One great “soft” challenge in (T)CS I find to be how to go on to find useful algorithms for problems that we believe (or have even proven!) to be hard in general. Let me explain by giving the all-too-common-example:
Practitioner: I need to solve problem X.
Theoretician: Nice question, let me think… Hm, it seems hard. I can even prove that, under certain assumptions, we cannot do anything non-trivial.
Practitioner: Slick… But I still need to solve it. Can you do anything?
Theoretician: If I think more, I can design an algorithm that gives a solution up to factor 2 within the actual solution!
Practitioner: Interesting, but that’s too much error nonetheless… How about 1.05?
Theoretician: Nope, essentially as hard as exact solution.
Practitioner: Thanks. But I still need to deliver the code in a month. I guess I will go and hack something by myself — anyways my instances are probably not degenerately hard.
What can we give to the practitioner in this case?
Over years, the community has come up with a number of approaches to the challenge. In fact, last fall, Tim Roughgarden and Luca Trevisan organized a great workshop, on “Beyond Worst-Case Analysis”. Besides designing approximation algorithms (mentioned above), one of the other common approaches is to design algorithms for certain subsets of instances of problem X (planar graphs, doubling metrics, or, abusing the notion a bit, average/semi-random instances).
Here, I would like to discuss a scenario where an approximation algorithm lead to an *exact* algorithm (with some guarantees). In particular, I will talk about the case of the Locality Sensitive Hashing (LSH) algorithm for the near(est) neighbor search (NNS) problem in high dimensional spaces.
While I hope to discuss the NNS problem in detail in future posts, let me quickly recap some definitions. The nearest neighbor search problem is the following data structure question. Given a set 

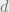
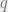
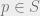
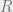

This problem is a classical example of the curse of dimensionality: while the problem has nice, efficient solutions for small 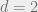
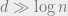
What is the approximate version of the 



The LSH framework, introduced by Piotr Indyk and Rajeev Motwani in 1998, yields an algorithm for the 
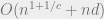


Now we are in the case at the end of the above dialogue. What’s next?
It turns out that the LSH algorithm may be used to solve the exact near neighbor search, with some, relaxed guarantees, as I will explain in the next post.

2 thoughts on “Exact Algorithms from Approximation Algorithms? (part 1)”