , our goal is to recover all degree-d polynomials that are close to
, our goal is to recover all degree-d polynomials that are close to  . Of course, we can hope to solve this in reasonable time only if this list is not too large (say a constant independent of the dimension ). The question is what bound on the distance from (equivalently the error-rate) is enough to ensure that the list is small, the conjecture is that it is the minimum distance of the degree d Reed-Muller code. The degree 1 case is the problem of Hadamard decoding, solved by Goldreich and Levin. In joint work with Klivans and Zuckerman, we solved the case for all , and in a subsequent paper, the
. Of course, we can hope to solve this in reasonable time only if this list is not too large (say a constant independent of the dimension ). The question is what bound on the distance from (equivalently the error-rate) is enough to ensure that the list is small, the conjecture is that it is the minimum distance of the degree d Reed-Muller code. The degree 1 case is the problem of Hadamard decoding, solved by Goldreich and Levin. In joint work with Klivans and Zuckerman, we solved the case for all , and in a subsequent paper, the  case for all
case for all 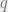 . The case of larger
. The case of larger  is open.
is open.
The bottleneck in working with higher alphabets is the following. Fix a polynomial P which has good agreement. The Goldreich-Levin and GKZ algorithms “guess” the P on a c-dimensional subspace S, where  is a constant. They then use this to recover P on all
is a constant. They then use this to recover P on all 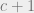 dimensional subspaces containing S. Why is this easier? Knowing the right values on a subspace of co-dimension 1 effectively reduces the error-rate by a factor of
dimensional subspaces containing S. Why is this easier? Knowing the right values on a subspace of co-dimension 1 effectively reduces the error-rate by a factor of 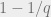 . For , this reduces the error by
. For , this reduces the error by 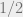 and puts us in the unique-decoding regime where things are easy. But for larger , this error-reduction does not always suffice to specify P unambiguously.
and puts us in the unique-decoding regime where things are easy. But for larger , this error-reduction does not always suffice to specify P unambiguously.
Decoding from errors and erasures: Assume that we have an ![[n,k,d]_q](https://s0.wp.com/latex.php?latex=%5Bn%2Ck%2Cd%5D_q&bg=eeeeee&fg=666666&s=0&c=20201002) linear code. Such a code can correct
linear code. Such a code can correct 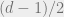 errors and
errors and  erasures. Assume that we have efficient algorithms for both these (the latter is always the case for a linear code). Can we combine these in a black-box fashion to get an efficient algorithm that corrects
erasures. Assume that we have efficient algorithms for both these (the latter is always the case for a linear code). Can we combine these in a black-box fashion to get an efficient algorithm that corrects  errors and erasures as long as
errors and erasures as long as 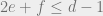 ? When , the answer is Yes (take a guess!). I don’t know the answer for larger . I came upon this problem in conversations with Atri Rudra, perhaps there is a reference for it? Or better still, a solution?
? When , the answer is Yes (take a guess!). I don’t know the answer for larger . I came upon this problem in conversations with Atri Rudra, perhaps there is a reference for it? Or better still, a solution?
Learning Linear Functions with noise: Learning parity with noise is a central problem in learning, that is widely believed to be hard. We are given random examples of points in  labeled with some unknown parity function L, the catch is that each label is flipped independently with probability
labeled with some unknown parity function L, the catch is that each label is flipped independently with probability 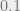 . A seemingly even harder problem is when the noise is adversarial, and the adversary is allowed to flip an arbitrary fraction of labels over all points in
. A seemingly even harder problem is when the noise is adversarial, and the adversary is allowed to flip an arbitrary fraction of labels over all points in 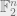 . In joint work with Feldman, Khot and Ponnuswami, we show that the problems are in fact equivalent, there is a reduction from adversarial noise to random noise.
. In joint work with Feldman, Khot and Ponnuswami, we show that the problems are in fact equivalent, there is a reduction from adversarial noise to random noise.
In retrospect, perhaps this is not too surprising: learning parity with noise is already so very hard that making the noise adversarial does not make it worse. Well, the same philosophy ought to apply to other alphabets. But I don’t know of a similar reduction for any other alphabet. This paper makes some progress on this problem, reducing adversarial noise to a more benign noise model, but does not solve the problem fully.
If you have a problem of this flavor, I’d love to hear about it. I am unlikely have anything insightful to say, but I’d be happy to commiserate with you about how annoying  can be.
can be.

One thought on “On the importance of the alphabet”