As promised in the previous post, I will explain how an algorithm designed for the approximate near neighbor problem, the LSH algorithm, leads to a solution for the exact near neighbor problem (henceforth NNS). While, the algorithm for the exact problem will not have full guarantees, we will be able to give some partial guarantees.
Usually we want two guarantees from our algorithms:
1) the algorithm is correct, i.e., returns what we want. It will be OK for this to happen with 90% success probability (randomized algorithms).
2) the algorithm has good performance: time, space, etc (again, in expectation, or with 90% probability). Here we focus on bounded query time. E.g., LSH achieves ~


The approximation algorithm has both guarantees. Our exact algorithm will have only (1) but no hard guarantees on (2), the query time.
Let us first expand a bit on the algorithm for the approximate NNS. The LSH algorithm can be seen as a filtering algorithm: it will return a list 

– “good solution”: a near neighbor which is a point 
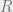
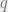
– “bad solution”: a far point which is a point at distance more than 

– “grey solution”: a point in the “grey area”, at distance between 
While I’m not explaining how LSH generates
Now, to obtain the approximate NNS algorithm, we just iterate through the set 

How do we obtain an exact NNS algorithm from this? Simply by requiring the algorithm to stop only when it finds a good solution, i.e., an actual near neighbor. Note that we immediately inherit the correctness guarantee (1): we output exactly what we want (with 90% success probability). But guarantee (2) may not hold anymore: while the set 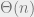
Discussion. So now we have an exact algorithm that is at least correct — but can we say more about the runtime? I mean, a linear scan algorithm would also be correct but not much progress.
As a start, we note the (expected) runtime is bounded by the number of bad and grey solutions in 
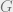
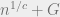
Have we made progress? For an adversarial dataset, the runtime can indeed degrade to
Indeed, the “real datasets” do not seem to be too adversarial. Here are some actual numbers for the MNIST dataset. It consists of 28×28 pixel images of handwritten images, represented as 784-dimensional Euclidean vectors, which we normalize to have norm one. (The actual LSH algorithm meant here is one for the Euclidean space, based on this paper.) Queries are 10 random points from the dataset itself, for which we would run LSH algorithm parametrized with 
I computed several quantities: the number of near neighbors (good solutions), 2-approximate near neighbor (grey solutions), and the expected size of list 





In conclusion, we have obtained an algorithm for the exact NNS from an algorithm for the approximate NNS. The algorithm is always correct. It may have bad runtime in the worst case, but, for reasonable datasets it may likely run considerably faster.
I will warp-up with a couple of questions. 1) Do you know of other algorithms with similar principles, especially algorithms for non-data structure problem (regular approximation algorithms)? For example, I can imagine a gradient-descent-like algorithm that: i) is correct, ii) is designed to achieve some approximation guarantee, and iii) if forced to give an exact solution, is reasonably fast on “good datasets”. 2) Is there a good “criteria for algorithm design” to extract? For example, one route may be defining a parametrization of the dataset as a function of the quality/structure of the grey&good solutions for the instance at hand; and then measuring the runtime of algorithms as a function of this quantity. That said, I do not have answers to these questions 🙂
