
Scribe notes by Hamza Chaudhry and Zhaolin Ren
Previous post: Natural Language Processing – guest lecture by Sasha Rush Next post: TBD. See also all seminar posts and course webpage.
See also video of lecture. Lecture slides: Original form: main / bandit analysis. Annotated: main / bandit analysis.
Sham Kakade is a professor in the Department of Computer Science and the Department of Statistics at the University of Washington, as well as a senior principal researcher at Microsoft Research New York City. He works on the mathematical foundations of machine learning and AI. He is the recipient of the several awards, including the ICML Test of Time Award (2020), the IBM Pat Goldberg best paper award (in 2007), and the INFORMS Revenue Management and Pricing Prize (2014).
Sham is writing a book on the theory of reinforcement learning with Agarwal, Jiang and Sun.
Introduction:
Reinforcement learning has found success in a great number of fields because it is a very “natural framework” for interactive learning. It is based around the notion of experimenting with different behaviors in one’s environment and learning from mistakes to identify the optimal strategy. However, there is a lack of understanding regarding how to best optimize reinforcement learning algorithms when there is uncertainty about the agent’s environment and potential rewards. Therefore, it is important to develop a theoretical foundation about this to study generalization in reinforcement learning. The primary question these notes will address is as follows:
What are necessary representational and distributional conditions that enable provably sample-efficient reinforcement learning?
We will answer this question in the following parts.
- Part I: Bandits & Linear Bandits “Bandit problems” correspond to RL where the environment is reset in each step (horizon H=1). This captures the aspect of having an unknown reward function of RL, but does not capture the aspect of a changing environment based on agent’s actions. This part will be based on the papers Dani-Hayes-Kakade 08 and Srinivas-Kakade-Krause-Seeger 10
- Part II: Lower Bounds RL is very much not a solved problem in neither theory nor practice. Even the RL analog of linear regression, when the expected reward is a linear function of the actions, is not solved. We will see that this is for a good reason: there is an exponential lower bound on the number of steps it takes to find a nearly-optimal policy in this case. This part is based on the recent paper Weisz-Amortila-Szepesvári 20 and the follow-up Wang-Wang-Kakade 21
- Interlude: Do these lower bounds matter in practice?
- Part III: Upper Bounds Given the lower bound, we see that to get positive results (aka upper bounds on the number of steps) we need to make strong assumptions on the structure of reqards. There have been a number of incomparable such assumptions used, and we will see that there is a way to unify them. This part is based on the recent paper Du-Kakade-Lee-Lovett-Mahajan-Sun-Wang 21
Before all of these parts, we will start by introducing the general framework of Markov Decision Processes (MDPs) and do a quick tour of generalization for static learning and RL.
Markov Decision Processes: A Framework for Reinforcement Learning
We have an agent in an environment at state 

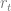

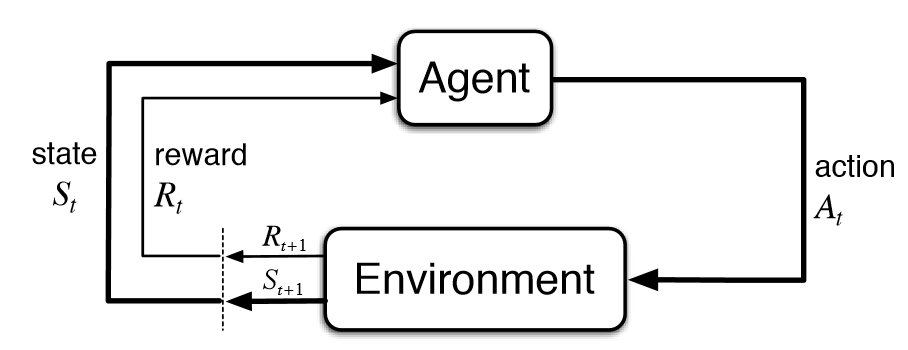
The following are some key terms that we will need throughout the rest of the notes:
- State Space, Action Space, Policy: We denote the state space as
, and the action space as
. A policy
is a mapping from states to actions:
- Trajectory: The sequence of states, actions, rewards an agent sees for a horizon of
timesteps.
- State Value at time
: The expected cumulative reward starting from state
and using policy
- State Action Value at time
starting from time
- Optimal value and state-value function: we define an optimal policy by
, and the associated optimal
-function and value function by
and
respectively (or equivalently,
,
). Note that
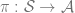
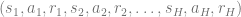
![V_h^\pi(s) = \mathbb{E} \left[ \sum_{t=h}^{H} r_t \vert s_h = s \right]](https://s0.wp.com/latex.php?latex=V_h%5E%5Cpi%28s%29+%3D+%5Cmathbb%7BE%7D+%5Cleft%5B+%5Csum_%7Bt%3Dh%7D%5E%7BH%7D+r_t+%5Cvert+s_h+%3D+s+%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![Q_h^\pi(s,a) = \mathbb{E} \left[ \sum_{t=h}^{H} r_t \vert s_h = s, a_h = a \right]](https://s0.wp.com/latex.php?latex=Q_h%5E%5Cpi%28s%2Ca%29+%3D+%5Cmathbb%7BE%7D+%5Cleft%5B+%5Csum_%7Bt%3Dh%7D%5E%7BH%7D+r_t+%5Cvert+s_h+%3D+s%2C+a_h+%3D+a+%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)

![Q_h^\star(s,a) = \mathbb{E}\left[R_h(s,a) + V_{h+1}^\star(s_{h+1}) \mid s_h = s, a_h = a \right]](https://s0.wp.com/latex.php?latex=Q_h%5E%5Cstar%28s%2Ca%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5BR_h%28s%2Ca%29+%2B+V_%7Bh%2B1%7D%5E%5Cstar%28s_%7Bh%2B1%7D%29+%5Cmid+s_h+%3D+s%2C+a_h+%3D+a+%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
where we additionally define 
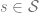
- Goal: To find a policy
starting from an initial state
, acts for
Challenges in Reinforcement Learning
There are three main challenges that we face in reinforcement learning
- Exploration: The total size and states of the environment may be unknown.
- Credit Assignment: We need to assign rewards to actions even if the rewards are delayed.
- Large State/Action Spaces: We face the curse of dimensionality.

We will deal with these problems by framing them in terms of generalization.
Part 0: A Whirlwind Tour of Generalization
Provable Generalization in Supervised Learning
As we have seen in the first lecture of this course, generalization is possible in the supervised learning setting, when the data follows an i.i.d distribution.
Specifically we have the following bound
Occam’s Razor Bound (Finite Hypothesis Class): To learn a policy that is
close to the best policy in a hypothesis class
, we need a number of samples that is
.
This means we can try lots of things on our data to see which hypotheses are 
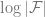
- VC Dimension:
- Classification (Margin Bounds):
- Linear Regression:
- Deep Learning: Algorithm also determines the complexity control
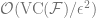


Another way to say this is that in all of these cases, we can bound the generalization gap 
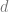

One reference for these generalization results in the supervised learning setting is the following book by Sanjeev Arora and collaborators.
The key enabler of generalization in supervised learning is data reuse. For a given training set, we can in principle simultaneously evaluate the loss of all hypotheses in our class. For example, given the fixed ImageNet dataset, we can evaluate performance on any classifier. As we will see, this is not a property that will always hold in RL (when it does hold, sample-efficient generalization is likely to follow).
Sample Efficient RL in the Tabular Case with few states and actions (No Generalization involved):
Consider a tabular MDP setting where 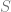

Our goal in such a setting is to find a 
Think for example of the following maze MDP, where the state of the world is the cell the agent is in and the action it can take at each state is a move to each of say 4 neighboring cells. Then, if we are able to get to every state and try every action there, we would have learned the world.

In this particular scenario, randomly exploring the world will allow us to learn the world. However, if we consider a modified random exploration strategy, where the probability of going left is significantly larger (say 5 times larger) than the probability of going right, then it will take exponential time to hit the goal state. In general, even for MDPs with small state and action spaces, a purely random exploration approach may be insufficient, as we may not be exploring the world enough. What alternative approach might we then adopt in order to achieve a sample-efficient learning algorithm?
Theorem: (Kearns & Singh ’98). In the episodic setting,
samples suffice to find an
The above breakthrough result was the first to demonstrate that learning an 
Based on the Kearns and Singh result, there has been a number of followup works on the tabular MDP setting. One line of work seeks to improve on the precise factors in the sample complexity.
Improvements on the sample complexity:
- A General Polynomial Time Algorithm for Near-Optimal Reinforcement Learning / Brafman-Tennenholtz 2002
- On the Sample Complexity of Reinforcement Learning – Kakade 2003 (PhD Thesis).
- Near-Optimal Regret Bounds for Reinforcement Learning – Jaksch, Ortner, Auer 2010
- Posterior sampling for reinforcement learning: worst-case regret bounds – Agrawal Jia 2017
Another line of work seeks to show that Q-learning, a model-free approach, can also achieve similar polynomial complexity, if an appropriate optimism bonus is incorporated.
Provable Q-Learning (+Bonus)
- PAC Model-Free Reinforcement Learning – Strehl-Li-Wiewiora-Langford-Littman 2006
- Algorithms for Reinforcement Learning – lecture by Szepesv´ari 2009
- Is Q-learning Provably Efficient? – Jin Allen-ZhuBubeck Jordan 2018
As the range and technical depth of the above results demonstrate, even in the relatively simple tabular case, the problem is already challenging, and a precise sharp characterization of sample complexity is even more difficult. The chief source of difficulty is the unknown nature of the world (if the world was known, then we can just run dynamic programming).
Provable Generalization in RL:
Ultimately, we want to move beyond small tabular MDPs, where a polynomial dependence in the sample complexity on

In such a setting, requiring polynomially (in
Question 1: Can we find an
In order to do so, it is necessary to reutilize data in some way since we will not be able to see all the possible states in the world. How then might we reuse data to estimate the value of all policies in a policy class
- Idea: Trajectory tree algorithm
- Dataset Collection: Choose actions uniformly at random for all H steps in an episode.
- Estimation: Uses importance sampling to evaluate every
.
Theorem: (Kearns, Mansour, & Ng ’00) To find an
samples.
Observe that when 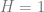

We note that the result only has 

This
Question 2: Can we find an 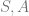

As we just saw, agnostically we cannot learn an
To do so, we start simple, and first look at the bandits and linear bandits problem, where the horizon
Part 1: Bandits and Linear Bandits
Multi-Armed Bandits:

The multi-armed bandits algorithm is intimately interwoven with the theory of reinforcement learning. It is based around the question of how to allocate T tokens to A “arms” to maximize one’s return:
- Some Aspects of the Sequential Design of Experiments – Robbins 1952
- Bandit Processes and Dynamic Allocations Indices – Gittins 1979
- Asymptotically Efficient Adaptive Allocation Rules – Lai and Robbins 1985
It is a very successful algorithm when
Large-Action Case:
The bandits have to make a decision regarding which arm to pull. There is a widely used linear formulation of this problem that will assist us in understanding generalization. The linear bandit model is successful in many applications (scheduling, ads, etc.)
Linear (RKHS) Bandits:
- Decision:
; Reward:
; Reward model:
- The hypothesis class

Linear/Gaussian Process Upper Confidence Bounds (UCB):
The principle underlying the Linear Bandits algorithm is optimism in the face of uncertainty:
Pick an input that maximizes the upper confidence bound:
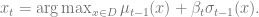
Note that 

Regret of Linear-UCB / Gaussian Process-UCB (Generalization in Action Space)
Theorem: (Dani, Hayes, & K. ’08), (Srinivas, Krause, K., & Seeger ’10). Assuming
wherehides logarithmic terms, and
![\frac{1}{T} \sum_{t=1}^T[f(x^\star) - f(x_t)] = \tilde{\mathcal{O}} \left( \sqrt{\frac{\gamma_T}{T}} \right),](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7BT%7D+%5Csum_%7Bt%3D1%7D%5ET%5Bf%28x%5E%5Cstar%29+-+f%28x_t%29%5D+%3D+%5Ctilde%7B%5Cmathcal%7BO%7D%7D+%5Cleft%28+%5Csqrt%7B%5Cfrac%7B%5Cgamma_T%7D%7BT%7D%7D+%5Cright%29%2C&bg=ffffff&fg=666666&s=0&c=20201002)
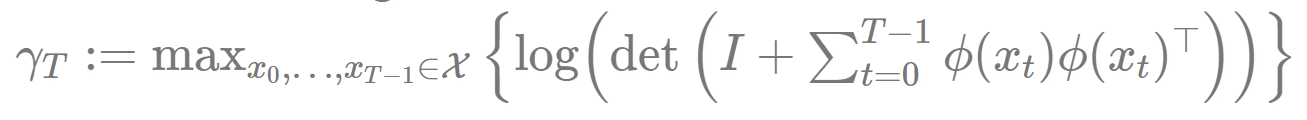
The key complexity concept here is “Maximum Information Gain”: 

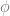

- Finite-time Analysis of the Multiarmed Bandit Problem – Auer Cesa-Bianchi Fischer 2002
- Improved Algorithms for Linear Stochastic Bandits – Abbasi-yadkori, Pál, Szepesvári 2011
Linear Upper Confidence Bound Analysis
Handling Large Action Spaces
On each round, we must choose a decision 
![r_t \in [-1,1]](https://s0.wp.com/latex.php?latex=r_t+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![\mathbb{E}[r_t | x_t = x] = \mu^\star \cdot x \in [-1,1].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Br_t+%7C+x_t+%3D+x%5D+%3D+%5Cmu%5E%5Cstar+%5Ccdot+x+%5Cin+%5B-1%2C1%5D.&bg=ffffff&fg=666666&s=0&c=20201002)
Above, 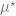

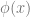
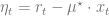
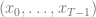

where 

LinUCB and the Confidence Ball
After t rounds, we can define our uncertainty region 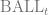
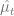
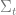




The LinUCB Algorithm can be understood as follows: For
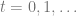
- Execute
- Observe the reward
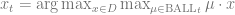

LinUCB Regret Bound
As the following theorem shows, the regret 

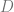
Theorem (regret): (Dani, Hayes, Kakade 2009). Suppose we have bounded noise
;
;
, for
. Set
Then, with probability greater than
, for all
,
whereare absolute constants.

To prove the regret theorem above, we will require the following two lemmas.
Lemma 1 (Confidence): Let
. We have that
Lemma 2 (Sum of Squares Regret Bound): Define
. Suppose
is increasing and that for all
, we have
. Then,
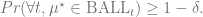
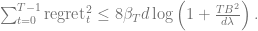
We note that Lemma 2 actually depends on Lemma 1, since it assumes that 
Proof of regret theorem: Using the two lemmas above along with the Cauchy-Schwarz inequality, we have with probability at least
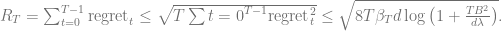
The rest of the proof follows from our chosen value of 

We now proceed to sketch out the proofs of Lemma 1 (confidence bound) and Lemma 2 (sum of squares regret bound). We begin with showing why Lemma 2 holds.
Analysis and proof of Lemma 2 (sum of squares regret bound)
Our first auxilliary result bounds the pointwise width of the confidence ball.
Lemma (pointwise width of confidence ball). Let
. Consider any
. Then,

Proof. We have

where the first inequality follows from Cauchy-Schwarx and the second (i.e last) inequality holds by the definition of 
Let us now define

which we can think of as the “normalized width” at time 
Lemma (instantaneous regret lemma). Fix
. If
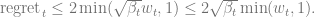
Proof. The basic idea is to use “optimism”. Let 

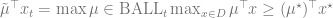


where the last step follows from the pointwise width lemma (note 
![\mu^\star \cdot x \in [-1,1]](https://s0.wp.com/latex.php?latex=%5Cmu%5E%5Cstar+%5Ccdot+x+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=666666&s=0&c=20201002)

In the next two lemmas, we use a geometric potential function argument to bound the sum of widths independently of the choices made by the algorithm (e.g. choice of 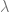
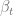
Geometric Lemma 1. We have

Proof. By definition of 

We complete the proof by noting that 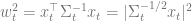
Geometric Lemma 2. For any sequence
such that for
,
, we have

Proof. Denote the eigenvalues of 
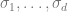
Using the AM-GM inequality,
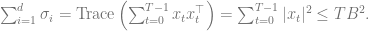

We are now finally ready to prove Lemma 2 (sum of squares regret bound).
Proof of Lemma 2 (sum of squares regret bound).
Assume 
where the first inequality follows from the instantaneous regret lemma, the second from that 
This wraps up our discussion of Lemma 2.
Analysis of Lemma 1 (Confidence bound)
Recall that our goal here is to show that 
Lemma (Self-normalized bound for vector-valued Martingalues, Abbasi et al. 2011). Suppose
are mean zero random variables (can be generalized to martingalues), and
is bounded by
. Let
be a stochastic process. Define
. With probability at least
,

Equipped with the lemma above, we are now ready to prove Lemma 1, which we will restate here again.
Lemma 1 (Confidence): Let
Proof of Lemma 1. Since 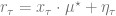

To get the last equality, we recall that 

where the last inequality holds with probability at least 



where the final inequality is a consequence of the choice 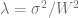
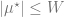

where 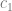
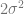
We move on now to more challenging RL problems where the horizon
Part 2: What are necessary assumptions for generalization in RL?
Approximate dynamic programming with linear function approximation
We begin by considering generalization with a very natural assumption: suppose that the value function 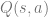

We assume that the dimension of the representation,
One natural question that arises is this: what conditions must the representation
We proceed by studying the simplest possible case: assuming that the optimal 
RL with linearly realizable function approximation: does there exist a sample efficient algorithm?
Suppose we have access to a feature map 
Assumption 1 (Linearly realizable
that there exists
such that

As an aside, with Assumption 1, we can consider the problem from a linear programming viewpoint. Note that:
- We have an underlying LP with
constraints.
- The LP is specific to the dynamic programming problem at hand (and hence not general) because it encodes the Bellman optimality constraints.
- We have sampling access (in the episodic setting).
It may be tempting to think that Assumption 1 is sufficient to enable a sample-efficient algorithm for RL (if we assume we already know the representation
Theorem 1 (Weisz, Amortila, Szepesvári 2021): There exists an MDP and a representation
samples to output the value
up to constant additive error, with probability at least 0.9.
While linear realizability alone is insufficient for sample efficiency in online RL, one might consider imposing further assumptions that could suffice for sample-efficient RL. One candidate assumption is to assume that at each state, the optimal action yields significantly more value than the next-best action:
Assumption 2 (Large suboptimality gap): Assume for all
, we have
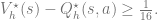
Perhaps surprisingly, the following theorem shows that an exponential lower bound for online RL remains under both Assumption 1 and Assumption 2.
Theorem 2 (Wang, Wang, Kakade 2021): There exists an MDP and a representation
Remark: We note a subtle distinction between the online RL setting and the simulator access setting. In the online RL setting, during each episode, we start at some state 


We next introduce the counterexample used to prove Theorem 2 in detail.
Construction sketch for counterexample in Theorem 2

Above, we have a pictorial representation of the MDP family in the counterexample. We first describe its state and action spaces.
- The state space is
. We use
to denote an integer, which we set to be approximately
.
- State
is a special state, which we can think of as a “terminal state”.
- At state
, the feasible action set is
. At state
. Hence, there are
feasible actions at each state.
- Each MDP in this “hard” family is specified by an index
and denoted by
.
Before we proceed, we first recall the Johnson-Lindenstrauss lemma, which states that a set of points in a high-dimensional space can be embedded into a space of much lower dimension in such a way that the distances between the points are nearly preserved.
Johnson-Lindenstrauss Lemma: Suppose we are given
, a set
of
, and a number
. Then, there is a linear map
such that

Consider a collection 


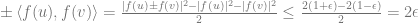
where we used the fact that 
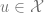
Lemma 1 (Johnson-Lindenstrauss): For any
, there exists
unit vectors
in
and
,
.
Throughout our discussion, we will set 
Equipped with the lemma above, we can now describe the transitions, features and rewards of the constructed MDP family. In the sequel, ![a_1 \in [m]](https://s0.wp.com/latex.php?latex=a_1+%5Cin+%5Bm%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![a_2 \in [m]](https://s0.wp.com/latex.php?latex=a_2+%5Cin+%5Bm%5D&bg=ffffff&fg=666666&s=0&c=20201002)
Transitions: The initial state 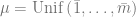
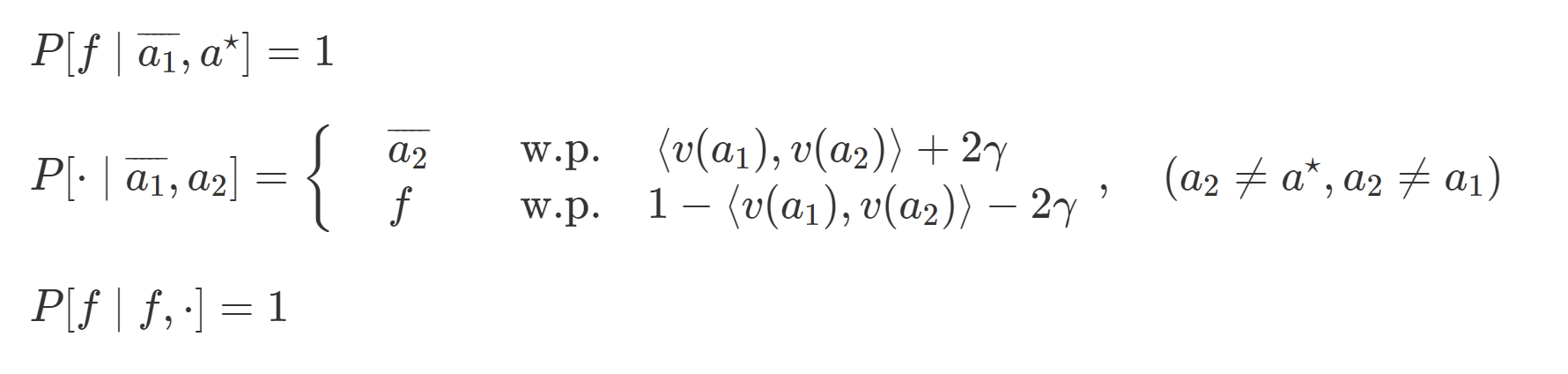
After taking action 

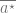

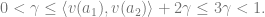
Features: The feature map, which maps state-action pairs to
![\phi(\overline{a_1},a_2) := \left(\left\langle v(a_1),v(a_2) \right\rangle + 2\gamma \right) v(a_2), \; \forall a_1,a_2 \in [m], a_1 \neq a_2](https://s0.wp.com/latex.php?latex=%5Cphi%28%5Coverline%7Ba_1%7D%2Ca_2%29+%3A%3D+%5Cleft%28%5Cleft%5Clangle+v%28a_1%29%2Cv%28a_2%29+%5Cright%5Crangle+%2B+2%5Cgamma+%5Cright%29+v%28a_2%29%2C+%5C%3B+%5Cforall+a_1%2Ca_2+%5Cin+%5Bm%5D%2C+a_1+%5Cneq+a_2&bg=ffffff&fg=666666&s=0&c=20201002)
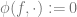
Note that the feature map is independent of 
Rewards: For 

![R_h(\overline{a_1},a_2) := -2\gamma \left[\left\langle v(a_1),v(a_2) \right\rangle + 2\gamma\right], \; (a_2 \neq a^\star, a_2 \neq a_1)](https://s0.wp.com/latex.php?latex=R_h%28%5Coverline%7Ba_1%7D%2Ca_2%29+%3A%3D+-2%5Cgamma+%5Cleft%5B%5Cleft%5Clangle+v%28a_1%29%2Cv%28a_2%29+%5Cright%5Crangle+%2B+2%5Cgamma%5Cright%5D%2C+%5C%3B+%28a_2+%5Cneq+a%5E%5Cstar%2C+a_2+%5Cneq+a_1%29&bg=ffffff&fg=666666&s=0&c=20201002)

For 

We now verify that our construction satisfies both the linear realizability and large suboptimality gap assumptions (Assumption 1 and Assumption 2).
Lemma (Linear realizability). For all
.
Proof: Throughout, we assume that 

![h \in [H]](https://s0.wp.com/latex.php?latex=h+%5Cin+%5BH%5D&bg=ffffff&fg=666666&s=0&c=20201002)


![\forall a_1 \in [m], a_2 \neq a_1](https://s0.wp.com/latex.php?latex=%5Cforall+a_1+%5Cin+%5Bm%5D%2C+a_2+%5Cneq+a_1&bg=ffffff&fg=666666&s=0&c=20201002)
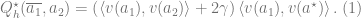
and that 

When 

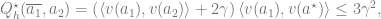
while (recall 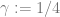
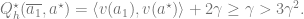
This means that proving (1) suffices to show that
We next show that the constant suboptimality gap (Assumption 2) is also (approximately) satisfied by our constructed MDP family.
Lemma (Suboptimality gap). For all state
, and
Hence, in this MDP, Assumption 2 is satisfied with.

Remark. Note that that here we ignored the terminal state 
We can now state and prove the following key technical lemma, which directly implies Theorem 2 in Wang, Wang, Kakade 2021.
Lemma. For any algorithm, there exists
with probability at least 0.1 for.

Proof sketch. We take an information-theoretic perspective. Observe that the feature map of 
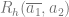


However, by the design of the transition probabilities, the probability of remaining at a non-game-over state at the next time step is at most
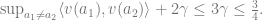
Hence, for any algorithm, 
Summarizing, any algorithm that does not know 


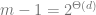

We note that our construction is not quite rigorous due to the remark earlier that the suboptimality gap assumption does not hold for the states
Open problem: Could we get a lower bound that also depends on the action space dimension
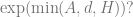
Interlude: do these lower bounds matter in practice?
A natural question to ask is this: are these exponential lower bounds in Part 2 (when we only assume linear realizability) actually relevant for practice?
To answer this, we take a brief detour into offline RL. In offline RL (see Levine et al. 2020 for a survey), we assume that the agent has no direct access to the MDP, and is instead provided with a static dataset of transitions, 





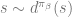

Analogous to the online RL lower bound, the following theorem shows that linear realizability is also insufficient for sample-efficient evaluation of a target policy using offline data.
Theorem (informal, from Wang, Foster, Kakade 2020)). In the offline RL setting, suppose the data distributions have (polynomially) lower bounded eigenvalues, and the
Some remarks are in order. First, note that the above hardness result for policy evaluation also holds for finding near-optimal policies using offline data. For a simple reduction, consider an example where at the initial state, one action 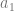
Empirical work performed in Wang et al. 2021 show that the these negative results do manifest themselves in experimental examples. The methology considered by Wang et al. 2021 is as follows:
- Decide on a target policy to be evaluated, along with a good feature mapping for this policy (could be the last layer of a deep neural network trained to evaluate the policy).
- Collect offline data using trajectories that are a mixture of the target policy and another distribution (perhaps generated by a random policy).
- Run offline RL methods to evaluate the target policy using feature mapping found in Step 1 and the offline data obtained in Step 2.
We note that features extracted from pre-trained deep neural networks should be able to satisfy the linear realizibility assumption approximately (for the target policy). Moreover, the offline dataset is relatively favorable for evaluation of the target policy, since we would not expect realistic offline datasets to have a large number of trajectories from the target policy itself.
However, numerical results show substantial degradation in the accuracy of policy evaluation, even for a relatively mild distribution shift (e.g. where there is a 50/50 split in target policy and random policy in the offline data). As an example, consider the following plot.

The figure above depicts the performance of Fitted Q-Iteration (FQI) on Walker2d-v2, an environment from the OpenAI gym benchmark suite which has continuous action space. Here, the 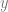
These empirical results seem to affirm the hardness results in Wang et al. 2021 (offline RL) and Wang, Wang, Kakade 2021 (online RL), in that the definition of a good representation in RL is more subtle than in supervised learning, and certainly goes beyond just linear realizibility.
Part 3: Sufficient conditions for provable generalization in RL
We have seen from Part 1 and Part 2 that finding an 
Q: What kind of assumptions enable provable generalization in RL?
In fact, under various stronger assumptions, sample-efficient generalization is possible in many special cases. Amongst others, these include
- Linear Bellman Completion [Munos 2005, Zanette et al. 2020]
- Linear MDPs (low-rank transition matrix) [Wang and Yang 2018; Jin et al. 2019]
- Linear Quadratic Regulators (LQR): standard control theory model (see e.g. Wikipedia page for LQR)
- FLAMBE/Feature Selection: Agarwal, Kakade, Krishnamurthy, Sun 2020
- Linear Mixture MDPs: [Modi et al. 2020, Ayoub et al. 2020]
- Block MDPs Du et al. 2019
- Factored MDPs Sun et al 2019
- Kernelized Nonlinear Regulator Kakade et al. 2020
What structural commonalities are shared between these underlying assumptions and models? To answer this question, we go back to the start, and revisit the case of linear bandits (
Intuition from properties satisfied by linear bandits
We consider linear contextual bandits, where the context is 



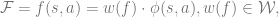
where 
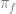

An important structural property satisfied by linear contextual bandits is the following: data reuse. Indeed, the difference between any 
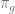

![\mathbb{E}_{(s,a) \sim \pi_g} [f(s,a) - r(s,a)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%28s%2Ca%29+%5Csim+%5Cpi_g%7D+%5Bf%28s%2Ca%29+-+r%28s%2Ca%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![= \mathbb{E}_{(s,a) \sim \pi_g} [w(f) \cdot \phi(s,a) - (w^\star \cdot \phi(s,a) + \epsilon)]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D_%7B%28s%2Ca%29+%5Csim+%5Cpi_g%7D+%5Bw%28f%29+%5Ccdot+%5Cphi%28s%2Ca%29+-+%28w%5E%5Cstar+%5Ccdot+%5Cphi%28s%2Ca%29+%2B+%5Cepsilon%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![= \left\langle w(f) - w^\star, \mathbb{E}_{(s,a) \sim \pi_g} [\phi(s,a)] \right\rangle.](https://s0.wp.com/latex.php?latex=%3D+%5Cleft%5Clangle+w%28f%29+-+w%5E%5Cstar%2C+%5Cmathbb%7BE%7D_%7B%28s%2Ca%29+%5Csim+%5Cpi_g%7D+%5B%5Cphi%28s%2Ca%29%5D+%5Cright%5Crangle.&bg=ffffff&fg=666666&s=0&c=20201002)
Intuitively, assuming that
Special case: linear Bellman complete class
Let 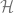
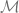
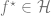
![Q_h^\star(s,a) = Q_{h}^{f^\star}(s,a) \quad \forall h \in [h],](https://s0.wp.com/latex.php?latex=Q_h%5E%5Cstar%28s%2Ca%29+%3D+Q_%7Bh%7D%5E%7Bf%5E%5Cstar%7D%28s%2Ca%29+%5Cquad+%5Cforall+h+%5Cin+%5Bh%5D%2C&bg=ffffff&fg=666666&s=0&c=20201002)
where
For any 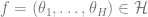

![\mathbb{E}_{s_h,a_h, s{h+1} \sim \pi_g} \left[Q_{h}^f(s_h,a_h) - r(s_h,a_h) - V_{h+1}^f(s_{h+1}) \right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bs_h%2Ca_h%2C+s%7Bh%2B1%7D+%5Csim+%5Cpi_g%7D+%5Cleft%5BQ_%7Bh%7D%5Ef%28s_h%2Ca_h%29+-+r%28s_h%2Ca_h%29+-+V_%7Bh%2B1%7D%5Ef%28s_%7Bh%2B1%7D%29+%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![= \mathbb{E}_{s_h, a_h \sim \pi_g} \left[ (\theta_h - \mathcal{T}_h(\theta{h+1}) \cdot \phi(s_h,a_h) \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D_%7Bs_h%2C+a_h+%5Csim+%5Cpi_g%7D+%5Cleft%5B+%28%5Ctheta_h+-+%5Cmathcal%7BT%7D_h%28%5Ctheta%7Bh%2B1%7D%29+%5Ccdot+%5Cphi%28s_h%2Ca_h%29+%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![= (\theta_h - \mathcal{T}h(\theta{h+1}) \cdot \mathbb{E}_{s_h, a_h \sim \pi_g} \left[ \phi(s_h,a_h) \right].](https://s0.wp.com/latex.php?latex=%3D+%28%5Ctheta_h+-+%5Cmathcal%7BT%7Dh%28%5Ctheta%7Bh%2B1%7D%29+%5Ccdot+%5Cmathbb%7BE%7D_%7Bs_h%2C+a_h+%5Csim+%5Cpi_g%7D+%5Cleft%5B+%5Cphi%28s_h%2Ca_h%29+%5Cright%5D.&bg=ffffff&fg=666666&s=0&c=20201002)
Definition (linear Bellman complete). A hypothesis class
, is linear Bellman complete for an MDP
such that for all
and
![T_h(\theta_{h+1}) \cdot \phi(s,a) = r(s,a) + \mathbb{E}_{s' \sim P_h(s,a)} \left[\max_{a' \in \mathcal{A}} \theta_{h+1}^\top \phi(s',a') \right], \quad \forall (s,a) \in \mathcal{S} \times \mathcal{A}.](https://s0.wp.com/latex.php?latex=T_h%28%5Ctheta_%7Bh%2B1%7D%29+%5Ccdot+%5Cphi%28s%2Ca%29+%3D+r%28s%2Ca%29+%2B+%5Cmathbb%7BE%7D_%7Bs%27+%5Csim+P_h%28s%2Ca%29%7D+%5Cleft%5B%5Cmax_%7Ba%27+%5Cin+%5Cmathcal%7BA%7D%7D+%5Ctheta_%7Bh%2B1%7D%5E%5Ctop+%5Cphi%28s%27%2Ca%27%29+%5Cright%5D%2C+%5Cquad+%5Cforall+%28s%2Ca%29+%5Cin+%5Cmathcal%7BS%7D+%5Ctimes+%5Cmathcal%7BA%7D.&bg=ffffff&fg=666666&s=0&c=20201002)
This shows that data reuse is possible for any linear Bellman complete class 
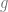
As an aside, note that linear Bellman completeness is a very strong condition that can break when new features are added. This is because adding new features expands the hypothesis space (of linear functions), and there is no guarantee that the new hypothesis class will again satisfy linear Bellman completeness.
It turns out that linear Bellman complete classes are just one example of Bilinear Classes (Du et al. 2021), which encompass many RL models in which sample-efficient generalization has been shown to be possible.
Bilinear Classes: structural properties to enable generalization in RL
We assume access to a hypothesis class 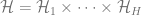

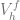




Definition (Bilinear Class). Consider an MDP 

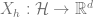
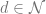
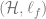
- Bilinear regret: on-policy difference between claimed reward and true reward satisfies following upper bound,
- Data reuse:
![|\mathbb{E}_{a{1:h} \sim \pi_f} \left[Q_{h}^{f}(s_h,a_h) - r(s_h,a_h) - V_{h}^{f}(s_{h+1}) \right] | \leq \langle W_h(f) - W_h(f^\star), X_h(f)\rangle.f](https://s0.wp.com/latex.php?latex=%7C%5Cmathbb%7BE%7D_%7Ba%7B1%3Ah%7D+%5Csim+%5Cpi_f%7D+%5Cleft%5BQ_%7Bh%7D%5E%7Bf%7D%28s_h%2Ca_h%29+-+r%28s_h%2Ca_h%29+-+V_%7Bh%7D%5E%7Bf%7D%28s_%7Bh%2B1%7D%29+%5Cright%5D+%7C+%5Cleq+%5Clangle+W_h%28f%29++-+W_h%28f%5E%5Cstar%29%2C+X_h%28f%29%5Crangle.f&bg=ffffff&fg=666666&s=0&c=20201002)
![|\mathbb{E}_{a{1:h} \sim \pi_f}\left[\ell_f(s_h,a_h,s_{h+1},g) \right]| = |\langle W_h(g) - W_h(f^\star), X_h(f)\rangle |.](https://s0.wp.com/latex.php?latex=%7C%5Cmathbb%7BE%7D_%7Ba%7B1%3Ah%7D+%5Csim+%5Cpi_f%7D%5Cleft%5B%5Cell_f%28s_h%2Ca_h%2Cs_%7Bh%2B1%7D%2Cg%29+%5Cright%5D%7C+%3D+%7C%5Clangle+W_h%28g%29+-+W_h%28f%5E%5Cstar%29%2C+X_h%28f%29%5Crangle+%7C.&bg=ffffff&fg=666666&s=0&c=20201002)
As an example to demonstrate what the choices of 
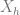


![X_h(f) = \mathbb{E}_{(s_h,a_h) \sim \pi_f}[\phi(s_h,a_h)]](https://s0.wp.com/latex.php?latex=X_h%28f%29+%3D+%5Cmathbb%7BE%7D_%7B%28s_h%2Ca_h%29+%5Csim+%5Cpi_f%7D%5B%5Cphi%28s_h%2Ca_h%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
Above, note that 
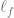
- Linear Bellman Completion [Munos 2005, Zanette et al. 2020]
- Linear MDPs (low-rank transition matrix) [Wang and Yang 2018; Jin et al. 2019]
- Linear Quadratic Regulators (LQR): standard control theory model (see e.g. Wikipedia page for LQR)
- FLAMBE/Feature Selection: Agarwal, Kakade, Krishnamurthy, Sun 2020
- Linear Mixture MDPs: [Modi et al. 2020, Ayoub et al. 2020]
- Block MDPs Du et al. 2019
- Factored MDPs Sun et al 2019
- Kernelized Nonlinear Regulator Kakade et al. 2020
- and more (see Du et al. 2021 for details.)
Bilinear classes can be seen as a generalization of Bellman rank (Jiang et al. 2017) and Witness rank (Wen et al. 2019), which were previous works that sought to identify strucural commonalities between different RL models that enable sample-efficient generalization. That being said, there are still models (with known provable generalization) which Bilinear Classes does not cover. Two such exceptions are the deterministic linear
Conclusion
From the discussion above, we see that a generalization theory for RL, while significantly distinct from that for supervised learning, is still possible. However, natural assumptions that might seem adequate, such as linear realizability, are in fact insufficient, and much stronger assumptions are required. One such example of sufficient assumptions is the Bilinear Class, which covers a rich set of models. Moreover, as the empirical results we saw in the interlude show, these representational issues identified by theory are relevant for practice. For more on the theory of RL, see the following forthcoming book.
