In this post and the next, I will talk about the problem of maximizing a submodular function. Submodularity is a natural property of set functions, that captures the diminishing returns property. Formally, let 
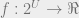
![U=[n]](https://s0.wp.com/latex.php?latex=U%3D%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
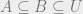
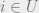
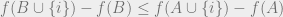
In other words, the marginal value of an element 

for any concave function
.
- Coverage function: we have a set
associated with each
corresponds to sets in a set cover instance).
is the number of elements covered by sets in
. More generally, if we have a non-negative weight
associated with each
, then we can set
- Cut function:
.
- Matroid rank function: we have a matroid on the set
Given a non-negative submodular function, it is natural to ask if we can find the set
Note that in this abstract form, we have really very little to work with. The algorithm can compute f on a polynomial number of sets, possibly chosen adaptively. The analysis can use non-negativity of f, and decreasing marginals inequality above. On the positive side, this means both the algorithms and the analyses are usually simple and short.
Uri Feige, Vahab Mirrokni and Jan Vondrák studied this general problem in 2007 and showed that one cannot hope to get better than a 1/2 approximation: a better-than-half approximation would require exponentially many queries to the oracle (in fact, Dobzinski and Vondrák recently showed that this is not just an informational bottelneck: even for succinctly represented functions, it is NP hard to get a better-than-half approximation). On the positive side, Feige, Mirrokni and Vondrák (FMV) showed that a random set gives a 1/4 approximation, and gave a beautiful 0.4 approximation algorithm based on smoothed local search. Subsequent works improved the approximation ratio to 0.41 and 0.42.
Today I will sketch the 
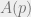

![E[f(A(p))] \geq (1-p)f(\phi) + pf(A)](https://s0.wp.com/latex.php?latex=E%5Bf%28A%28p%29%29%5D+%5Cgeq+%281-p%29f%28%5Cphi%29+%2B+pf%28A%29&bg=eeeeee&fg=666666&s=0&c=20201002)
Intuitively, this is a concavity type statement. The proof is in fact a very simple induction on 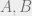

![E[f(A(p) \cup B(q))] \geq E[(1-q)f(A(p)) + q f(A(p) \cup B)]](https://s0.wp.com/latex.php?latex=E%5Bf%28A%28p%29+%5Ccup+B%28q%29%29%5D+%5Cgeq+E%5B%281-q%29f%28A%28p%29%29+%2B+q+f%28A%28p%29+%5Ccup+B%29%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Here we have used the fact that conditioned on any value of 




Armed with this inequality, the expected value of a random set can be easily lower bounded. Let 


![E[f(S(\frac{1}{2}) \cup \bar{S}(\frac{1}{2}))] \geq \frac{1}{4}\left(f(\phi) + f(S) + f(\bar{S}) + f(X)\right)](https://s0.wp.com/latex.php?latex=E%5Bf%28S%28%5Cfrac%7B1%7D%7B2%7D%29+%5Ccup+%5Cbar%7BS%7D%28%5Cfrac%7B1%7D%7B2%7D%29%29%5D+%5Cgeq+%5Cfrac%7B1%7D%7B4%7D%5Cleft%28f%28%5Cphi%29+%2B+f%28S%29+%2B+f%28%5Cbar%7BS%7D%29+%2B+f%28X%29%5Cright%29&bg=eeeeee&fg=666666&s=0&c=20201002)
Since 

With an eye towards the next post, let me define the multilinear relaxation of a submodular function. A subset 
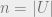
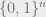
![[0,1]^{n}](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E%7Bn%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
![x \in [0,1]^n](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D%5En&bg=eeeeee&fg=666666&s=0&c=20201002)
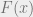
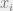
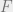

Thanks for the post, Kunal/Omer. One of the curious facts about submodularity to me is that while it naturally exhibits concavity, it also inherits a property from convexity: minimization is possible in polytime. Is there some basic or higher-level fact that leads to this nice confluence?
I think one explanation of that confluence is the Lovasz extension. This is a different and older extension which can be defined as the expected value of a different rounding scheme that picks a random lambda uniformly in [0,1], and rounds to one the coordinates with value at least lambda. This extension turns out to be convex, and can be optimized using Ellipsoid.
I like CCPV’s probabilistic view of the multilinear relaxation. I think it is also instructive to view set functions as real-valued multilinear polynomials using the Möbius transform. Here one uses the natural indicator string in {0,1}^n for a set S \subseteq [n], interpolates the 2^n values of the function, and expands. The resulting multilinear polynomial will agree with the function on inputs in {0,1}^n, but one can also evaluate the polynomial on any point in R^n. This is of course completely equivalent to CCPV’s definition, but the Möbius view avoids any talk of probability.
One can do the same thing using the (somewhat less natural) indicator string in {-1,+1}^n for a set S\subseteq [n], and this real-valued multilinear polynomial is of course the Fourier transform. We can also evaluate this polynomial on points outside of {-1,+1}^n, and in particular when we evaluate this polynomial on points in {-p,p}^n, this is the action of the noise operator on a set function. Viewed in this light, the FMV inequality becomes a statement about the noise stability of submodular functions. (Plug! http://eccc.hpi-web.de/report/2011/090/)
Instead of applying the same noise rate to every coordinate, one can apply different noise rates to different coordinates, and one recovers the 2-part inequality of FMV and both the 1/4 and the 1/3 approximation. In fact one can recover the 3-part inequality as well, and the proof of the 0.4-approximation becomes greatly simplified (at least notationally).
Thanks Homin for the comment. Your paper has been on my list, and I hope to read and understand it very soon.
Kunal, you didn’t mention it, but I assume that the multilinear extension is also submodular (say with respect to the max/min lattice on the reals?)
Suresh: I assume you mean that F(x+delta 1_i) – F(x) is non increasing in x. The last paper linked above, by Calinescu et al. shows that this is true in [0,1]^n, as the mixed second order partial derivatives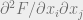 are negative.
are negative.
Yes, that’s what I meant. Thanks !