Last week Ryan O’Donnell mentioned, as part of his Simons Symposium report, that Per Austrin (with Kai-Min Chung, Mohammad Mahmoody, Rafael Pass, and Karn Seth) have a new, Fourier-based, proof of an “old” result due to Miklos Santha and Umesh Vazirani. This is a great opportunity to tell you a bit about deterministic extraction. I will also discuss (in my next post) a very simple but very different proof Salil Vadhan, Avi Wigderson and I had for this theorem. We will also have a guest post by Per on the Fourier based proof. I think that having several proofs for basic theorems could be illuminating. In particular, new proofs can lead to new extensions and generalizations, and this is the case both for Per’s proof as well as for ours.
The rationale behind the area of randomness extraction is in the following observation: randomized computations assume access to a sequence of independent and unbiased coin flips (namely, a uniformly distributed bit string). On the other hand, available sources of randomness are weak and consist of biased and correlated bits. Randomness extractors give a way to transform weak sources of randomness to be almost uniform, which in turn could be used to run our randomized computations.
A beautiful example from the early fifties, is due to John von Neumann: Assume you have access to a sequence of bits that are independently and identically distributed but have some (unknown) bias. Namely, for some value 






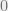

In today’s language we refer to a procedure such as that proposed by von Neumann as a deterministic extractor – a deterministic procedure that “extracts” the randomness from a source that is not uniformly distributed but still has some randomness hidden inside it. As you probably guessed, if there are deterministic extractors, there is also another kind of extractors that are not deterministic. Such extractors (proposed by Noam Nisan and David Zuckerman) are known as seeded extractors and they take two inputs – the weak source we want to extract randomness from and in addition a short random string known as a seed.
How could seeded extractors make any sense? After all, we need extractors because our sources of randomness are not uniform. Surprisingly, seeded extractors are extremely useful, but this is a long story worthy of a separate post. Very loosely, their usefulness stems from the seed being very short (so short that it is feasible to enumerate over all possible values for the seed). But why not use deterministic extractors instead? The reason is that deterministic extraction is impossible for very natural classes of weak random sources. And this is where the Santha-Vazirani result comes into the picture: Santha and Vazirani proposed the notion of semi-random sources (aka Santha-Vazirani or SV sources) and showed that it is impossible to extract even a single uniform bit from such sources.
The bits in an SV-source are not only biased but also correlated. The guarantee of an SV-source with bias 


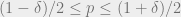



![\Pr[f(X)=1]\leq (1-\delta)/2](https://s0.wp.com/latex.php?latex=%5CPr%5Bf%28X%29%3D1%5D%5Cleq+%281-%5Cdelta%29%2F2&bg=eeeeee&fg=666666&s=0&c=20201002)
![\Pr[f(X)=1]\geq (1+\delta)/2](https://s0.wp.com/latex.php?latex=%5CPr%5Bf%28X%29%3D1%5D%5Cgeq+%281%2B%5Cdelta%29%2F2&bg=eeeeee&fg=666666&s=0&c=20201002)
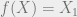
In my next post I will show a simple proof of this (and an even stronger) theorem. For now, I should mention that our story has a (relatively) good ending. While it is impossible to deterministically extract even a single bit from SV sources, we can still run our randomized algorithms using SV sources. Using the notion of seeded extractors, this positive result also holds for much less structured sources: Our randomized algorithms can be run using the weakest possible random sources we can hope to use. I may expand, in future posts, on this statement as well as on the many other applications of seeded extractors. In the meanwhile, here are some relevant references: an old presentation of mine, an introduction to extractors and a somewhat outdated survey and presentation on their construction. You may also look at Salil’s monograph draft (Chapter 6), which in particular contains the proof I promised for the next post (Problem 6.6).
