Continuing on my last post, today I will talk about recent work by Niv Buchbinder, Moran Feldman, Seffi Naor, and Roy Schwartz that gives a simple 1/2 approximation to the (unconstrained) submodular maximization problem, matching the hardness. Do see the paper (which should be available in a couple of weeks) for full details. Apologies in advance for any errors.
First consider the greedy algorithm that starts with the empty set, and keeps adding the most profitable item, as long as there is an improvement in the objective. For most variants of set cover type problems, such algorithms give the best possible approximation guarantees.
Unfortunately, it is not hard to construct set functions where the approximation ratio of greedy is unbounded. How about reverse greedy: starting with everything and throwing out elements while we improve? The function  defined as
defined as 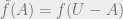 is also submodular when
is also submodular when  is, and running the “reverse greedy” on is same as running greedy on . Thus a bad example for greedy can be transformed into one for reverse greedy.
is, and running the “reverse greedy” on is same as running greedy on . Thus a bad example for greedy can be transformed into one for reverse greedy.
The first idea that BFNS try is to do both greedy and reverse greedy, in a correlated way. Let’s start with  and
and  . In the ith step, we will make
. In the ith step, we will make  and
and  agree in the ith coordinate, by either adding
agree in the ith coordinate, by either adding  to or deleting from . A greedy approach to doing this is to add to if the marginal benefit
to or deleting from . A greedy approach to doing this is to add to if the marginal benefit  exceeds
exceeds  . It can also by shown using the definition of submodularity that the sum
. It can also by shown using the definition of submodularity that the sum  is non-negative, so at least one of the sets improves in value. In
is non-negative, so at least one of the sets improves in value. In  steps, we have
steps, we have  and that is the output of the algorithm.
and that is the output of the algorithm.
Is this “coupled greedy algorithm” any good? BFNS first show that this gives a 1/3 approximation. Towards a short proof, here is a little more notation. Let 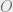 be the optimal set. Let
be the optimal set. Let ![U_{-[i]}](https://s0.wp.com/latex.php?latex=U_%7B-%5Bi%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002) denote the tail set
denote the tail set  and let
and let ![O_{-[i]} = O \cap U_{-[i]}](https://s0.wp.com/latex.php?latex=O_%7B-%5Bi%5D%7D+%3D+O+%5Ccap+U_%7B-%5Bi%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002) denote the part of in the tail. Let
denote the part of in the tail. Let  and
and  denote the sets
denote the sets  and at the end of iteration . Thus
and at the end of iteration . Thus 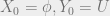 and
and ![Y_i = X_i \cup U_{-[i]}](https://s0.wp.com/latex.php?latex=Y_i+%3D+X_i+%5Ccup+U_%7B-%5Bi%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002) . For simplicity of presentation, we will assume that
. For simplicity of presentation, we will assume that  .
.
Now here is the crucial definition. Consider the hybrid set ![Z_i = X_i \cup O_{-[i]}](https://s0.wp.com/latex.php?latex=Z_i+%3D+X_i+%5Ccup+O_%7B-%5Bi%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002) . Thus we have
. Thus we have  and
and  is the output of the algorithm. We don’t know
is the output of the algorithm. We don’t know  but we know
but we know  . In the ith step, we learn a little more about our set
. In the ith step, we learn a little more about our set  , and let
, and let  denote the quantity
denote the quantity  . The total loss
. The total loss 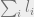 is
is  . We will show that the total loss is at most
. We will show that the total loss is at most  . This would imply that claimed approximation ratio.
. This would imply that claimed approximation ratio.
Suppose that  in step , so that we add . We claim that in this case,
in step , so that we add . We claim that in this case, 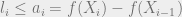 . Two cases: if is in , then is zero since
. Two cases: if is in , then is zero since  . On the other hand
. On the other hand  . If is not in , then
. If is not in , then  . Thus
. Thus  is the marginal value of with respect to
is the marginal value of with respect to  . Since
. Since  , this marginal value is at least
, this marginal value is at least  , which in turn means that
, which in turn means that  . Summed over all iterations where , the total loss is then at most the sum of
. Summed over all iterations where , the total loss is then at most the sum of  ‘s over these iterations. This is exactly
‘s over these iterations. This is exactly 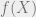 .
.
An essentially identical argument shows that the sum over iterations when 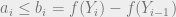 is also at most . This finishes the proof.
is also at most . This finishes the proof.
But 1/3 is not what I promised above. How do we improve on this? The answer to this question was in the last post: we will use the multilinear relaxation, which extends the defintion of a submodular function to the whole of ![[0,1]^n](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5En&bg=eeeeee&fg=666666&s=0&c=20201002) . BFNS modify the above algorithm to do the coupled walks in instead of on
. BFNS modify the above algorithm to do the coupled walks in instead of on 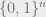 . Start with
. Start with  and
and  . In the ith step, we will make
. In the ith step, we will make 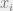 and
and 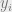 equal, so that
equal, so that  and
and 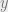 agree in n steps. Defining as
agree in n steps. Defining as  and as
and as  , we make an agree as follows. If only one of and is positive, the choice is obvious: we set
, we make an agree as follows. If only one of and is positive, the choice is obvious: we set 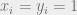 in the first case, and make them both zero in the second case. In case they are both positive, it is natural to interpolate linearly: we set
in the first case, and make them both zero in the second case. In case they are both positive, it is natural to interpolate linearly: we set  . Instead of the sets
. Instead of the sets 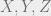 , above, we will have their fractional counterparts: vectors
, above, we will have their fractional counterparts: vectors  . Here
. Here  is defined as being equal to the optimum
is defined as being equal to the optimum  on the tail, and equal to on the first $i$ coordinates.
on the tail, and equal to on the first $i$ coordinates.
The proof is now very similar to the previous case, except that we save a factor of two. The following inequality implies that the total loss is only 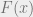 , which will lead to a factor
, which will lead to a factor  :
:
![l_i \leq \frac{1}{2}[F(x_{i}) - F(x_{i-1})] + \frac{1}{2}[F(y_i) - F(y_{i-1})].](https://s0.wp.com/latex.php?latex=l_i+%5Cleq+%5Cfrac%7B1%7D%7B2%7D%5BF%28x_%7Bi%7D%29+-+F%28x_%7Bi-1%7D%29%5D+%2B+%5Cfrac%7B1%7D%7B2%7D%5BF%28y_i%29+-+F%28y_%7Bi-1%7D%29%5D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Proving this is not that hard once we know that this is what is to be proved. In the case that one of or is negative, this is fairly straightforward given the analysis in the  approximation above. In the case that they are both non-negative, we need to compute the various terms. It is easy to check that in this case
approximation above. In the case that they are both non-negative, we need to compute the various terms. It is easy to check that in this case ![[F(x_{i}) - F(x_{i-1})]](https://s0.wp.com/latex.php?latex=%5BF%28x_%7Bi%7D%29+-+F%28x_%7Bi-1%7D%29%5D&bg=eeeeee&fg=666666&s=0&c=20201002) is equal to
is equal to  , and that
, and that ![[F(y_{i}) - F(y_{i-1})]](https://s0.wp.com/latex.php?latex=%5BF%28y_%7Bi%7D%29+-+F%28y_%7Bi-1%7D%29%5D&bg=eeeeee&fg=666666&s=0&c=20201002) is equal to
is equal to  . The quantity can be upper bounded, again using arguments similar to those above, by
. The quantity can be upper bounded, again using arguments similar to those above, by  . Since
. Since  , we are done.
, we are done.

Thanks for the post. For the 1/2 approximation, when calculating $a_i, b_i$, we need to calculate $F(x)$ for some fractional $x$. But when $x$ is fractional, do we need exponential number of calls to the oracle?
Good catch. I tried to gloss over this, but this is indeed an issue that has to be handled. Exactly computing F would indeed require an exponential number of calls. So one uses an estimate of F based on a small number of samples and argues that this suffices. This can be done and all works that use the multilinear relaxation have to deal with this. Here is one approach: using Chernoff bounds, you can show that if you take polynomially many random samples and average to estimate F, the additive error is at most M/poly(n) except with negilgible probability, where M is an upper bound on f. Intuitively, if an a_i or a b_i above is large, our estimates will be fairly accurate; if they are really small, we make a mistake, but then making a mistake shouldn’t effect us so much. One should be able to modify the analysis slightly to make this formal and argue that if we run the algorithm with these estimates with small additive errors, the final result is still a (1/2 – 1/poly) approximation.
Thanks for your reply. Also, for the 1/3-approximation proof, when $a_i \ge b_i$ and $i \not \in O$, I feel $-l_i$ should be at least $-b_i$ instead of $b_i$ since $-b_i$ is the marginal value of $i$ respect to $Y_i – i$. Also in this case, we can still say $l_i \le b_i \le a_i$.