One of the mysteries of computation is that, as far as we can tell, the time complexity of many natural computational problems is either 

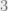



Similarly, this is why we care about hardness reductions, even when they hide huge constants or exponents: we view them as evidence that a problem is of the HARD type, and expect (as is also often the case) the efficiency of the reduction to be eventually improved.
This is also why our asymptotic theory of efficiency in informative in a finite world, and we don’t spend too much time worrying about the fact that 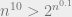

Of course there are results such as the time hierarchy theorem and Ladner’s theorem that tell us that “intermediate complexity” do exist, but the hope is that this doesn’t happen for “natural” problems.
(In particular, we can artificially create problems of complexity 
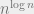
One family of natural problems are constraint satisfaction problems (CSPs). For some finite alphabet 

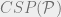

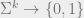
The input for 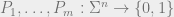
The basic task in CSPs is exact satisfiability, where the goal is to tell whether there is some assignment 

The celebrated CSP dichotomy conjecture (which perhaps should now be called a theorem) implies (in its modern, algebraic form) that for every 
The approximation problem for 
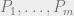
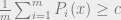
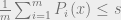
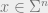

One of the most fascinating consequences of the Unique Games Conjecture is that, if it is true, then there are in fact CSPs for which their approximation is neither EASY nor HARD. That is, the Unique Games Conjecture (plus the ETH) implies the following conjecture:
Intermediate Complexity Conjecture: For every
, there exist some
and
such that
vs
approximation of
but (the potentially easier)
vs
approximation cannot be done in time
.
This is a consequence of the subexponential time algorithm for unique games, which in particular implies that for, say, 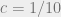

On the other hand, the Unique Games Conjecture implies that for every 
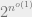
I find this conjecture very fascinating. A priori, we might expect a zero one law for CSP’s complexity, where, depending on the approximation quality, one could either solve the problem in 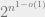
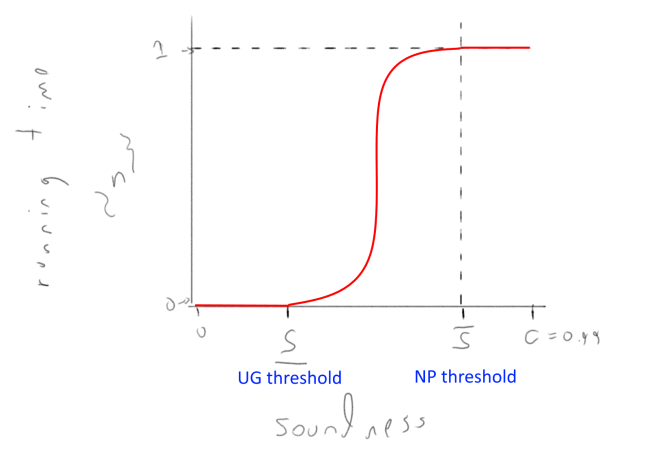
Figure 1: Conjectured time complexity of 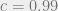


(One other setting where people were not sure if the complexity of some finitely specified object must be either exponential or polynomial is group theory, where one can define the complexity of a finitely generated group as the number of distinct elements that can be generated by a word of length $n$. There it turned out there are groups of “intermediate complexity”.)
What is also quite interesting is that we might be able to prove the intermediate complexity conjecture without resolving the UGC. In an exciting recent work, Dinur, Khot, Kindler, Minzer and Safra gave a combinatorial hypothesis that, if true, would imply the NP hardness of 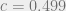
Through discussions with Pravesh Kothari and David Steurer, we showed that the DKKMS combinatorial hypothesis is equivalent to a fairly simple to state statement. Informally, it can be stated as follows: let 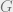

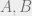



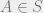
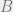

Let me state this more formally: Lets say that a subset 

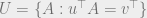

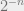

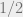
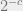
Inverse short code conjecture: For every
and
such that if
is the graph above with vertex set
and
if
, then for every
, if
then there are
such that
satisfies
.
I call this an “inverse conjecture” since it is aimed at characterizing the sets
I find it a natural question, though have to admit that, despite thinking about it some time (and also talking about it, not just with David and Pravesh but also Irit Dinur, Shachar Lovett and Kaave Hoesseini) I still don’t have a strong intuition whether it’s false or true.
Given that the short code graph is a Cayley graph over the Boolean cube, this seems like a question that could be amenable to tools from Fourier analysis and additive combinatorics.
Some partial progress has been made by the DKKMS folks in their new manuscript.
In fact, the same observations show that their original hypothesis is also equivalent not just to the “inverse short code conjecture” but also to Hypothesis 1.7 in this report, which is an analogous “inverse conjecture” for the Grassmanian graph where, for 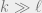
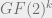


Nevertheless, at the moment this question is still wide open, and I hope this writeup encourages more people to work on it. Other than resolving this question, there are some other interesting research directions, including:
- The DKKMS reduction combined with the Grigoriev 3XOR instance yields a concrete candidate sum-of-squares integrality gap for, say,
vs
unique games. By construction, the SOS value of this instance is
, but is analyzing the soundness of this instance easier than the general case?
-
The underlying building block for DKKMS is a problem known as a smooth label cover. This is not precisely a CSP, but can we show that it has intermediate complexity? i.e., give a subexponential time algorithm for it? If the DKKMS hypothesis is correct then we know that such an algorithm should be an SDP hierarchy.
-
Suppose the combinatorial hypothesis is true, is there an inherent reason why its proof should not be a low degree SOS proof? After all, related isoperimetric results on the short code graph have been shown by low degree SOS proofs. Also, is the proof of the current best bounds coming from the DKKMS manuscript SOS-izable?
-
The quantiative bounds for the DKKMS reduction are terrible. I haven’t worked out all the details but it seems that the reduction from 3XOR to
(or maybe even
) size. Is this inherent?
-
Is there a general conjecture that would predict for
what should be the time complexity of
vs
approximation for it? We have some approaches of trying to predict when the complexity should be
time would have something to do with defining a suitable notion of “$(1+\epsilon)$-wise independent distributions” perhaps via concepts of mutual information. For example, perhaps we can argue that a smooth label cover is a
-wise independent CSP to a certain extent.

The graph G that you mention is the “bilinear graph”, connecting points at distance 1 in the bilinear association scheme (over GF(2)) with appropriate parameters. This algebraic structure has been studied by coding theorists such as Delsarte, and in particular its eigenstructure is well understood.
Thanks! I didn’t know about this name.
Yes, given that it’s a Cayley graph over the cube we know all its eigenvalues and eigenvectors. The question is however whether the eigenvectors corresponding to non-trivial eigenvalues (which would correspond to the Fourier characters of matrices of constant rank) can span functions that are close to the characteristic function of a set that’s not close to a union of intersection of a constant number of those “basic sets”.