Computational learning is full of problems that are deceptively simple to state but fiendishly hard to solve. Perhaps none more so than the problem of learning Juntas, posed by Avrim Blum and Pat Langley. Its the kind of problem which seems well suited for a polymath endeavor, Dick Lipton likes to say that you could think about it while running for the bus. Alas, I haven’t ridden many buses here in the Bay Area (and coincidentally haven’t had any good ideas about this problem).
But what I’d like to talk about in this post is a variant of the problem which I think is kind of cute. The question is from a paper by Mossel, O’Donnell and Servedio, this particular formulation came up in discussions with Ryan O’Donnell, Amir Shpilka and Yi Wu (sorry guys, I know you’d rather not be associated with this one).
Let us begin with the problem of learning Juntas. The setup is that of learning an unknown Boolean function under the uniform distribution: we are given random examples from 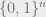
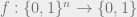

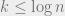
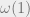
It is trivial to solve the problem in time 

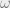
multiplication exponent. So it will never do better than 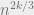
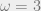
Here is a bare-bones sketch of the MOS algorithm. A natural approach to finding a relevant variable is to compute correlations between the n input variables and 
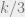
The MOS algorithm relies on the insight that these are (essentially) the only functions that evade the low-degree algorithm: any such function must have low degree as a polynomial over GF[2], and is easy to learn using polynomial interpolation over GF[2]. The precise result they use is due to Seigenthaler from 1984.
Much as I love polynomials over GF[2], one can’t help wondering how robust this approach is. Suppose we were trying to learn a Boolean function but over an ternary alphabet. Would the right analogue be polynomials over GF[3]? Over an alphabet of size 4 (A,T,G,C), should the polynomials be over GF[4] or 
The larger alphabet is mentioned as an open problem in MOS, and as far as I know, no one has managed to do anything with it (it is quite likely that no one has tried too hard). But I think this might turn out to be a worthwhile digression that could shed some light on the original problem. Here is a particular formulation of the alphabet 4 question that I like:
Learning 
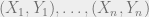
are given uniform examples of an unknown function
It is trivial to do it in time 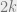


Finally, I am told there is money on offer (not from me) for solving the following seemingly innocuous problem: suppose you know that the function is Majority on 

We give an algorithm for learning such functions given only a source of uniformly distributed random labeled examples. Our algorithm achieves the first polynomial factor improvement on a naive n^k time bound (which can be achieved via exhaustive search). The algorithm and its analysis are based on new structural properties which hold for all Boolean functions and may be of independent interest.