Personally, I was so very pleased to hear that Endre Szemerédi won the 2012 Abel Prize. In my eyes, this sentiment should be shared by all mathematicians and certainly by all who study the theory of computations. Szemerédi’s contributions to computer science are immense. The first examples that come to mind are most probably Szemerédi’s regularity lemma and the AKS sorting networks due to Miklós Ajtai, János Komlós, and Endre Szemerédi. On this occasion, we (Boaz, Parikshit and I) thought we would point out some of the other reasons computer science should be thankful for the research of Endre Szemerédi. Our examples should by no means taken as an exhaustive list.
Space-bounded derandomization
Omer Reingold
A question close to my heart is whether randomness can save memory, or perhaps for every randomized algorithm there exists a deterministic algorithm that solves the same computational problem and does not use much more memory. A prime example of a computational problem that has a very memory-efficient algorithm is connectivity of undirected graphs (graphs where edges can be traversed in both directions). The randomized algorithm is simply a random walk: start at any node of the graph and at each time step move to a random neighbor of the current node. Aleliunas, Karp, Lipton, Lovász and Rackoff showed in 1979 that on an  -node connected, undirected graph the random walk (with an arbitrary start node) will visit every node of the graph with very high probability after polynomial (in ) number of steps. The memory needed to carry out this algorithm is logarithmic (that is, proportional to the memory needed to memorize the name of a single node). At the time, the best deterministic algorithm was Savitch’s algorithm which requires
-node connected, undirected graph the random walk (with an arbitrary start node) will visit every node of the graph with very high probability after polynomial (in ) number of steps. The memory needed to carry out this algorithm is logarithmic (that is, proportional to the memory needed to memorize the name of a single node). At the time, the best deterministic algorithm was Savitch’s algorithm which requires  memory (this is still the best algorithm for connectivity in directed graphs). The first improvement of Savitch’s algorithm (for undirected graphs) was given in an algorithm due to Noam Nisan, Endre Szemerédi and Avi Wigderson, requiring only
memory (this is still the best algorithm for connectivity in directed graphs). The first improvement of Savitch’s algorithm (for undirected graphs) was given in an algorithm due to Noam Nisan, Endre Szemerédi and Avi Wigderson, requiring only 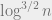 memory.
memory.
I read and enjoyed the NSW paper as a grad student and it is certainly one of Szemerédi’s contributions that directly influenced my research. But a different contribution that was potentially more important for my own research (as well as Complexity Theory as a whole) is “the other” (less known) AKS paper (Ajtai, Komlós, and Szemerédi) – Deterministic simulation in LOGSPACE. This paper initiated the study of pseudorandom generators that fool memory-bounded computations, a concept that turned out to be immensely useful. The model of memory-bounded computations used by AKS (layered read-once branching programs), is the model we still use today. The AKS generator takes  uniformly distributed bits and expands them to
uniformly distributed bits and expands them to  bits which fool algorithms with bits of memory (polynomial width branching programs), up to polynomially small error. Interestingly, these modest parameters are (to the best of my knowledge) not subsumed by more recent work.
bits which fool algorithms with bits of memory (polynomial width branching programs), up to polynomially small error. Interestingly, these modest parameters are (to the best of my knowledge) not subsumed by more recent work.
More on these two papers coauthored by Szemerédi can be found in this (excellent though outdated) survey paper and potentially also in future posts.
Coding theory
Parikshit Gopalan
Endre Szemerédi is famous for his work on the size of subsets that do not contain arithmetic progressions, building on earlier work of Roth. Questions about the asymptotic size of these subsets are of interest even over finite fields, and are in fact related to a fundamental question in coding theory (so somewhat surprisingly, there are practical applications).
The question in coding theory is the following: How much information can be encoded in an error-correcting code of length and distance 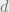 ?
?
For simplicity, let us focus on linear codes. We are asking how many of the symbols need to be parity check symbols (that is, added for redundancy). Let us call this number 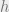 . The Hamming bound uses a sphere packing argument to show that (ignoring floors and ceilings and
. The Hamming bound uses a sphere packing argument to show that (ignoring floors and ceilings and 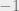 s)
s) 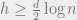 . Over the binary alphabet, the famous (and ubiquitous) BCH codes give a matching upper bound. Over a
. Over the binary alphabet, the famous (and ubiquitous) BCH codes give a matching upper bound. Over a 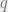 -ary alphabet though, the BCH bound is
-ary alphabet though, the BCH bound is  This only matches the Hamming bound when
This only matches the Hamming bound when 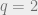 . (This is a recurring theme in coding theory,
. (This is a recurring theme in coding theory,  really is a very special number). Even when
really is a very special number). Even when 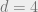 and
and  , we don’t know the right answer. Surely this has to be easy? And what does it have to do with arithmetic progressions?
, we don’t know the right answer. Surely this has to be easy? And what does it have to do with arithmetic progressions?
Suppose we want to construct a subset of 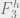 with no
with no 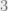 term arithmetic progressions. Assume we have a length n linear code
term arithmetic progressions. Assume we have a length n linear code 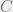 of distance
of distance  and parity checks. Write down its parity check matrix
and parity checks. Write down its parity check matrix 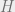 , and think of its columns as points in . Since there are no codewords of weight , there are no three columns
, and think of its columns as points in . Since there are no codewords of weight , there are no three columns  which satisfy the equation
which satisfy the equation 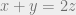 , which is the same as
, which is the same as  over
over 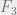 . So we get points with no -term AP in .
. So we get points with no -term AP in .
Moreover there is a converse. Assume that someone gave us a large set  containing elements with no term AP. We could use this as the columns of a parity check matrix . This guarantees that no columns sum to
containing elements with no term AP. We could use this as the columns of a parity check matrix . This guarantees that no columns sum to 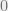 . Of course, it could be that
. Of course, it could be that  for some . To eliminate such possibilities, we simply add the all 1s vector as a row of . We now get a code of length and distance with
for some . To eliminate such possibilities, we simply add the all 1s vector as a row of . We now get a code of length and distance with  parity checks.
parity checks.
Bibliographic notes: The first upper bound for the size of AP-free sets is due to Klaus Roth from the 50s. It holds both for integers and for  . Szemerédi strengthened Roth’s theorem for integers. The first improvement upon Roth in happened just last year due to Michael Bateman and Nets Katz.
. Szemerédi strengthened Roth’s theorem for integers. The first improvement upon Roth in happened just last year due to Michael Bateman and Nets Katz.
Additive combinatorics and randomness extraction
Boaz Barak
Many of my papers used or drew on Szemerédi’s research, probably in more ways than I’m aware of. One example comes from works I had with Russell Impagliazzo, Avi Wigderson, and others on the randomness extraction problem. This is the problem where we wish to produce output that behaves like sequence of independent coin tosses (perhaps for using in a randomized algorithm, or to generate cryptographic keys), but we have access only to a weak source  of randomness that has some entropy in it, but is not distributed like the uniform distribution (e.g., measurements of user typing pattern, or network latencies). Unfortunately, this is generally impossible, but luckily this impossibility result goes away if we assume that we can get several independent samples from the source (or even samples from several independent sources of different high entropy distributions). In fact, one can show that a random function can extract essentially all the entropy from only two independent samples from , and hence such a function yields what we call a two source extractor. However, one cannot efficiently compute a random function, and hence the problem was raised of finding an explicit such extractor. (I should note that although this problem sounds very practical, its main appeal and applications are in theoretical computer science and combinatorics, since in practice people are happy to apply some cryptographic hash function to a single sample from the source and this seems to work well, unless there is not much entropy in the source in the first place.)
of randomness that has some entropy in it, but is not distributed like the uniform distribution (e.g., measurements of user typing pattern, or network latencies). Unfortunately, this is generally impossible, but luckily this impossibility result goes away if we assume that we can get several independent samples from the source (or even samples from several independent sources of different high entropy distributions). In fact, one can show that a random function can extract essentially all the entropy from only two independent samples from , and hence such a function yields what we call a two source extractor. However, one cannot efficiently compute a random function, and hence the problem was raised of finding an explicit such extractor. (I should note that although this problem sounds very practical, its main appeal and applications are in theoretical computer science and combinatorics, since in practice people are happy to apply some cryptographic hash function to a single sample from the source and this seems to work well, unless there is not much entropy in the source in the first place.)
Works of Chor-Goldreich and Vazirani in the 1980’s gave an explicit two-source extractor for an  -bit source contains more than
-bit source contains more than  bits of entropy, but there was no such extractors for sources of
bits of entropy, but there was no such extractors for sources of 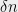 entropy with
entropy with 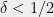 , even if we allow a larger constant number of samples than two. In our paper, we gave such an extractor, and the tool we used was Bourgain-Katz-Tao’s finite field analog of the Erdös-Szemerédi Sum-Product Theorem that (slightly rephrased) says that for an
, even if we allow a larger constant number of samples than two. In our paper, we gave such an extractor, and the tool we used was Bourgain-Katz-Tao’s finite field analog of the Erdös-Szemerédi Sum-Product Theorem that (slightly rephrased) says that for an  -sized set over the reals,
-sized set over the reals,  for some absolute constant
for some absolute constant 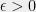 , where for sets
, where for sets  we define
we define  and
and  . This is a beautiful result, for there is in fact a simple “book proof” (that indeed can be found in page 285 of the book, see also here). The proof outline is that, assuming otherwise, one considers the
. This is a beautiful result, for there is in fact a simple “book proof” (that indeed can be found in page 285 of the book, see also here). The proof outline is that, assuming otherwise, one considers the  points in
points in  of the form
of the form  , with
, with  and
and  , and the
, and the  lines of the form
lines of the form  with
with  . One can show that if we draw these points in the plane as vertices and draw these lines between them, we get a graph of
. One can show that if we draw these points in the plane as vertices and draw these lines between them, we get a graph of  vertices and roughly
vertices and roughly 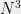 edges that is “somewhat planar”, in the sense that there are only
edges that is “somewhat planar”, in the sense that there are only 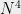 points where two edges cross one another. If we now subsample and keep each vertex in the graph with probability
points where two edges cross one another. If we now subsample and keep each vertex in the graph with probability 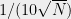 , then its likely that all these crossings will disappear, and we’ll get a planar graph with
, then its likely that all these crossings will disappear, and we’ll get a planar graph with  vertices but
vertices but  edges— a contradiction to Euler’s formula.
edges— a contradiction to Euler’s formula.
What does the Sum-Product Theorem has to do with extracting randomness?
The construction of an extractor based on the finite field sum product theorem is actually quite simple to describe. It’s also simple to analyze, at least if we take the (overly simplistic) view that all random variables we deal with are distributions over sets, and hence their entropy is the logarithm of the size of these sets. Now, we can interpret -bit strings as elements of the finite field of size 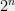 , and so if we have some source over bits of entropy , in our view it corresponds to a
, and so if we have some source over bits of entropy , in our view it corresponds to a 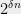 -sized set of field elements. Now the Sum Product theorem says that the source
-sized set of field elements. Now the Sum Product theorem says that the source  , which we can simulate using three independent samples of , will correspond to a set of size at least
, which we can simulate using three independent samples of , will correspond to a set of size at least 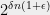 . In other words, by spending three samples we increased the entropy from to
. In other words, by spending three samples we increased the entropy from to 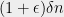 , and if we repeat this enough times we’ll get to entropy at which point we get the uniform distribution (or we can stop at using the prior works mentioned before).
, and if we repeat this enough times we’ll get to entropy at which point we get the uniform distribution (or we can stop at using the prior works mentioned before).
However, to translate the set size argument into entropy, we needed to use Gowers’s quantitative version of what I call a “Magic Lemma” by Balog and (yes, again) Szemerédi . This lemma says that if, for -sized sets  , the distribution
, the distribution  has entropy less than
has entropy less than  , then there are subsets
, then there are subsets  of size roughly , such that
of size roughly , such that  . (The same statement holds for the operation
. (The same statement holds for the operation  instead of
instead of 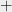 ). This turns out to be exactly what we need, since, roughly speaking it says that if we have the guarantee that either or increases significantly the size of the sets we’re dealing with, then we know that it also would increase the entropy, thus allowing us to argue that
). This turns out to be exactly what we need, since, roughly speaking it says that if we have the guarantee that either or increases significantly the size of the sets we’re dealing with, then we know that it also would increase the entropy, thus allowing us to argue that  has larger entropy than .
has larger entropy than .
Why do I call it a “Magic Lemma”? Let’s think about the Lemma’s statement. If has lowish entropy, this roughly means that there is a not too big set 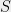 (say of size less than
(say of size less than 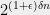 ) such that with some noticeable probability
) such that with some noticeable probability 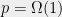 , if pick
, if pick  from and
from and 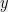 from
from  , we’ll get that
, we’ll get that  is in . We can picture this by drawing a bipartite graph, with left vertices corresponding to members of , and right members corresponding to members of , and adding the edge
is in . We can picture this by drawing a bipartite graph, with left vertices corresponding to members of , and right members corresponding to members of , and adding the edge  for every pair where
for every pair where  . The problem is that the support of can be huge, since we have no control over what happens to the majority of the pairs where is not in . Intuitively, what the Lemma seems to say is that we could find subsets
. The problem is that the support of can be huge, since we have no control over what happens to the majority of the pairs where is not in . Intuitively, what the Lemma seems to say is that we could find subsets  and
and  of size
of size  such that the induced graph would be complete. This is generally impossible, since a
such that the induced graph would be complete. This is generally impossible, since a  -vertex bipartite graph could have average degree
-vertex bipartite graph could have average degree  , but no induced bipartite clique of superlogarithmic size. So, we seem stuck but the magic is that it turns out that something slightly weaker is true: we can find subsets of size where every
, but no induced bipartite clique of superlogarithmic size. So, we seem stuck but the magic is that it turns out that something slightly weaker is true: we can find subsets of size where every  , even if not directly connected, still have roughly the “right” number (i.e.,
, even if not directly connected, still have roughly the “right” number (i.e., 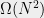 ) of length-
) of length-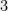 paths between them. This means that we can express as a sum
paths between them. This means that we can express as a sum 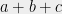 with
with  in different ways, which will upper bound
in different ways, which will upper bound  by
by  . The proof of this magic lemma is also quite simple (e.g., see Lemma 4 in this blog post). Roughly speaking, if you choose
. The proof of this magic lemma is also quite simple (e.g., see Lemma 4 in this blog post). Roughly speaking, if you choose  to be a neighborhood of a random point
to be a neighborhood of a random point 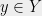 , then we almost get what we want, in the sense that, after some pruning, every vertex
, then we almost get what we want, in the sense that, after some pruning, every vertex  has,say, at least
has,say, at least  paths of length
paths of length 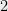 to all but, say, a
to all but, say, a  fraction of the other vertices in . Now, if we let
fraction of the other vertices in . Now, if we let  be the set of vertices that have at least
be the set of vertices that have at least 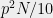 neighbors in , we’re done.
neighbors in , we’re done.

Great post everyone! Very helpful.
P.S. Boaz, I think you mean Gyorgy Elekes, not Noam Elkies?
Thank you Andy! You are so right, I was confused and this proof is not due to Noam Elkies. Actually, looking deeper into Terry Tao’s post I linked above, I see that the credit is a bit more complicated. The proof I outlined combines:
1) Elekes’s argument deriving the sum-product theorem from the Szemeredi-Trotter line/point incidences,
2) Szekeli’s proof of the Szemeredi-Trotter theorem from the bound on the crossing numbers of Ajtai-Chvátal-Newborn-Szemerédi / Leighton.
3) The simple proof of the crossing number bound, which according to Proofs from the Book arose in email conversations between Bernard Chazelle, Micha Sharir and Emo Welzl.