
[Guest post by Kush Bhatia and Cyrus Rashtchian, foreword by Gautam Kamath]
Welcome to ALT Highlights, a series of blog posts spotlighting various happenings at the recent conference ALT 2021, including plenary talks, tutorials, trends in learning theory, and more! To reach a broad audience, the series will be disseminated as guest posts on different blogs in machine learning and theoretical computer science. Boaz has kindly agreed to host a post in this series. This initiative is organized by the Learning Theory Alliance, and overseen by Gautam Kamath. All posts in ALT Highlights are indexed on the official Learning Theory Alliance blog.
This is the third post in the series, an interview with Constantinos Daskalakis and coverage of his ALT 2021 keynote talk, written by Kush Bhatia and Cyrus Rashtchian.
To make a decision for ourselves, we need to think about the impact of our actions to our objectives. But, when our actions affect other people and their actions affect our objectives, we also need to consider their incentives, and choose our actions in anticipation of theirs. This increase in complexity also occurs in situations involving multiple decision-making machines (e.g., self-driving cars), automated systems (e.g., algorithmic stock trading), or living organisms (e.g., groups of cells).
Studying decision-making in so-called multi-agent environments has been a question of interest to mathematicians and economists for centuries. In the 1830s, Antoine Augustin Cournot developed a theory of competition to model oligopolies, inspired by observing competition in a spring water duopoly. Jumping forward to the 20th century, researchers converged that a fruitful approach to analyzing multi-agent systems is studying them at “equilibrium”, that is, in situations where the system is stable in the sense that all parties are satisfied with their actions. A fundamental concept of equilibrium, studied by John von Neumann, and later by von Neumann and Oskar Morgenstern is a collection of actions, one per agent, such that no agent has an incentive to deviate from their choice given the actions of the other agents. While a nice proposal, they could only show that such equilibrium is guaranteed to exist in situations conforming to what is called a “two-player zero-sum game”. In such games, two agents are in exact competition with each other; whatever one player wins the other loses.1 In 1950, John F. Nash showed that this notion of equilibrium, named Nash equilibrium in his honor, indeed exists for most naturally occurring multi-agent problems.2
While Nash established the existence of equilibrium, one question bothered economists and computer scientists alike: “Is it possible to efficiently find the Nash equilibrium of a game?”
Throughout the rest of the 20th century, many people proposed algorithms for computing Nash equilibrium, but none of them succeeded in showing that it can be done efficiently (i.e., in polynomial time in the size of the game). During his early graduate school days at UC Berkeley, Constantinos (a.k.a. Costis) Daskalakis obsessed over this question. Then, in 2006, Costis, along with co-authors Paul Goldberg and Christos Papadimitriou, who was also his PhD advisor, showed a surprising result: finding a Nash equilibrium is computationally intractable!

 of basic material to procure while the other agent sets the price
of basic material to procure while the other agent sets the price 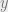 per unit of this material. If we let
per unit of this material. If we let  denote the revenue from selling the product produced using units of basic material, where
denote the revenue from selling the product produced using units of basic material, where 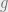 is a concave function of (capturing diminishing returns), then the overall utility of the agent choosing is
is a concave function of (capturing diminishing returns), then the overall utility of the agent choosing is 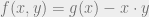 , an overall concave function. (b) Modern multi-agent problems involve agents choosing parameters of deep neural networks. This quickly leads to non-concave agent utilities.
, an overall concave function. (b) Modern multi-agent problems involve agents choosing parameters of deep neural networks. This quickly leads to non-concave agent utilities.A central concept in analyzing multi-agent systems is the utility function of each interacting agent. This is a function that captures the value that the agent derives as a function of their own action as well as those of the other agents. A common assumption is that the utility function of each agent is a concave function of their own action for any collection of actions committed by the others. Concavity often arises when agents trade off benefits and costs from their actions taking into account properties like diminishing returns and risk-aversion (see Figure 1 for an illustration). It is also crucial in guaranteeing that equilibria exist.
From Game Theory and Economics to Deep Learning
Recently, Costis has shifted his attention to the more general setting where the underlying utilities can be arbitrary non-concave functions of the agents’ actions. “Earlier, I was interested in the problem of equilibrium computation for its fundamental applications in Game Theory and Economics and its intimate connections to duality theory, topology and complexity theory. As Machine Learning is now moving towards multi-agent learning, studying more general setups arising from nonconcave agent utilities becomes increasingly relevant,” says Costis. He elaborates that the recent success of deep learning methods has largely been in single-agent setups and that the next frontier is to replicate this success in multi-agent settings. It is at this intersection of deep learning and multi-agent learning that non-concave utility functions arise — when actions correspond to setting the parameters of deep neural networks, agent utilities quickly become non-concave in the space of these parameters(see Figure 1).
The focus of Costis’ keynote talk, on joint work with Stratis Skoulakis and Manolis Zampetakis [DSZ21] was on the simplest multi-agent problem: two-player zero-sum games. In these games, two players, the min and the max player, choose actions 



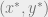

Thus the min (max) player has no incentive to deviate from 

![S=[0,1]^2](https://s0.wp.com/latex.php?latex=S%3D%5B0%2C1%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002)



Nonconvex-nonconcave utility functions naturally arise in adversarial training applications, such as Generative Adversarial Network (GAN) training, where the goal is to learn how to generate new data, such as images, from the same distribution that generated a collection of given data. Specifically, GANs are trained by trying to identify the equilibrium of a two-player zero-sum game between a generator model (the min player) and a discriminator model (the max player). Each of these models are viewed as agents, choosing parameters in deep neural networks, and the objective, capturing how close the generated distribution is to the target distribution, amounts to a nonconvex-nonconcave function of the underlying network parameters, which the min player aims to minimize and the max player aims to maximize.
Given that Nash equilibria may not exist when the objective is not convex-concave, what type of solutions should we target when studying two player zero-sum games with such objectives? “One property that we would like our target solutions to possess is that they are universal, i.e. they are guaranteed to exist for any objective function. We can take them to a practitioner and tell them that they are always plausible targets for their computations,” says Costis. With this in mind, Costis and his co-authors consider a relaxed equilibrium concept, called 
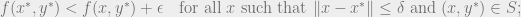

This relaxes Nash equilibrium: given strategy 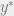



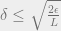
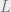
Can algorithms find a local Nash equilibrium?
The next question, pertaining to computational complexity, is to determine whether finding an 


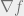
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

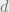
Theorem 1 (informal). First-order methods need a number of queries to
,
This theorem tells us that there exist objective functions for which the min-maximization problem can be computationally intractable for any first-order algorithm. Requiring many queries is one way to say that the problem is hard in practice. Indeed, practitioners have found it notoriously hard to get the discriminator-generator neural networks to converge to good solutions for generative modelling problems using gradient-based methods.
From a technical perspective, this work represents a new approach for proving lower bounds in optimization. Classical lower bounds in the optimization literature, going back to Nemirovsky and Yudin [NY83] target the black-box setting: an algorithm is given access to an oracle which outputs some desired information about a function when presented with a query. For example, a first-order oracle outputs the gradient of a function

That insight came when they switched to studying the complexity of the white-box version of the problem, wherein the optimization algorithm can look inside the oracle that computes 


In the white-box model, the authors show that the problem of computing local Nash equilibria is PPAD-complete. In other words, computing this local equilibrium concept in zero-sum games with nonconvex-nonconcave objectives is exactly as hard as computing Nash equilibria in general-sum games with concave agent utilities.3 This result is established by exhibiting a reduction from a variant of the Sperner coloring problem,4 which is a PPAD-complete problem, to a discrete nonconvex-nonconcave min-maximization problem, where the two agents choose points on a hypergrid.
Unexpected challenges in high dimensions
Having established this result, Costis and his coauthors presumed that the hardest part of the problem was behind them. However, another challenge awaited them. They still had to construct a continuous interpolation of their discrete function to satisfy the desired Lipschitz and smoothness properties in a computationally efficient manner. To understand the challenge with this, consider a simple two-dimensional example with two actions per agent. Suppose we are given prescribed values for 
![[0,1]^2](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E2&bg=eeeeee&fg=666666&s=0&c=20201002)

To obtain Theorem 1, the authors show that one can translate their complexity-theoretic hardness in the white-box model to an unconditional intractability result in the black-box model. This follows immediately from their reduction from Sperner to local Nash equilibrium. Indeed, finding local Nash equilibria in the min-max instance at the output of their reduction provides solutions to the Sperner instance at its input. Moreover, a single query (function value or gradient value) to the min-max objective requires 
This proof architecture can be used more generally to prove intractability results for optimization problems involving smooth objectives. First, ignore the black-box model and focus on identifying the complexity class that captures the complexity of the problem in the white-box model. Then, focus on obtaining a hardness result for a discrete version of the problem. Once this is established, one can use the techniques presented in this work to lift this intractability from the discrete to the continuous problem. If there are black-box lower bounds for any problem residing in the complexity class for which the white-box version of the problem is hard, then these lower bounds can be composed with hardness reductions to establish lower bounds for the black-box version of the problem. As an aside, Costis mentions that it would be interesting if one could establish the lower bound of Theorem 1 in the black-box model directly, i.e., without going through the PPAD machinery.
Looking forward
Costis ends on an optimistic note: “While this might appear as a negative result, it really is a positive one.” Explaining further, he says that a philosophical consequence of his intractability results is that the multi-agent future of deep learning is going to have a lot of interesting “texture” — it will involve a large breadth of communities and motivate a plethora of problems at the interface of theoretical computer science, game theory, economics and machine learning. Costis envisions a change in balance in the multi-agent world: while recent successes of deep learning in single-agent problems capitalize on access to large data, unprecedented computational power, and effective inductive biases, multi-agent problems will demand much stronger inductive biases, invoking domain expertise in order to develop effective models and useful learning targets, as well as to discover algorithms that attain those targets.
Indeed, domain expertise has been crucial in some recent high-profile machine learning achievements in multi-agent settings: the AlphaGo agent for playing the game of Go and the Libratus agent for playing Texas Hold’em. For these, a game-theoretic understanding has been infused into the structure and training of the learning algorithm. In addition to using deep neural networks, AlphaGo uses a Monte Carlo tree search procedure to determine the best next move as well as to collect data for the training of the neural networks during self play, while Libratus uses counterfactual regret minimization to approximate the equilibrium of the game. The success of both algorithms required combining machine learning expertise with game-theoretic expertise about how to solve the games at hand.
More broadly, Costis urges young researchers to move beyond the classical statistical paradigm which assumes independent and identically distributed observations, and embrace learning challenges that are motivated from learning problems with state, incomplete or biased data, data with dependencies, and multi-agent learning applications. In particular, he would like to see more activity in obtaining new models and algorithms for reinforcement and multi-agent learning, better tools for high-dimensional learning problems with data bias and dependencies, as well as deeper connections to causal inference and econometrics. “There is a lot of beautiful mathematics to be done and new continents to explore motivated by these challenges.”
Acknowledgements
We are thankful to Margalit Glasgow, Gautam Kamath, Praneeth Netrapalli, Arun Sai Suggala, and Manolis Zampetakis for providing valuable feedback on the blog. We would like to especially thank Costis Daskalakis for helpful conversations related to the technical and philosophical aspects of this work, and valuable comments throughout the writing of this article.
Notes
1 As we discuss later, this existence only holds when the gains of each player are a concave function of their own actions.
2 This led to Nash winning the Nobel prize in Economics in 1994 with John Harsanyi and Reinhard Selten.
3 PPAD is the complexity class that exactly captures the complexity of computing Nash equilibria in general-sum games, computing fixed points of Lipschitz functions in convex and compact domains, and many other equilibrium and fixed point computation problems.
4 In Sperner, we are given white-box access to a circuit that computes colors for the vertices of some canonical simplicization of the 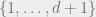

Bibliography
[DSZ21] Constantinos Daskalakis, Stratis Skoulakis, and Manolis Zampetakis. The complexity of constrained min-max optimization. Symposium on Theory of Computing, 2021
[HPV89] Michael D Hirsch, Christos H Papadimitriou, and Stephen A Vavasis. Exponential lower bounds for finding brouwer fixed points. Journal of Complexity, 1989.
[NY83] Arkadi S. Nemirovsky and David B. Yudin. Problem complexity and method efficiency in optimization. Wiley, 1983.
[Pap94] Christos H. Papadimitriou. On the complexity of the parity argument and other inefficient proofs of existence. Journal of Computer and System Sciences, 1994.
[Ros65] J. Ben Rosen. Existence and uniqueness of equilibrium points for concave n-person games. Econometrica, 1965.
[vN28] John von Neumann. Zur Theorie der Gesellschaftsspiele. In Mathematische annalen, 1928.

One thought on “ALT Highlights – Equilibrium Computation and the Foundations of Deep Learning”