In a previous blog post, we saw how ideas from differential privacy can be used to prove a lower bound on the hereditary discrepancy for the Erdös Discrepancy problem. This lower bound happened to be nearly tight.
It turns out that this tightness is no accident. The connection between hereditary discrepancy and privacy is in fact much deeper, and can be used to get an approximation algorithm for hereditary discrepancy of any set system. In this post, I will try to summarize this connection.
First, let us recall the definition of hereditary discrepancy. For a matrix 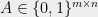 , the discrepancy of
, the discrepancy of  is defined as
is defined as 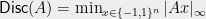 . Thus we want to multiply each column of by either
. Thus we want to multiply each column of by either  or
or 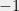 so that each row sum is at most
so that each row sum is at most 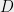 in absolute value. The smallest attainable is the discrepancy of .
in absolute value. The smallest attainable is the discrepancy of .
It may be worth mentioning a 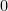 –
–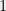 matrix corresponds to a set system with elements corresponding to columns and sets corresponding to rows. The vector
matrix corresponds to a set system with elements corresponding to columns and sets corresponding to rows. The vector  then corresponds to a coloring of the elements and the discrepancy measures how balanced all of the sets are. Nevertheless, the definition above, and everything I will say about discrepancy, extends to arbitrary real matrices .
then corresponds to a coloring of the elements and the discrepancy measures how balanced all of the sets are. Nevertheless, the definition above, and everything I will say about discrepancy, extends to arbitrary real matrices .
Hereditary discrepancy is a more robust variant of this definition: the hereditary discrepancy 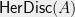 is simply the maximum of
is simply the maximum of 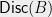 , taken over all sub-matrices
, taken over all sub-matrices 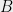 of .
of .
To start with, note that one can prove that 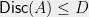 by exhibiting a vector attaining such a bound, and this witness can be efficientl verified. Computing the discrepancy itself is NP-hard, even to approximate. In fact Charikar, Newman and Nikolov show that it is hard to distinguish between discrepancy zero and discrepancy
by exhibiting a vector attaining such a bound, and this witness can be efficientl verified. Computing the discrepancy itself is NP-hard, even to approximate. In fact Charikar, Newman and Nikolov show that it is hard to distinguish between discrepancy zero and discrepancy 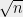 . Thus one does not expect to find efficiently verifiable proofs of lower bounds on discrepancy.
. Thus one does not expect to find efficiently verifiable proofs of lower bounds on discrepancy.
Proving a good upper bound on hereditary discrepancy seems harder: how would I convince you that every sub-matrix has a good coloring? It turns out that 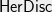 being is equivalent to being totally unimodular, and this can be efficiently checked. For higher no such characterization is known, and in fact deciding whether the is
being is equivalent to being totally unimodular, and this can be efficiently checked. For higher no such characterization is known, and in fact deciding whether the is 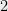 or
or 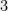 can be shown to be NP hard. One would think (and some of us tried to prove) that herdisc would be at least as hard to approximate as discrepancy. However, one would be wrong. Herdisc is in fact approximable to a polylogarithmic factor. This result fell out of our attempts to understand how much noise differentially private mechanisms must add to a given set of linear queries. In this post, I will try to sketch how we get an approximation to . See the paper for more details (Since the primary focus of the paper is on questions in Differential Privacy, large parts of it do not pertain to the approximation to . If you are mainly interested in that approximation, I hope this post will help figure out which parts are relevant.)
can be shown to be NP hard. One would think (and some of us tried to prove) that herdisc would be at least as hard to approximate as discrepancy. However, one would be wrong. Herdisc is in fact approximable to a polylogarithmic factor. This result fell out of our attempts to understand how much noise differentially private mechanisms must add to a given set of linear queries. In this post, I will try to sketch how we get an approximation to . See the paper for more details (Since the primary focus of the paper is on questions in Differential Privacy, large parts of it do not pertain to the approximation to . If you are mainly interested in that approximation, I hope this post will help figure out which parts are relevant.)
The Partial Coloring technique
A very useful technique in discrepancy theory is that of partial coloring. Suppose that we can find a 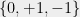 vector
vector  such that
such that 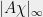 is some value
is some value 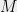 and has many non-zeroes, say
and has many non-zeroes, say  . Let’s for convenience call the least attainable such as the partial discrepancy of , and let
. Let’s for convenience call the least attainable such as the partial discrepancy of , and let  denote the analogous hereditary version, i.e. the maximum partial discrepancy over all sub-matrices of .
denote the analogous hereditary version, i.e. the maximum partial discrepancy over all sub-matrices of .
The partial coloring trick basically says that 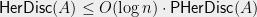 for any : we can find a good coloring by repeatedly finding good partial colorings. Each step reduces the number of uncolored columns by at least a constant factor, so that in
for any : we can find a good coloring by repeatedly finding good partial colorings. Each step reduces the number of uncolored columns by at least a constant factor, so that in  steps, we get a complete coloring.
steps, we get a complete coloring.
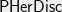 and Privacy
and Privacy
, it turns out, is closely related to differential privacy. Muthukrishnan and Nikolov, building on Dinur-Nissim, showed that the any minimally private algorithm to compute an approximation to 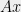 , fo r a private database , must incur additive error at least as large as the hereditary discrepancy of . Let me now explain this statement in a little more detail.
, fo r a private database , must incur additive error at least as large as the hereditary discrepancy of . Let me now explain this statement in a little more detail.
Imagine we have a database which contains private data of individuals. For a start, suppose that is a – vector, where the 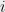 th coordinate is a private bit of the th individual (the results actually apply to a more general setting, but this version should suffice for this blog post). An analyst is interested in learning some set of
th coordinate is a private bit of the th individual (the results actually apply to a more general setting, but this version should suffice for this blog post). An analyst is interested in learning some set of 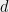 aggregates, represented by a
aggregates, represented by a 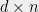 matrix , i.e. she wants to learn . The analyst is also potentially an attacker, and may know something about the database, possibly from other auxiliary sources. Suppose that she knows some coordinates of already, and our privacy policy requires that we do not enable her to learn the unknown bits when we answer the query.
matrix , i.e. she wants to learn . The analyst is also potentially an attacker, and may know something about the database, possibly from other auxiliary sources. Suppose that she knows some coordinates of already, and our privacy policy requires that we do not enable her to learn the unknown bits when we answer the query.
As you might be thinking, this would be impossible to guarantee if we respond with the correct answer . So we will in fact give a noisy answer in such a way that privacy is guaranteed in a formal sense, and we try to give as accurate an answer as possible. Let us say we want all of our queries to be accurate within an expected additive error of 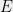 . How small can we make while avoiding a serious privacy violation?
. How small can we make while avoiding a serious privacy violation?
Let us say that a serious privacy violation occurs if an adversary who knows some  bits of , after learning the noisy answer to , can produce her guess
bits of , after learning the noisy answer to , can produce her guess 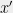 which differs from in
which differs from in 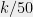 bits. In other words, the adversary learns pretty much all of . Suppose is
bits. In other words, the adversary learns pretty much all of . Suppose is  . Then we will argue that must be at least
. Then we will argue that must be at least 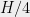 to avoid a serious privacy violation.
to avoid a serious privacy violation.
Let be a sub-matrix of achieving partial discrepancy , and let 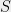 denote the indices of the columns of . Consider an analyst that knows on
denote the indices of the columns of . Consider an analyst that knows on  and is trying to learn on , and without loss of generality, suppose that is zero on . Let
and is trying to learn on , and without loss of generality, suppose that is zero on . Let 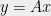 , and let
, and let 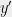 be the answer we give in an attempt to avoid a serious privacy violation. By definition of discrepancy, for any
be the answer we give in an attempt to avoid a serious privacy violation. By definition of discrepancy, for any  supported on with
supported on with 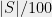 non-zero entries,
non-zero entries,  is at least . Suppose that
is at least . Suppose that 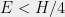 , and let be any – vector such that
, and let be any – vector such that 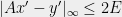 . By Markov\rq{}s inequality, satisfies this with probability half, in which case such an
. By Markov\rq{}s inequality, satisfies this with probability half, in which case such an  exists. By triangle inequality,
exists. By triangle inequality, 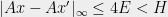 . Thus
. Thus 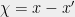 is a vector in
is a vector in 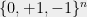 satisfying
satisfying  . It must therefore be the case that has fewer than non-zeroes, so that agrees with on all but coordinates. This of course is a serious privacy violation, establishing that any minimally private mechanism must add error per entry. We have thus established that error of any private mechanism for is at least .
. It must therefore be the case that has fewer than non-zeroes, so that agrees with on all but coordinates. This of course is a serious privacy violation, establishing that any minimally private mechanism must add error per entry. We have thus established that error of any private mechanism for is at least .
Approximating
I will next try to argue how to get from this a polylogarithmic approximation algorithm for , and hence for . Note that an  approximation algorithm, given a matrix must for some produce two certificates: one certifying that is at least
approximation algorithm, given a matrix must for some produce two certificates: one certifying that is at least  , and another certifying that it is at most . For example, the first certificate may consist of a sub-matrix and a dual solution for an SDP relaxation for the discrepancy of . A simpler witness can be constructed based on a result of Lovász, Spencer and Vesztergombi, who gave a beautiful geometric argument showing that the determinant of any square sub-matrix of , appropriately normalized, gives a lower bound on . Thus a square sub-matrix such that the resulting lower bound
, and another certifying that it is at most . For example, the first certificate may consist of a sub-matrix and a dual solution for an SDP relaxation for the discrepancy of . A simpler witness can be constructed based on a result of Lovász, Spencer and Vesztergombi, who gave a beautiful geometric argument showing that the determinant of any square sub-matrix of , appropriately normalized, gives a lower bound on . Thus a square sub-matrix such that the resulting lower bound  is large could form a good witness. Matousek recently showed that there always exists such a witness that is nearly optimal, but left open the question of finding it.
is large could form a good witness. Matousek recently showed that there always exists such a witness that is nearly optimal, but left open the question of finding it.
The second certificate seems less obvious: how would I convince you that for every sub-matrix , there is a good coloring? The above privacy argument comes to the rescue here. Suppose my witness consisted of the description of a random variable with the following properties:
- The mechanism that outputs
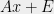 satisfies a reasonable privacy definition, that rules out a serious privacy violation.
satisfies a reasonable privacy definition, that rules out a serious privacy violation.
- The expectation of the
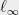 norm of is at most some value
norm of is at most some value  .
.
Since a serious privacy violation is ruled out, the expected error must be at least , and thus we can conclude that is at most .
In our case, the reasonable privacy definition will be 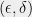 -differential privacy. Regular readers of this blog are no doubt familiar with the definition, and for this post, it will suffice that this definition guards against serious privacy violation (and much more). We show that for any , we can find a sub-matrix and a random variable which satisfies the above two properties, with bounded by polylog(d) times . Thus we get a mechanism that is within
-differential privacy. Regular readers of this blog are no doubt familiar with the definition, and for this post, it will suffice that this definition guards against serious privacy violation (and much more). We show that for any , we can find a sub-matrix and a random variable which satisfies the above two properties, with bounded by polylog(d) times . Thus we get a mechanism that is within 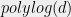 of the optimal mechanism, and additionally certifies a near-tight upper bound on the hereditary discrepancy.
of the optimal mechanism, and additionally certifies a near-tight upper bound on the hereditary discrepancy.
How do we construct such a mechanism? That is a slightly longer story and I will only sketch the main ideas. First, we move from to 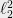 at a polylogarithmic loss: intuitively, measures an average, and measures the max. The minimax theorem or Boosting or Multiplicative weights technique ensures that an algorithm for minimizing the average can be translated to one that minimizes the maximum. This kind of reduction is relatively standard and I will skip it here.
at a polylogarithmic loss: intuitively, measures an average, and measures the max. The minimax theorem or Boosting or Multiplicative weights technique ensures that an algorithm for minimizing the average can be translated to one that minimizes the maximum. This kind of reduction is relatively standard and I will skip it here.
How do we find an -differentially private mechanism minimizing the error? It turns out that if the columns of (i.e. the vectors  ) all lie in a ball of radius
) all lie in a ball of radius  around the origin, then it is enough to add Gaussian noise of magnitude
around the origin, then it is enough to add Gaussian noise of magnitude  in each coordinate of , where
in each coordinate of , where 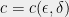 is a constant depending on
is a constant depending on  and
and 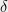 alone. This result in fact predates the definition of differential privacy: intuitively, one person entering or leaving the database can cause a perturbation of size in the value of , and thus adding Gaussian noise to hide such a perturbation is sufficient to guarantee privacy.
alone. This result in fact predates the definition of differential privacy: intuitively, one person entering or leaving the database can cause a perturbation of size in the value of , and thus adding Gaussian noise to hide such a perturbation is sufficient to guarantee privacy.
There is of course no reason for this mechanism to be anywhere near optimal, and in general it is not. However, it turns out that if this ball of radius happens to be the Minimum volume Ellipsoid that contains all the points 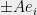 (also known as the John-Loewner Ellipsoid of this set of points), then we have a lot more structure to work with. A result of John, combined with the restricted invertibility theorem of Bourgain and Tzafriri guarantees that in this case, one can find
(also known as the John-Loewner Ellipsoid of this set of points), then we have a lot more structure to work with. A result of John, combined with the restricted invertibility theorem of Bourgain and Tzafriri guarantees that in this case, one can find 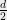 of the columns of that have norm and are nearly orthogonal. Armed with these, and using the rotational invariance of the
of the columns of that have norm and are nearly orthogonal. Armed with these, and using the rotational invariance of the 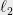 version of discrepancy, we can easily come up with a sub-matrix that certifies that the simple Gaussian mechanism is nearly optimal. Intuitively, the nearly orthogonal columns define a simplex with large volume, which gives the determinant lower bound.
version of discrepancy, we can easily come up with a sub-matrix that certifies that the simple Gaussian mechanism is nearly optimal. Intuitively, the nearly orthogonal columns define a simplex with large volume, which gives the determinant lower bound.
Of course in general, we will not be lucky enough to get a ball as the John-Loewner Ellipsoid. Suppose we get as the John-Loewner Ellipsoid. Let 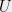 be the subspace spanned by the longest axes of , and let
be the subspace spanned by the longest axes of , and let  be the complement subspace. Further let be the length of the th longest axis. It turns out that a generalization of Bourgain-Tzafriri due to Vershynin can still be used to find a good in
be the complement subspace. Further let be the length of the th longest axis. It turns out that a generalization of Bourgain-Tzafriri due to Vershynin can still be used to find a good in 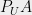 , where
, where 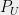 is the projection matrix for . Moreover, since
is the projection matrix for . Moreover, since  is contained in a ball of radius , we can define a mechanism for the projection
is contained in a ball of radius , we can define a mechanism for the projection  that has error within a constant factor of the determinant lower bound that we get from . This gives us some progress towards outputting . We next recursively find a mechanism for
that has error within a constant factor of the determinant lower bound that we get from . This gives us some progress towards outputting . We next recursively find a mechanism for 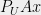 . Since we halve the dimension in each iteration, we have at most
. Since we halve the dimension in each iteration, we have at most  iterations. We can use standard privacy machinery to ensure that the overall mechanism satisfies differential privacy. Since each step of the recursion has error within a constant factor of a lower bound output in that step, our overall error is within a polylog factor of one of the lower bounds. This completes the rough sketch of the mechanism. See the paper for full details.
iterations. We can use standard privacy machinery to ensure that the overall mechanism satisfies differential privacy. Since each step of the recursion has error within a constant factor of a lower bound output in that step, our overall error is within a polylog factor of one of the lower bounds. This completes the rough sketch of the mechanism. See the paper for full details.
Thus we now know that hereditary discrepancy is approximable to a polylog factor, and not approximable better than a factor of 1.5. Closing, or even narrowing this gap is an interesting open problem.
Many thanks to Alex Nikolov and Li Zhang for his contribution to the content and the writing of this post.
Edit 2/13: Edited to fix the missing link to the paper.

Great stuff! I look forward to understanding your work. You may wish to email a copy to Joel Spencer — he would be delighted to see the herdisc result.
Thanks for the kind words. I will email a copy to Joel.