This post has some tidbits regarding the problem of computing a ‘fingerprint’ of a long sequence of characters, often called ‘string hashing’. Most of the results I will describe are quite old, but they are scattered upon several papers, so I think it is worthwhile to have a post where they are put together. This is of course not a survey.
In our setting we have a set  , which is typically very large – think for instance all strings of at most
, which is typically very large – think for instance all strings of at most  bits. A hash function
bits. A hash function 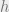 takes an item from and outputs a ‘fingerprint’ from a range
takes an item from and outputs a ‘fingerprint’ from a range 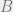 . Think of as say
. Think of as say 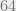 bits which is hopefully unique over a small set of items: we want to come up with a family of hash functions
bits which is hopefully unique over a small set of items: we want to come up with a family of hash functions 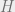 , such that for every pair of items
, such that for every pair of items  , when sampling from , the collision probability
, when sampling from , the collision probability 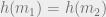 is small. The parameters we care about are
is small. The parameters we care about are 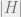 , since
, since  is a lower bound on the key size, that is the number of random bits needed to specify . We also care about the running time of , and of course the collision probability we obtain. In this post I will not discuss directly the running time of , though running time is arguably the most important parameter, instead I’ll focus on the tradeoff between the collision probability and .
is a lower bound on the key size, that is the number of random bits needed to specify . We also care about the running time of , and of course the collision probability we obtain. In this post I will not discuss directly the running time of , though running time is arguably the most important parameter, instead I’ll focus on the tradeoff between the collision probability and .
The first observation is that if we insist on having the collision probability as small as  , (
, ( in the example above), then must be roughly at least
in the example above), then must be roughly at least 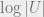 which means in the example above we will need a very long key.
which means in the example above we will need a very long key.
Denote by  the collision probability we want to obtain. Stinson proved that
the collision probability we want to obtain. Stinson proved that  which is roughly
which is roughly  when
when 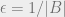 , but says very little when is slightly larger. A sketch of Stinson’s short and clever proof is at the end of the post.
, but says very little when is slightly larger. A sketch of Stinson’s short and clever proof is at the end of the post.
This bound is almost met by Carter and Wegman‘s classic multilinear hashing. Here is assumed to be a finite field, the items in are comprised of at most 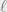 field elements, and the key
field elements, and the key  is comprised of
is comprised of  field elements sampled uniformly. The multilinear hash family is defined as
field elements sampled uniformly. The multilinear hash family is defined as 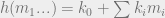 where all operations are in the field. If we forbid messages to end with zero then it is pairwise independent. A short proof could be found in a paper by Daniel Lemire.
where all operations are in the field. If we forbid messages to end with zero then it is pairwise independent. A short proof could be found in a paper by Daniel Lemire.
In practice we would be willing to sacrifice a little in the collision probability and have a hash function with a smaller key length, one that is closer to the length of the fingerprint, and that has a weaker dependency on the size of the domain. There are many ways of doing that, with various tradeoffs. Here are two general and quite straightforward methods. Lets call them recursive and iterative.
Recursive: The main idea is to compose weeker functions in a tree-like structure. The origin of this idea (as many others) is in Carter and Wegman. We use as a building block a hash function that takes as input shorter fixed length strings. To be concrete lets assume we have a family of functions that takes  bits and output bits. There are many good ways of designing such functions. The input is viewed as chunks of bits each and apply the hash function on each of these blocks, concatenating the output obtaining a string with
bits and output bits. There are many good ways of designing such functions. The input is viewed as chunks of bits each and apply the hash function on each of these blocks, concatenating the output obtaining a string with  chunks of . We repeat the operation on the new string, with a freshly sampled hash function, and so on. In total we need to sample
chunks of . We repeat the operation on the new string, with a freshly sampled hash function, and so on. In total we need to sample  such function. In the example above, if each of the hash functions has a key of bits, and the original input is bits, then the total length of keys turns out to be approximately
such function. In the example above, if each of the hash functions has a key of bits, and the original input is bits, then the total length of keys turns out to be approximately 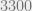 bits. The collision probability could be bounded by multiplying the collision probability of the basic hash functions with the number of iterations,
bits. The collision probability could be bounded by multiplying the collision probability of the basic hash functions with the number of iterations, 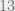 in this case. Mikkel Thorup has a more detailed description and some experiments here, as does Sarkar.
in this case. Mikkel Thorup has a more detailed description and some experiments here, as does Sarkar.
Iterative: This idea is known by various names such as CBC-MAC and Pearson hashing. Here we assume the message is comprised of at most blocks of  bits each:
bits each: 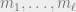 . The hash function is indexed by a permutation
. The hash function is indexed by a permutation  . The
. The  stage of the computation has state
stage of the computation has state  . Starting with
. Starting with  the function iteratively computes
the function iteratively computes  . The output is
. The output is  . Ideally we would have liked the permutation to be completely random, this cannot be done for reasonable values of , so in practice a pseudorandom permutation is used, though the exact definition of pseudorandomness in this context could be debated. Assuming the permutation is indeed random, what is the collision probability? It is shown here to be
. Ideally we would have liked the permutation to be completely random, this cannot be done for reasonable values of , so in practice a pseudorandom permutation is used, though the exact definition of pseudorandomness in this context could be debated. Assuming the permutation is indeed random, what is the collision probability? It is shown here to be 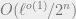 as long as
as long as  . The proof holds for a stronger attack model. I do not see an inherent reason for the bound on .
. The proof holds for a stronger attack model. I do not see an inherent reason for the bound on .
I now sketch Stinson’s proof for the bound mentioned above, which is a nice application of the second moment method. Recall that denotes the domain, the range is denoted by and its size by 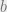 . The collision probability is denoted by . For every
. The collision probability is denoted by . For every  and
and  let
let  denote
denote  . Now let’s pick some specific and
. Now let’s pick some specific and  . For every
. For every  and
and  define
define  , i.e. the number of items that are mapped to by and to
, i.e. the number of items that are mapped to by and to  by
by 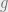 . Let
. Let  denote the expected size of
denote the expected size of  when is sampled from and from
when is sampled from and from  . A moment’s reflection shows this average to be
. A moment’s reflection shows this average to be  (for each item in
(for each item in 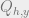 we have a
we have a  chance of guessing right where it lands under ). The key observation is that in order for to be large, many items should collide on under , which is unlikely, so the fact that the collision probability of is bounded gives us a handle on the variance of . This in turn would imply a bound on . Consider two items
chance of guessing right where it lands under ). The key observation is that in order for to be large, many items should collide on under , which is unlikely, so the fact that the collision probability of is bounded gives us a handle on the variance of . This in turn would imply a bound on . Consider two items 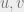 in . Since they collide under , there are at most
in . Since they collide under , there are at most  other function under which they collide. So,
other function under which they collide. So,

changing the order of summation this means

Moving things around we have
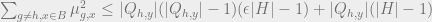
So we have an upper bound on the second moment of in terms of and  . Of course we also know that the variance of is non negative, which after calculations implies the bound. Finally in order to get a bound in terms of
. Of course we also know that the variance of is non negative, which after calculations implies the bound. Finally in order to get a bound in terms of  we observe that we can pick and such that is at least
we observe that we can pick and such that is at least  .
.
